- Research Article
- Open access
- Published:
Optimized Projection Matrix for Compressive Sensing
EURASIP Journal on Advances in Signal Processing volume 2010, Article number: 560349 (2010)
Abstract
Compressive sensing (CS) is mainly concerned with low-coherence pairs, since the number of samples needed to recover the signal is proportional to the mutual coherence between projection matrix and sparsifying matrix. Until now, papers on CS always assume the projection matrix to be a random matrix. In this paper, aiming at minimizing the mutual coherence, a method is proposed to optimize the projection matrix. This method is based on equiangular tight frame (ETF) design because an ETF has minimum coherence. It is impossible to solve the problem exactly because of the complexity. Therefore, an alternating minimization type method is used to find a feasible solution. The optimally designed projection matrix can further reduce the necessary number of samples for recovery or improve the recovery accuracy. The proposed method demonstrates better performance than conventional optimization methods, which brings benefits to both basis pursuit and orthogonal matching pursuit.
1. Introduction
Compressive sensing (CS) [1–3] has received much attention as it has shown promising results in many applications. CS is an emerging framework, stating that signals which have a sparse representation on an appropriate basis can be recovered from a number of random linear projections of dimension considerably lower than that required by the Shannon-Nyquist theorem. Moreover, compressible signals, that is, the signals' transform coefficients on appropriate basis decay rapidly, can also be sampled at a much lower rate than that required by the Shannon-Nyquist theorem and then reconstructed with little loss of information.
Consider a signal  which can be sparsely represented over a fixed dictionary
which can be sparsely represented over a fixed dictionary  that is assumed to be redundant
that is assumed to be redundant  . Accordingly, the signal can be described as
. Accordingly, the signal can be described as

where  is the coefficient vector which represents
is the coefficient vector which represents  on
on  and
and  . The
. The  norm used here simply counts the number of nonzero element in
norm used here simply counts the number of nonzero element in  .
.
CS is an innovative and revolutionary idea that offers a joint sampling and compressing process for such signal. Consider a general linear sampling process which computes  inner products between
inner products between  and a collection of vectors
and a collection of vectors  as
as  . Arrange the measurements
. Arrange the measurements  in an
in an  vector
vector  and the sampling vectors
and the sampling vectors  as rows in an
as rows in an  matrix
matrix  , then
, then  can be written as
can be written as

The original  can be reconstructed from
can be reconstructed from  by exploring its sparse expression, that is, among all possible
by exploring its sparse expression, that is, among all possible  that satisfies
that satisfies  , seek the sparsest. If this representation coincides with
, seek the sparsest. If this representation coincides with  , a perfect reconstruction of the signal in (1) is gotten. This reconstruction requires the solution of
, a perfect reconstruction of the signal in (1) is gotten. This reconstruction requires the solution of

where  is defined as the equivalent dictionary.
is defined as the equivalent dictionary.
It is known to be NP-hard in general to solve the problem [4] and different suboptimal strategies are used in practice such as Basis Pursuit (BP) [3] and Orthogonal Matching Pursuit (OMP) [5, 6].
Until now, almost all works on CS made the assumption that  is drawn at random except the one by Elad [7] and the one by Duarte-Carvajalino and Sapiro [8]. In [7], Elad proposed an iterative algorithm. The algorithm tries to minimize the
is drawn at random except the one by Elad [7] and the one by Duarte-Carvajalino and Sapiro [8]. In [7], Elad proposed an iterative algorithm. The algorithm tries to minimize the  -averaged mutual coherence between
-averaged mutual coherence between  and
and  , where
, where  is fixed. Although the reconstruction performance can be obviously improved, the method is time-consuming because it needs many iterative steps to achieve good performance. Some large mutual coherence values that are not present in the original Gram matrix are also created, which ruin completely the worst case guarantees of the reconstruction algorithms. Instead of targeting on the
is fixed. Although the reconstruction performance can be obviously improved, the method is time-consuming because it needs many iterative steps to achieve good performance. Some large mutual coherence values that are not present in the original Gram matrix are also created, which ruin completely the worst case guarantees of the reconstruction algorithms. Instead of targeting on the  -averaged mutual coherence between
-averaged mutual coherence between  and
and  , in [8], Duarte-Carvajalino and Sapiro addressed the problem by making any subset columns of
, in [8], Duarte-Carvajalino and Sapiro addressed the problem by making any subset columns of  as orthogonal as possible, or equivalently, making the Gram matrix as closely as possible to identity matrix. The method is much faster than Elad's but the reconstruction performance is not very good because
as orthogonal as possible, or equivalently, making the Gram matrix as closely as possible to identity matrix. The method is much faster than Elad's but the reconstruction performance is not very good because  is overcomplete and it could not be an orthogonal basis.
is overcomplete and it could not be an orthogonal basis.
In this paper, a method to optimize the projection matrix is proposed from the perspective of ETF design [9]. The object is to find an equivalent dictionary whose Gram matrix is as close as possible to an ETF's because an ETF has minimum coherence [10]. It is impossible to find an exact solution so an alternating minimization type method is used to find a feasible solution. The proposed method needs few iterative steps to achieve good performance and the reconstruction performance is much better than the existed methods, with both BP and OMP.
The remainder of the paper is organized as follows. In Section 2, the basics of CS are provided along with a statement of the main results in literature relating to this paper. In Section 3, after briefly describing the methods suggested by Elad and Duarte-Carvajalino and Sapiro, a method to optimize the projection matrix is proposed from the aspect of ETF design and an alternative minimization method is proposed to solve the problem. In Section 4, experimental results are presented and the performance obtained with all the optimization methods is compared. Finally, concluding remarks and directions for future research are presented in Section 5.
2. Compressive Sensing: The Basics
CS relies on two fundamental premises: sparsity and incoherence. Sparsity means, in (1), most elements of  are zero or they can be discarded without much loss of information. Incoherence means, in (2), the projection matrix
are zero or they can be discarded without much loss of information. Incoherence means, in (2), the projection matrix  and the sparsifying matrix
and the sparsifying matrix  should be as incoherent as possible. A possible measure of coherence between
should be as incoherent as possible. A possible measure of coherence between  and
and  is given by the inner products of different columns in
is given by the inner products of different columns in  [11, 12]:
[11, 12]:

A different way to measure mutual coherence is considering the Gram matrix of equivalent dictionary  which is computed after normalizing each column of
which is computed after normalizing each column of  . The off-diagonal entries of
. The off-diagonal entries of  are the inner products that appear in (4). Mutual coherence is the off-diagonal entry with largest magnitude.
are the inner products that appear in (4). Mutual coherence is the off-diagonal entry with largest magnitude.
Mutual coherence measures the maximal correlation between both matrix elements and plays an important role in the success of reconstruction algorithm. It has been demonstrated that mutual coherence should be as small as possible in CS [2].
Theorem 1.
The necessary number of samples needed to recover signal is confined by

where  is a positive constant,
is a positive constant,  is the sparsity level of signal, and
is the sparsity level of signal, and  is the dimension. It is obvious to see that the smaller the coherence, the fewer samples are needed [2].
is the dimension. It is obvious to see that the smaller the coherence, the fewer samples are needed [2].
Theorem 2.
If the flowing inequality holds,

then,  is necessary the sparsest solution such that
is necessary the sparsest solution such that  and the reconstruction algorithms are guaranteed to succeed in finding the correct
and the reconstruction algorithms are guaranteed to succeed in finding the correct  [13–15].
[13–15].
From the former discussion, it is easy to see that CS deals with the case of low coherence between  and
and  . With the properties of
. With the properties of  , there is a sensible reason to design the projection matrix in a way that minimizes the mutual coherence
, there is a sensible reason to design the projection matrix in a way that minimizes the mutual coherence  which may lead to better performance of reconstruction algorithms.
which may lead to better performance of reconstruction algorithms.
3. Optimizing Projection Matrix for Compressive Sensing
In this paper, only the case that  is fixed while
is fixed while  can be arbitrary is considered. Hence, the object is to optimize
can be arbitrary is considered. Hence, the object is to optimize  that will minimize the mutual coherence
that will minimize the mutual coherence  . After reviewing the former related work, the proposed algorithm is introduced.
. After reviewing the former related work, the proposed algorithm is introduced.
3.1. Elad's Method [7]
Instead of mutual coherence, Elad considered a different coherence— -averaged mutual coherence which reflects the average behavior. The
-averaged mutual coherence which reflects the average behavior. The  -averaged mutual coherence of
-averaged mutual coherence of  is defined as the average of all absolute and normalized inner products between different columns in
is defined as the average of all absolute and normalized inner products between different columns in  (denoted as
(denoted as  ) that are above
) that are above  . Formally
. Formally

Putting very simply, the object is to minimize  with respect to
with respect to  , assuming that
, assuming that  and the parameter
and the parameter  are fixed and known. In this algorithm, the main object is the reduction of the absolute inner products
are fixed and known. In this algorithm, the main object is the reduction of the absolute inner products  that are above
that are above  . The Gram matrix of the normalized equivalent dictionary is computed and the values above
. The Gram matrix of the normalized equivalent dictionary is computed and the values above  are "shrinked" by multiplying with
are "shrinked" by multiplying with  . In order to preserve the order of the absolute values in the Gram matrix, entries in
. In order to preserve the order of the absolute values in the Gram matrix, entries in  with magnitude below
with magnitude below  but above
but above  are "shrinked" by a small amount using the following function:
are "shrinked" by a small amount using the following function:

The former shrinking operation causes the resulting Gram matrix to become full rank in general case. Thus, the next steps should mend this by forcing the rank to be  and find the matrix
and find the matrix  that could best describe the squared root of the obtained Gram matrix. The process could be realized using SVD. The details can be found in [7].
that could best describe the squared root of the obtained Gram matrix. The process could be realized using SVD. The details can be found in [7].
3.2. Duarte-Carvajalino and Sapiro's Method
Unlike the previous one, Duarte-Carvajalino and Sapiro's method is noniterative. Instead of targeting on  -averaged mutual coherence between
-averaged mutual coherence between  and
and  , this method addressed the problem by making any subset of columns in
, this method addressed the problem by making any subset of columns in  as orthogonal as possible, or equivalently, making the Gram matrix as close as possible to an identity matrix. Their approach was carried out as follows.
as orthogonal as possible, or equivalently, making the Gram matrix as close as possible to an identity matrix. Their approach was carried out as follows.
Consider the Gram matrix of the equivalent dictionary

The object is to find such  that makes the Gram matrix as close as possible to identity matrix
that makes the Gram matrix as close as possible to identity matrix

Multiplying both sides of (10) with  on the left and
on the left and  on the right, it becomes
on the right, it becomes

Now, consider the eigen-decomposition of  which is
which is

Then (11) becomes

which is equivalent to

By denoting  , they finally formulated the problem to minimize the following function with respect to
, they finally formulated the problem to minimize the following function with respect to  :
:

By solving the problem of (15), they achieved to optimize the projection matrix. The details to solve the problem can be found in [8].
3.3. The Proposed Method
Elad's method is time-consuming and the shrinkage function creates some large values that are not present in the original Gram matrix. Large off-diagonal values in the Gram matrix ruin completely the worst case guarantees of the reconstruction algorithms. Duarte-Carvajalino and Sapiro's method is noniterative and the reconstruction relative error rate is high. To overcome these drawbacks, a method based on ETF design is proposed in this paper. The object is to find an equivalent dictionary which is as close as possible to an ETF because of the minimum coherence property of ETF, and then from the equivalent dictionary, the optimized projection matrix can be constructed. It is impossible to solve the problem exactly because of the complexity, so an alternative minimization type method is used to find a feasible solution.
Firstly, model the problem as an optimization problem. Let  be the Gram matrix of
be the Gram matrix of  . The mutual coherence of
. The mutual coherence of  is the maximum absolute value of the off-diagonal entry of
is the maximum absolute value of the off-diagonal entry of  , supposing the columns of
, supposing the columns of  are normalized. For such
are normalized. For such  , if the magnitudes of all off-diagonal entries of
, if the magnitudes of all off-diagonal entries of  are equal,
are equal,  has minimum coherence [10]. This normalized dictionary is called an ETF. Although this type of frame has many nice properties, ETF does not exist for any arbitrary selection of dimension. Therefore the optimization process aims at finding the nearest admissible solution which is as close as possible to an ETF.
has minimum coherence [10]. This normalized dictionary is called an ETF. Although this type of frame has many nice properties, ETF does not exist for any arbitrary selection of dimension. Therefore the optimization process aims at finding the nearest admissible solution which is as close as possible to an ETF.
For the normalized equivalent dictionary  , the mutual coherence of
, the mutual coherence of  is defined as
is defined as

A column normalized dictionary  is called ETF when there is a constant
is called ETF when there is a constant  that
that

Strohmer and Heath Jr. in [16] showed that if there is an ETF in the set of  uniform frames, it is the solution of
uniform frames, it is the solution of

To study the lower bound of  , the existence of an ETF and its Gram matrix, Strohmer showed that
, the existence of an ETF and its Gram matrix, Strohmer showed that  is lower bounded by
is lower bounded by

Let  be the set of Gram matrices of all
be the set of Gram matrices of all  ETF. If
ETF. If  , then the diagonal elements and the absolute values of the off-diagonal elements of
, then the diagonal elements and the absolute values of the off-diagonal elements of  are one and
are one and  , respectively. A nearness measure of
, respectively. A nearness measure of  to the set of ETF can be defined as the minimum distance between the Gram matrix of
to the set of ETF can be defined as the minimum distance between the Gram matrix of  and
and  . To minimize the distance of a dictionary to ETF, it needs to solve
. To minimize the distance of a dictionary to ETF, it needs to solve

The matrix operator  is defined as the maximum absolute value of the elements in the matrix. Instead, it is better to use a different norm space which simplifies the problem. An advantage of using
is defined as the maximum absolute value of the elements in the matrix. Instead, it is better to use a different norm space which simplifies the problem. An advantage of using  in the given problem is that it considers the errors of all elements. Therefore it forms the following formulation:
in the given problem is that it considers the errors of all elements. Therefore it forms the following formulation:

where  is Frobenius norm. This is a nonconvex optimization problem in general. It might have a set of solutions or have no solution. Extend
is Frobenius norm. This is a nonconvex optimization problem in general. It might have a set of solutions or have no solution. Extend  to a convex set
to a convex set  , which is not empty for any
, which is not empty for any  ,
,

Relaxing (21) by replacing  with
with  , it gives the following optimization problem:
, it gives the following optimization problem:

A standard method to solve (23) is alternating projection [17]. In this work, a different method which has similarities with alternating projection is used. Although the proposed solution has similarities with alternating projection, it does not follow its steps exactly. The difference lies in the stage of updating the current solution with respect to  . A point between the current solution and the projection on
. A point between the current solution and the projection on  is chosen, that is because after being projected onto
is chosen, that is because after being projected onto  , the structure of the Gram matrix changes significantly and the selection of a new point in the following step is very difficult. After performing alternating minimization, the optimized projection matrix can be constructed from the output Gram matrix with a rank revealing QR factorization with eigenvalue decomposition. The details can be found in [18].
, the structure of the Gram matrix changes significantly and the selection of a new point in the following step is very difficult. After performing alternating minimization, the optimized projection matrix can be constructed from the output Gram matrix with a rank revealing QR factorization with eigenvalue decomposition. The details can be found in [18].
The conditions under which the algorithm converges can be found in [17].
The following are the steps of the proposed algorithm for optimizing the projection matrix, supposing the sparsifying matrix is known.
()Initialize: the projection matrix  , sparsifying matrix
, sparsifying matrix  , and equivalent dictionary
, and equivalent dictionary  , iterative steps
, iterative steps 
For 
()Compute the Gram matrix  , denote the element of
, denote the element of  as
as 
()Project the Gram matrix onto  , that is,
, that is,

()Choose a point between the current solution and the projection on  to update the Gram matrix
to update the Gram matrix

()Update the projection matrix  using QR factorization with eigenvalue decomposition
using QR factorization with eigenvalue decomposition
end
4. Experiment Results
Firstly, the distribution change of inner products between different columns of  before and after optimization is considered. Figure 1 presents the distribution of the off-diagonal elements of the Gram matrix in absolute value, obtained using a fixed sparsifying matrix for four different projection matrices. The four projection matrices considered are listed as follows: a Gaussian random matrix and the matrices obtained by the three optimization methods mentioned above. All the three optimization methods try to reduce the largest off-diagonal elements in the Gram matrix. However, Elad's method always presents a consistent artifact, where some off-diagonal elements in the Gram matrix actually increase their values, which ruin completely the performance of reconstruction algorithm. Both the method proposed in [8] and our proposed algorithm reduce the number of large absolute values in the Gram matrix. But in our proposed method, the absolute values concentrate around
before and after optimization is considered. Figure 1 presents the distribution of the off-diagonal elements of the Gram matrix in absolute value, obtained using a fixed sparsifying matrix for four different projection matrices. The four projection matrices considered are listed as follows: a Gaussian random matrix and the matrices obtained by the three optimization methods mentioned above. All the three optimization methods try to reduce the largest off-diagonal elements in the Gram matrix. However, Elad's method always presents a consistent artifact, where some off-diagonal elements in the Gram matrix actually increase their values, which ruin completely the performance of reconstruction algorithm. Both the method proposed in [8] and our proposed algorithm reduce the number of large absolute values in the Gram matrix. But in our proposed method, the absolute values concentrate around  which can make the equivalent dictionary as close as possible to an ETF. This better behavior can further reduce the necessary samples for recovery and improve the recovery performance.
which can make the equivalent dictionary as close as possible to an ETF. This better behavior can further reduce the necessary samples for recovery and improve the recovery performance.

Histogram of off-diagonal absolute values of
 before and after optimization.
before and after optimization.
Then, the performance of recovery algorithm in CS is evaluated before and after projection matrix optimization. In order to compare the performance, the test proposed by Elad in [7] is used. The test includes the following steps.
Step 1  .
.
Generate data: choose a dictionary  and synthesize
and synthesize  test signals
test signals  by generating
by generating  sparse vectors
sparse vectors  of length
of length  each, and computing for all
each, and computing for all  . All representations are built using the same cardinality
. All representations are built using the same cardinality  .
.
Step 2  .
.
Initial projection: for a chosen number of measurement  , create a random projection matrix
, create a random projection matrix  and apply it to the signals, obtaining
and apply it to the signals, obtaining  , for all
, for all  , Compute the equivalent dictionary
, Compute the equivalent dictionary  .
.
Step 3  .
.
Performance test: apply BP and OMP to reconstruct the signals by approximating the solution of  subject to
subject to  . Test the error
. Test the error  . Measure the average error rate—a reconstructionwith a mean squared error above some threshold is considered as a reconstruction failure.
. Measure the average error rate—a reconstructionwith a mean squared error above some threshold is considered as a reconstruction failure.
Step 4  .
.
Optimize the projection matrix: use the three methods mentioned above to optimize the projection matrix.
Step 
Reapply Steps 2 and 3 using the optimized projection matrix.
The following experiments followed the previously described steps. Figures 2 and 3 show the performance of CS before and after the projection matrix optimization using different optimization methods, with both OMP and BP for varying number of measurements.

CS relative errors as function of the number of measurements using OMP.

CS relative errors as function of the number of measurements using BP.
In the first experiment (Figures 2 and 3), a random dictionary of size  was used. This size was chosen since it enabled the CS performance evaluation in reasonable time.
was used. This size was chosen since it enabled the CS performance evaluation in reasonable time.  sparse vectors were generated of length
sparse vectors were generated of length  with cardinality
with cardinality  . The nonzero's locations were chosen at random. These sparse vectors were used to create the test signals with which the CS performance was evaluated. CS performance was tested with varying values of
. The nonzero's locations were chosen at random. These sparse vectors were used to create the test signals with which the CS performance was evaluated. CS performance was tested with varying values of  . The relative error rate was evaluated as a function of
. The relative error rate was evaluated as a function of  for both OMP and BP before and after the optimization. Each point in the graph represents an average performance, accumulated over a possible varying number of experiments. While every point was supposed to present an average performance over
for both OMP and BP before and after the optimization. Each point in the graph represents an average performance, accumulated over a possible varying number of experiments. While every point was supposed to present an average performance over  signals, in cases where more than 300 errors was accumulated, the test stopped and the average so far was used instead. This was done to reduce the overall runtime.
signals, in cases where more than 300 errors was accumulated, the test stopped and the average so far was used instead. This was done to reduce the overall runtime.
From Figures 2 and 3, the CS performance improves for both BP and OMP as  increases and in this experiment, BP outperforms OMP. Also, as expected, all the optimization methods lead to improved performance of CS. For some values of
increases and in this experiment, BP outperforms OMP. Also, as expected, all the optimization methods lead to improved performance of CS. For some values of  , the performance is improved by 10 : 1 for BP and 100 : 1 for OMP. The optimization method proposed by us outperforms both Elad's method and Duarte-Carvajalino and Sapiro's method. For some values of
, the performance is improved by 10 : 1 for BP and 100 : 1 for OMP. The optimization method proposed by us outperforms both Elad's method and Duarte-Carvajalino and Sapiro's method. For some values of  , our method improves the CS performance by 5 : 1 than Elad's method and even 10 : 1 than Duarte-Carvajalino and Sapiro's method for OMP. The improvement for BP is smaller than OMP, about 2 : 1 for some values of
, our method improves the CS performance by 5 : 1 than Elad's method and even 10 : 1 than Duarte-Carvajalino and Sapiro's method for OMP. The improvement for BP is smaller than OMP, about 2 : 1 for some values of  .
.
The second experiment is almost the same as the last one, but  was fixed and
was fixed and  was changeable. From Figures 4 and 5, the CS performance decreases for both BP and OMP as
was changeable. From Figures 4 and 5, the CS performance decreases for both BP and OMP as  increases. That is because as
increases. That is because as  increases, more measurements are needed to achieve the same CS performance. Also, as expected, the CS performance is improved after using the optimization methods mentioned above with both BP and OMP. The improvement is much larger with OMP than that with BP. It is almost 100 : 1 for some values of
increases, more measurements are needed to achieve the same CS performance. Also, as expected, the CS performance is improved after using the optimization methods mentioned above with both BP and OMP. The improvement is much larger with OMP than that with BP. It is almost 100 : 1 for some values of  with OMP. The CS performance is obviously improved using the proposed optimization method than both Elad's method and Duarte-Carvajalino and Sapiro's method. It is about 4 : 1 to Elad's method with OMP. With respect to BP, when
with OMP. The CS performance is obviously improved using the proposed optimization method than both Elad's method and Duarte-Carvajalino and Sapiro's method. It is about 4 : 1 to Elad's method with OMP. With respect to BP, when  is small, the improvement is larger and when
is small, the improvement is larger and when  increases, the CS performance is almost the same for all the optimization methods.
increases, the CS performance is almost the same for all the optimization methods.

CS relative errors as function of signal cardinality using OMP.

CS relative errors as function of signal cardinality using BP.
In the following experiment, the effect of signal dimension on CS performance before and after optimization of the projection matrix is considered. In this experiment, the signals' dimension  was varied while proportionally updating measurements
was varied while proportionally updating measurements  , dictionary dimension
, dictionary dimension  and signal cardinality
and signal cardinality  with it. The object was to get a better indication to the asymptotic performance as studied in [1–3].
with it. The object was to get a better indication to the asymptotic performance as studied in [1–3].
From the results in Figures 6 and 7, there is an insistent improvement before and after optimization with both BP and OMP. It is also obvious that there is great performance improvement using the optimization method proposed by us.

Relative errors as function of signal's dimension
 using BP.
using BP.

Relative errors as function of signal's dimension
 using OMP.
using OMP.

Recovered image before and after optimization. (a) Recovered using random  , (b) recovered using optimized
, (b) recovered using optimized  by Elad's method, and (c) recovered using optimized
by Elad's method, and (c) recovered using optimized  by our proposed method.
by our proposed method.
Afterwards, a test image was used to assess the recovery algorithm performance in CS before and after optimizing the projection matrix. The testing image consists of non-overlapping  patches reconstructed from their noisy projections (5% level of noise).
patches reconstructed from their noisy projections (5% level of noise).
In this experiment,  is set to be 15 and the sparsifying matrix to be DCT. The reconstruction algorithm used is OMP. From the pictures above, it is obvious to see that the recovery performance is improved for both the optimization methods. The Elad's method can improve PSNR about 1 db than using random
is set to be 15 and the sparsifying matrix to be DCT. The reconstruction algorithm used is OMP. From the pictures above, it is obvious to see that the recovery performance is improved for both the optimization methods. The Elad's method can improve PSNR about 1 db than using random  , and the proposed method in this paper can improve about 0.5 db than Elad's method. If larger number of measurements is used for recovery, the reconstruction performance could be better, but it is time-consuming.
, and the proposed method in this paper can improve about 0.5 db than Elad's method. If larger number of measurements is used for recovery, the reconstruction performance could be better, but it is time-consuming.
5. Conclusion
A crucial ingredient in the deployment of the CS idea is the process of random linear projections that mix the signal. This operation has been traditionally chosen as a random matrix. This paper aimed to show that the optimally designed projection matrix can further improve the CS performance. The method was that constructing the projection matrix so as to minimize the coherence between  and
and  based on ETF design. The experimental results demonstrated that the optimally designed projection matrix indeed lead to a better CS performance, not only improvement of the reconstruction accuracy but also reduction in the necessary number of samples for recovery. It also demonstrated that after optimizing the projection matrix using the proposed method, the CS performance was greatly improved than using random projection matrix and the already existed optimization methods.
based on ETF design. The experimental results demonstrated that the optimally designed projection matrix indeed lead to a better CS performance, not only improvement of the reconstruction accuracy but also reduction in the necessary number of samples for recovery. It also demonstrated that after optimizing the projection matrix using the proposed method, the CS performance was greatly improved than using random projection matrix and the already existed optimization methods.
As this is only one of the very few works to address the problem of optimization the projection matrix, there is still great work to do. Here are some advices for future research. ( ) How to perform the proposed method when the signals are of high dimension. (
) How to perform the proposed method when the signals are of high dimension. ( ) Whether there is a more direct method to address the problem which may be easier.
) Whether there is a more direct method to address the problem which may be easier.
References
Candes EJ, Romberg J, Tao T: Robust uncertainty principles: exact signal reconstruction from highly incomplete frequency information. IEEE Transactions on Information Theory 2006, 52(2):489-509.
Candes EJ, Wakin MB: An introduction to compressive sampling. IEEE Signal Processing Magazine 2008, 25(2):21-30.
Donoho DL: Compressed sensing. IEEE Transactions on Information Theory 2006, 52(4):1289-1306.
Natarajan BK: Sparse approximate solutions to linear systems. SIAM Journal on Computing 1995, 24(2):227-234. 10.1137/S0097539792240406
Pati YC, Rezaiifar R, Krishnaprasad PS: Orthogonal matching pursuit: recursive function approximation with applications to wavelet decomposition. Proceedings of the 27th Asilomar Conference on Signals, Systems & Computers, November 1993 40-44.
Tropp JA, Gilbert AC: Signal recovery from random measurements via orthogonal matching pursuit. IEEE Transactions on Information Theory 2007, 53(12):4655-4666.
Elad M: Optimized projections for compressed sensing. IEEE Transactions on Signal Processing 2007, 55(12):5695-5702.
Duarte-Carvajalino JM, Sapiro G: Learning to sense sparse signals: simultaneous sensing matrix and sparsifying dictionary optimization. IEEE Transactions on Image Processing 2009, 18(7):1395-1408.
Sustik MA, Tropp JA, Dhillon IS, Heath RW Jr.: On the existence of equiangular tight frames. Linear Algebra and Its Applications 2007, 426(2-3):619-635. 10.1016/j.laa.2007.05.043
Sardy S, Bruce AG, Tseng P: Block coordinate relaxation methods for nonparametric wavelet denoising. Journal of Computational and Graphical Statistics 2000, 9(2):361-379. 10.2307/1390659
Gribonval R, Nielsen M: Sparse representations in unions of bases. IEEE Transactions on Information Theory 2003, 49(12):3320-3325. 10.1109/TIT.2003.820031
Mallat SG, Zhang Z: Matching pursuits with time-frequency dictionaries. IEEE Transactions on Signal Processing 1993, 41(12):3397-3415. 10.1109/78.258082
Tropp JA: Greed is good: algorithmic results for sparse approximation. IEEE Transactions on Information Theory 2004, 50(10):2231-2242. 10.1109/TIT.2004.834793
Donoho DL, Elad M:Optimally sparse representation in general (nonorthogonal) dictionaries via
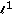 minimization. Proceedings of the National Academy of Sciences of the United States of America 2003, 100(5):2197-2202. 10.1073/pnas.0437847100
minimization. Proceedings of the National Academy of Sciences of the United States of America 2003, 100(5):2197-2202. 10.1073/pnas.0437847100Chen SS, Donoho DL, Saunders MA: Atomic decomposition by basis pursuit. SIAM Journal of Scientific Computing 1998, 20(1):33-61. 10.1137/S1064827596304010
Strohmer T, Heath RW Jr.: Grassmannian frames with applications to coding and communication. Applied and Computational Harmonic Analysis 2003, 14(3):257-275. 10.1016/S1063-5203(03)00023-X
Golub GH, Van Loan CF: Matrix Computation. Johns Hopkins University Press, Baltimore, Md, USA; 1996.
Tropp JA, Dhillon IS, Heath RW Jr., Strohmer T: Designing structured tight frames via an alternating projection method. IEEE Transactions on Information Theory 2005, 51(1):188-209.
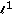 minimization. Proceedings of the National Academy of Sciences of the United States of America 2003, 100(5):2197-2202. 10.1073/pnas.0437847100
minimization. Proceedings of the National Academy of Sciences of the United States of America 2003, 100(5):2197-2202. 10.1073/pnas.0437847100Acknowledgment
Supported by the Fundamental Research Funds for the Central Universities China.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License (https://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Xu, J., Pi, Y. & Cao, Z. Optimized Projection Matrix for Compressive Sensing. EURASIP J. Adv. Signal Process. 2010, 560349 (2010). https://doi.org/10.1155/2010/560349
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1155/2010/560349