- Research Article
- Open access
- Published:
Stereoscopic Visual Attention-Based Regional Bit Allocation Optimization for Multiview Video Coding
EURASIP Journal on Advances in Signal Processing volume 2010, Article number: 848713 (2010)
Abstract
We propose a Stereoscopic Visual Attention- (SVA-) based regional bit allocation optimization for Multiview Video Coding (MVC) by the exploiting visual redundancies from human perceptions. We propose a novel SVA model, where multiple perceptual stimuli including depth, motion, intensity, color, and orientation contrast are utilized, to simulate the visual attention mechanisms of human visual system with stereoscopic perception. Then, a semantic region-of-interest (ROI) is extracted based on the saliency maps of SVA. Both objective and subjective evaluations of extracted ROIs indicated that the proposed SVA model based on ROI extraction scheme outperforms the schemes only using spatial or/and temporal visual attention clues. Finally, by using the extracted SVA-based ROIs, a regional bit allocation optimization scheme is presented to allocate more bits on SVA-based ROIs for high image quality and fewer bits on background regions for efficient compression purpose. Experimental results on MVC show that the proposed regional bit allocation algorithm can achieve over  % bit-rate saving while maintaining the subjective image quality. Meanwhile, the image quality of ROIs is improved by
% bit-rate saving while maintaining the subjective image quality. Meanwhile, the image quality of ROIs is improved by  dB at the cost of insensitive image quality degradation of the background image.
dB at the cost of insensitive image quality degradation of the background image.
1. Introduction
Three-Dimensional Video (3DV) provides Three-Dimensional (3D) depth impression and allows users to freely choose a view of a visual scene [1]. With these features, it would allow many multimedia applications, such as photorealistic rendering of 3D scenes, free viewpoint television [2], 3D television broadcasting, and 3D games, to introduce new and exciting features for users. Multiview video plus depth [3] supports high image quality and low complexity of rendering a continuum of output views. It has been the main representation of 3D scene and applied to many multiview multimedia applications. However, multiview video requires huge amount of storage and transmission bandwidth which are multiples of traditional monoview video. Thus, it is necessary to develop efficient Multiview Video Coding (MVC) algorithms for practical uses.
MVC had been studied on the basis of several video coding standards, including MPEG-2, MPEG-4, H.263, and H.264. Since the Moving Picture Experts Group (MPEG) had recognized the importance of MVC technologies, an Ad Hoc Group (AHG) on 3D Audio and Visual (3DAV) was established. The MPEG surveyed some MVC schemes, such as "Group-of-GOP prediction (GoGOP)", "sequential view prediction", and "checkerboard decomposition", [4]. Yea and Vetro proposed a view synthesis prediction-based MVC scheme for improving interview compression efficiency [5]. Yun et al. developed an efficient MVC algorithm which adaptively selects optimal prediction structure according to the spatiotemporal correlation of 3DV sequence [6]. Merkle et al. also proposed another MVC scheme using Hierarchical B Pictures (MVC-HBPs) and achieved superior compression efficiency and temporal scalability [7]. It has been adopted into MVC standardization draft by Joint Video Team (JVT) and used in the Joint Multiview Video Model (JMVM).
In many of the previous MVC schemes [4–7], intra, inter, and interview prediction compensation technologies are adopted to reduce spatial, temporal, and interview redundancies. Additionally, YUV color space transform, integer transform, and quantization technologies are also utilized to explore visual redundancies including chroma redundancies and high frequency redundancies. According to the studies on visual psychology, the Human Visual System (HVS) in fact does not treat visual information equally from regions to regions of the video content [8]. It is mentioned that HVS is more sensitive to the distortion in the Region-Of-Interests (ROIs) or attention areas than those in background regions [9]. Those are visual redundancies coming from regional interests existing in 3DV. However, previous MVC schemes have not taken the regional selective property and 3D depth perception of HVS into consideration. Applying the concept of ROI to video coding is regarded as a promising way to improve coding efficiency by exploiting regional visual redundancies. However, there are two major problems to be tackled, they are ROI detection and the ROI-based bits allocation.
For unsupervised ROI extraction, visual attention has been introduced as one of the key technologies in video/image system [10, 11]. Accordingly, many efforts have been devoted to researches on visual attention model [11–16] so as to simulate the visual attention mechanism of HVS accurately. Itti and Koch developed a bottom-up visual attention model [12] for still images based on Treisman's stimulus integration theory [13]. It generates saliency map with the integration of perceptual stimuli from intensity contrast, colour contrast, and orientation contrast. Zhai et al. used the low-level features as well as cognitive features, such as skin colour and captions, in their visual attention model [14]. Motion is another important cue for visual attention detection in video, thus, a bottom-up spatiotemporal visual attention model is proposed for video sequences in [15]. Wang et al. proposed segment-based video attention detection method [16]. Ma et al. also proposed a bottom-up and top-down combined visual attention model by integrating multiple features, including contrast in image, motion, face detection, audition, and text [11]. However, all these visual attention models were proposed either for static image or single view video and did not take stereoscopic or depth perception into account. On the other hand, stereoscopic parallax is not available in the single-view video.
From the video coding point of view, many bit allocation algorithms [17–24] are proposed for improving compression efficiency. Kaminsky et al. proposed a complexity-rate-distortion model to dynamically allocate bits with both complexity and distortion constraints [17]. Lu et al. proposed a Group-Of-Picture (GOP-)level bit allocation [18] scheme and Shen et al. proposed another frame-level bit allocation method which decreases the average standard deviation of video quality [19]. Özbek and Tekalp proposed a bit allocation among views for scalable multiview video coding [20]. All these bit allocation schemes improve the average Peak Signal-to-Noise Ratio (PSNR) but did not take the regional selective properties of HVS into account. Chen and Wang et al. proposed a bit allocation scheme that allocated more bits on ROI for MPEG-4 standard [21, 22]. These two schemes require very high ROI extraction accuracy. Chi et al. proposed an ROI video coding based on H.263+ for low bit-rate multimedia communications [23]. In the scheme, the ROI was extracted according to skin-color clue and a fuzzy logic controller was designed adaptively to adjust the quantization parameters for each macroblock (MB). Tang et al. proposed a bit allocation scheme for 2D video coding which is guided by visual sensitivity considering motion and texture structures [24]. However, these bit allocation schemes were proposed for single-view video coding and can not be directly applied to MVC because interview prediction is adopted in MVC.
In this paper, we propose a Stereoscopic Visual Attention-(SVA-) based regional bit allocation for improving MVC coding efficiency. We firstly present a framework of MVC in Section 2. In Section 3, we propose an SVA model to simulate visual attention mechanism of HVS. And then, SVA-based bit allocation optimization algorithm is proposed for MVC in Section 4. Section 5 presents the regional selective image quality metrics which are adopted in the coding performance evaluation. In Section 6, SVA-based ROI extraction and multiview video coding experiments are performed and evaluated with various multiview video test sequences. Finally, Section 7 gives conclusions.
2. Framework of Multiview Video System Using Regional Bit Allocation Optimization
Figure 1 shows a framework of MVC with regional bit allocation optimization. Firstly, N channels synchronized color videos are captured by parallel or arc arranged video capture system. Then, N synchronized depth videos, the same resolution as color image, are captured by depth camera array or generated by depth creation algorithms. By using depth video and multiview texture video, the SVA-based ROI extraction module efficiently extracts the semantic ROI mask for MVC codec. With the automatically extracted ROIs, MVC encoder is optimized for bit-rate saving in background region and better quality in ROI using regional bit allocation optimization. Finally, the compressed color and depth video bitstream are multiplexed and transmitted/stored. In the framework, the MB-wise ROI mask may not necessary to be transmitted to the client. Moreover, the framework is compatible with current block-based video coding standard and rate control, and low-level, such as macroblock level, syntax modification is not needed.

Framework of multiview video system using regional bit allocation optimization.
At the client side, the color and depth bitstream is de-multiplexed and decoded by the MVC decoder. With the decoded multiview color videos, depth videos as well as the transferred video cameras' parameters, view generation module renders a continuum of output views,  (
( ), through depth image-based rendering [25]. According to different types of display device, for example, HDTV, stereoscopic display, or multiview display, different number of views is displayed.
), through depth image-based rendering [25]. According to different types of display device, for example, HDTV, stereoscopic display, or multiview display, different number of views is displayed.
3. Stereoscopic Visual Attention-Based ROI Extraction
3.1. Framework of SVA Model
Three-dimensional video provides the most effective stereoscopic perception obtained by viewing a scene from slightly different viewing positions. The depth perception makes the scene more vivid, and it is another important factor that affects human visual attention just like what motion and texture contrasts do in traditional two-dimensional (2D) video. For example, people are often interested in the regions popping out from video screen and the interesting ratio of attention regions decreases as they are getting far away. In our previous work, we presented an SVA model [26] in which depth map was directly adopted as depth visual saliency. In this work, the SVA model is further improved in the following two aspects. Firstly, depth saliency is detected via a depth attention algorithm instead of using the depth map directly and a new fusion algorithm is presented. Secondly, in Section 6.2, a subjective evaluation is performed to testify the effectiveness of the improved SVA model. Each SVA object is modeled by combining the four attributes with low-level features, including depth, depth saliency, image saliency, and motion saliency. The SVA model is defined as

where  is SVA saliency map, D is the intensity of depth maps which indicates the distance between video content and imaging camera/viewer,
is SVA saliency map, D is the intensity of depth maps which indicates the distance between video content and imaging camera/viewer,  ,
,  , and
, and  are image saliency, motion saliency and depth saliency, respectively.
are image saliency, motion saliency and depth saliency, respectively.
Figure 2 presented the architecture of our proposed SVA-based ROI extraction. Image and motion saliency are detected from the multiview color video. Depth saliency is also detected from the multiview depth video. Afterward, a novel dynamic model fusion method is used to integrate the obtained pixelwise image saliency map, motion saliency, and depth saliency. The proposed SVA model does not incorporate any top-down, volitional component because it relies on the cognitive knowledge and differs from person to person. Finally, the MB level ROIs are extracted by threshold and block operation.

Flowchart of the proposed SVA-based ROI extraction.
3.2. Spatial Attention Detection for Static Image
We adopted Itti's bottom-up attention model [12, 27] for our spatial visual attention model. The seven neuronal features implemented are sensitive to color contrast (red/green and blue/yellow), intensity contrast, and four orientations ( ,
,  ,
,  , and
, and  ) for static images. Centre and surround scales are obtained using dyadic Gaussian pyramids with nine levels. Then, Centre-Surround Differences (CSD) [27] are computed as the pointwise differences across pyramid levels; and then, six feature maps for CSD network are computed for each of the seven features, yielding a total of 42 feature maps. Finally, all feature maps are integrated into the unique scalar image saliency
) for static images. Centre and surround scales are obtained using dyadic Gaussian pyramids with nine levels. Then, Centre-Surround Differences (CSD) [27] are computed as the pointwise differences across pyramid levels; and then, six feature maps for CSD network are computed for each of the seven features, yielding a total of 42 feature maps. Finally, all feature maps are integrated into the unique scalar image saliency  .
.
3.3. Temporal Attention Detection
Motion is one of the major stimuli on visual attention of dynamic scene. In this work, we adopt an optical flow algorithm based on block matching method in [28] to estimate the motion of image objects between consecutive frames. Frame group  , which consists of
, which consists of  temporal consecutive frames in view v, is employed to extract robust motion magnitude, where w is temporal window size. The horizontal and vertical motion channels of frame
temporal consecutive frames in view v, is employed to extract robust motion magnitude, where w is temporal window size. The horizontal and vertical motion channels of frame  are determined by frame group F(v,t), then they are combined together as
are determined by frame group F(v,t), then they are combined together as

where operators  and
and  denote the horizontal and the vertical optical flow operator with
denote the horizontal and the vertical optical flow operator with  block size, respectively. "
block size, respectively. " " is the magnitude of motion velocity. Operator
" is the magnitude of motion velocity. Operator  performs upsampling operation of Gaussian pyramid decomposition with
performs upsampling operation of Gaussian pyramid decomposition with  times. Therefore,
times. Therefore,  is with the same resolution as f
v,t
. In this paper, a
is with the same resolution as f
v,t
. In this paper, a  (
( ) block size is adopted to compute the optical flow because we found that it has a robust performance experimentally. Forward and backward motion is intersected so as to eliminate the background exposure phenomena, which refer to the background regions in current frame but attributed as motion regions by
) block size is adopted to compute the optical flow because we found that it has a robust performance experimentally. Forward and backward motion is intersected so as to eliminate the background exposure phenomena, which refer to the background regions in current frame but attributed as motion regions by  or
or  , that is,
, that is,

where  is a trade-off between the sensitivity and error resilience of the motion detection, and it is set as 0 for sensitivity in this paper. Then, to reduce the error effects caused by noises, such as camera shaking and jitter of video sequences, several
is a trade-off between the sensitivity and error resilience of the motion detection, and it is set as 0 for sensitivity in this paper. Then, to reduce the error effects caused by noises, such as camera shaking and jitter of video sequences, several  are weighted combined to form a final motion map, M as follow:
are weighted combined to form a final motion map, M as follow:

where  are weighted coefficients satisfying
are weighted coefficients satisfying  . In this paper, w is set to 3 since it has a good trade-off between complexity and error resilience,
. In this paper, w is set to 3 since it has a good trade-off between complexity and error resilience,  is
is  . Usually, motion attention level increases with relative motion. So motion saliency map is generated by using CSD network [27] and represented as
. Usually, motion attention level increases with relative motion. So motion saliency map is generated by using CSD network [27] and represented as

where  denotes the across-level difference between two maps at the center (c) and the surround (s) levels of the respective feature pyramids,
denotes the across-level difference between two maps at the center (c) and the surround (s) levels of the respective feature pyramids,  ,
,  ,
,  ; ⊕ is across-level addition;
; ⊕ is across-level addition;  is a normalization operator. There are also several normalization strategies available in [29], such as learning, iterative localized iteration. However, these normalization strategies are supervised or very time consuming. Therefore, we adopted the "Naive" strategy in [29] for its low complexity and unsupervised purpose, the normalization operator is
is a normalization operator. There are also several normalization strategies available in [29], such as learning, iterative localized iteration. However, these normalization strategies are supervised or very time consuming. Therefore, we adopted the "Naive" strategy in [29] for its low complexity and unsupervised purpose, the normalization operator is  , which adjusts the saliency value to fixed rang 0
, which adjusts the saliency value to fixed rang 0 255 (value 255 indicates being most salient) for image
255 (value 255 indicates being most salient) for image  .
.
3.4. Depth Impacts on SVA and Depth Attention Detection
The stereoscopic perception can also be represented by the 2D video and the depth map which indicates the relative distance between video object and the camera system. Hence, we use a depth map to analyze the differences between 3D video and traditional 2D video. Compared with traditional 2D video, the depth's effect on human SVA is listed as the following four aspects.
-
(1)
When watching 3D video, people are usually more interested in the regions visually moving out of the screen, that is, pop-out regions, which are with small depth values or large disparities.
-
(2)
As the distance between video object and viewer/camera increases, interesting ratio of the video object decreases.
-
(3)
The out of Depth-Of-Field (DOF) objects of the camera system is usually not the attention areas, for example, defocusing blurred background object or foreground object.
-
(4)
Depth discontinuous regions or depth contrast regions are usually the attention areas in the 3DV as they provide strong depth sensation, especially when view angles or view positions are switching.
-
(5)
Depth map is an 8-bit gray image that can be captured by depth camera or computed using multiview video. Each pixel in the depth map represents a relative distance between video object and camera. In this paper, we firstly estimate the disparity for each pixel in multiview video by using stereo matching method. Then, the disparity is converted into perceptive depth. Finally, intensity of each pixel in depth map is mapped to an irregular space with nonuniform quantization [30]. HVS perceptive depth, Z, is shown as
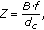 (6)
(6)
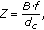
where f is the focal length of the cameras, B is the baseline between the neighboring cameras, d c is the physical disparity (measured by centimeter) between the corresponding points of the neighboring views. However, disparity estimated using stereo matching is measured by pixel. So we use a centimeter-to-pixel ratio, λ, that is, a ratio of CCD size to image resolution, to convert physical disparity to pixel disparity

Because close object is usually more important than far away object, the depth value Z which corresponds to the pixel (x, y) is transformed into the 8-bit intensity  with non-uniform quantization [30]
with non-uniform quantization [30]

where " " is floor operation, z f and z n indicate the farthest and nearest depth, respectively, and
" is floor operation, z f and z n indicate the farthest and nearest depth, respectively, and  ,
,  , f is the focal length, and B is the baseline between cameras. The space between z f and z n is divided into narrow spaces around the z n plane and is divided into wide spaces around the z f plane.
, f is the focal length, and B is the baseline between cameras. The space between z f and z n is divided into narrow spaces around the z n plane and is divided into wide spaces around the z f plane.
It is observed that the depth contrast and the depth orientation contrast are usually attention-catching regions. Thus, we obtain the depth orientation information,  , from depth intensity maps D using oriented Gabor filters, where
, from depth intensity maps D using oriented Gabor filters, where  represents the scale of different pyramids level and
represents the scale of different pyramids level and  . The orientation feature maps of the depth video
. The orientation feature maps of the depth video  are obtained from absolute CSD network [27] between the depth orientation-selective channels
are obtained from absolute CSD network [27] between the depth orientation-selective channels

Additionally, intensity feature maps of the depth video  are obtained from absolute CSD network between the depth intensity channels
are obtained from absolute CSD network between the depth intensity channels

where D indicates the depth intensity map. Finally, the orientation feature map and the intensity feature map are normalized and combined to form a depth saliency map as

where G is a boundary depress matrix. The symbol  is scalar multiplication that indicates that each element of (
is scalar multiplication that indicates that each element of ( ) is multiplied by the scaling factor in the same position in matrix G. In the current stereoscopic display, the regions near by image boundary almost can not provide or just provide a little depth perception. Also, people pay more attention to the center location [31]. Thus, the depth saliency of the image boundary is depressed using a boundary depress matrix G. Each element at position (x, y) in G is
) is multiplied by the scaling factor in the same position in matrix G. In the current stereoscopic display, the regions near by image boundary almost can not provide or just provide a little depth perception. Also, people pay more attention to the center location [31]. Thus, the depth saliency of the image boundary is depressed using a boundary depress matrix G. Each element at position (x, y) in G is  , where L is the number of levels for image boundary depression,
, where L is the number of levels for image boundary depression,

w x andw y are width and height for each boundary depression level, W and H are width and height of the stereoscopic video, respectively.
3.5. Depth-Based Fusion for SVA Model
Psychological studies reveal that HVS is more sensitive to motion contrast when compared to color, intensity, and orientation contrast in single-view video. If a strong motion contrast is presented in the sequence, temporal attention is dominant over the spatial attention. However, if the motion contrast is low in the sequence, the spatial attention is more dominant. In the 3DV, the depth sensation is provided and depth is another key factor for visual attention in stereoscopic video. Thus, depth, spatial and temporal information of 3DV are jointly combined to construct SVA saliency as

where  ,
,  , and
, and  are weighted coefficients for depth saliency, motion saliency, and image saliency, respectively, and they satisfy
are weighted coefficients for depth saliency, motion saliency, and image saliency, respectively, and they satisfy  ,
,  . Relative larger weighted coefficient value shall be given to more dominative saliency.
. Relative larger weighted coefficient value shall be given to more dominative saliency.  denotes correlation between saliency a and saliency b,
denotes correlation between saliency a and saliency b,  ,
,  is a weighted coefficient for
is a weighted coefficient for  ,
,  , and
, and  is a scaling function for depth intensity video. If the depth video is not provided, then (13) will be considered as a spatiotemporal scheme which fuses motion and still image saliency.
is a scaling function for depth intensity video. If the depth video is not provided, then (13) will be considered as a spatiotemporal scheme which fuses motion and still image saliency.
Based on the SVA saliency map, MB  is labeled as ROI when average
is labeled as ROI when average  energy of an MB is lager than average
energy of an MB is lager than average  energy of an image weighted by
energy of an image weighted by  , that is,
, that is,  ; Otherwise,
; Otherwise,  is labeled as background, that is,
is labeled as background, that is,

where  and
and  are height and width of
are height and width of  , W and H are width and height of the video, respectively. As threshold
, W and H are width and height of the video, respectively. As threshold  increases,
increases,  with lower SVA saliency will be determined as ROIs, and vice versa. In this paper,
with lower SVA saliency will be determined as ROIs, and vice versa. In this paper,  is set as 1.10. To transit image quality from ROI to background regions smoothly in MVC, two MB wide transitional regions between ROI and background MB are defined. A sample of ROI mask is shown in Figure 3. The black rectangles are ROI MBs, white rectangles are background MBs, and gray rectangles are transitional MB with different levels.
is set as 1.10. To transit image quality from ROI to background regions smoothly in MVC, two MB wide transitional regions between ROI and background MB are defined. A sample of ROI mask is shown in Figure 3. The black rectangles are ROI MBs, white rectangles are background MBs, and gray rectangles are transitional MB with different levels.

Sample of attention mask.
4. SVA-Based Regional Bit Allocation Optimization for MVC
The MVC-HBP prediction structure [7], shown in Figure 4, is interview and temporal prediction hybrid. The even views are coded using motion prediction compensation, while the odd views are coded utilizing both interview prediction and temporal prediction. Since the MVC-HBP prediction structure is superior on both compression efficiency and temporal scalability, it is adopted by JVT and used in reference software JMVM. This superior coding performance is mainly owing to its novel quantization strategy. Given the basis Quantization Parameter (QP) of MVC-HBP prediction structure, bQP, the remaining QPs are determined as

where l is hierarchical level of hierarchical B frame. In the proposed SVA-based MVC scheme, larger QPs are set for background regions and transitional regions for higher compression ratio. The QP of SVA-based ROI in level l is set as  . QPs of the background and the transitional regions in the l th hierarchical level picture,
. QPs of the background and the transitional regions in the l th hierarchical level picture,  and
and  , are defined as
, are defined as

where " " is floor operation, η
i
is a positive division parameter, and
" is floor operation, η
i
is a positive division parameter, and  is a QP difference between background region and ROI region and it indicates the relative amount of bits allocated between ROI and the background regions.
is a QP difference between background region and ROI region and it indicates the relative amount of bits allocated between ROI and the background regions.

MVC-HBP prediction structure.
To exploit regional selective visual redundancies in 3DV, the SVA-based MVC scheme is used to maximize compression ratio while at the cost of imperceptible image quality loss in background. Therefore, we need to determine the optimal  . The bit allocation optimization scheme in [32] is adopted to determine bit allocation between SVA-based ROIs and background regions. Here, a short review on the bit allocation scheme is presented for better readability. Two indices, the average bit-rate saving ratio,
. The bit allocation optimization scheme in [32] is adopted to determine bit allocation between SVA-based ROIs and background regions. Here, a short review on the bit allocation scheme is presented for better readability. Two indices, the average bit-rate saving ratio,  , and the image quality degradation,
, and the image quality degradation,  , are adopted to evaluate the coding performance of MVC scheme with different
, are adopted to evaluate the coding performance of MVC scheme with different  . The bit-rate saving ratio,
. The bit-rate saving ratio,  , is calculated as
, is calculated as

where  and where
and where  and
and  are the numbers of views and time instants in one GOP, i and j are temporal and interview position, respectively.
are the numbers of views and time instants in one GOP, i and j are temporal and interview position, respectively.  denotes the number of bits of encoding a frame at position (i, j) while its ROIs are coded with
denotes the number of bits of encoding a frame at position (i, j) while its ROIs are coded with  and background regions are coded with
and background regions are coded with  and
and  denote the QP differences between the ROI and the background regions, respectively.
denote the QP differences between the ROI and the background regions, respectively.
Figure 5 shows the relationship between  and
and  in that one QP is used for both ROI and background regions.
in that one QP is used for both ROI and background regions.  is subjected to the exponential decaying function as
is subjected to the exponential decaying function as  increases. Thus,
increases. Thus,  can be predicted as
can be predicted as

where  and
and  are the coefficients of functions
are the coefficients of functions  and independent to the content of multiview video.
and independent to the content of multiview video.  is the maximum bit-rate saving ratio. Because ROI and background regions are mutual exclusive, we can obtain
is the maximum bit-rate saving ratio. Because ROI and background regions are mutual exclusive, we can obtain


The relationship between  and
and  .
.
Once, ROI and background regions are segmented for 3DV sequence, the bit-rate saving ratio of ROI is approximately in direct proportion to that of background region while  increases. It is represented by
increases. It is represented by

where  is independent of
is independent of  . Hence, substituting (19) and (20) into (18), we can obtain
. Hence, substituting (19) and (20) into (18), we can obtain

where  and
and  .
.  indicates amplitude of bit-rate saving. Parameter T indicates the period that
indicates amplitude of bit-rate saving. Parameter T indicates the period that  reaches the point of no more gain can be saved as
reaches the point of no more gain can be saved as  QP increases.
QP increases.
On the other hand, image quality degradation caused by allocating fewer bits on background regions  is calculated as
is calculated as

where  and where
and where  denotes the reconstructed image quality of a frame at position (i, j), while ROIs are coded with
denotes the reconstructed image quality of a frame at position (i, j), while ROIs are coded with  , and background regions are coded with
, and background regions are coded with  .
.  , and
, and  denote QP changes in ROI and background regions, respectively. Because the relationship between distortion, such as PSNR, and quantization factor in H.264 is approximately linear [33], we can define the image quality degradation of bit allocation,
denote QP changes in ROI and background regions, respectively. Because the relationship between distortion, such as PSNR, and quantization factor in H.264 is approximately linear [33], we can define the image quality degradation of bit allocation,  , as
, as

where  is coefficient independent to
is coefficient independent to  , and
, and  is a negative value which indicates the slope of image quality degradation.
is a negative value which indicates the slope of image quality degradation.  is a negative value and it will decrease as
is a negative value and it will decrease as  increases to improve compression ratio.
increases to improve compression ratio.
To achieve a high compression ratio and also to maintain high image quality with bit allocation optimization, we ought to find the optimal  to maximize bit-rate saving ratio
to maximize bit-rate saving ratio  subject to a unnoticeable image quality degradation,
subject to a unnoticeable image quality degradation,  . It is mathematically expressed as
. It is mathematically expressed as

Instead of solving the constrained problem in (24), an unconstrained formulation is employed. The optimal  is determined as
is determined as

where  is a scaling constant putting
is a scaling constant putting  and
and  D in a same scale. We set the partial derivative of function
D in a same scale. We set the partial derivative of function  of
of  equal to 0, that is,
equal to 0, that is,

By solving the (26), the optimal integer  is obtained as
is obtained as

where symbol " " is floor operation. Meanwhile,
" is floor operation. Meanwhile,  is truncated to 0 if
is truncated to 0 if  is smaller than 0. Coefficients A, T, and
is smaller than 0. Coefficients A, T, and  are bQP dependent and will be modeled experimentally from MVC experiments presented in Section 6.3.
are bQP dependent and will be modeled experimentally from MVC experiments presented in Section 6.3.
5. ROI-Based Objective Image Quality Assessment Metric
Pixelwise image quality assessment metric, such as PSNR, has been widely used for video quality evaluation. However, it does not match well with the human visual perception. Engelke et al. proposed a region-selective objective image quality metric [34] which is able to be combined with normalized hybrid image quality metric, reduced-reference image quality assessment technique, Structural SIMilarity (SSIM) [35], or PSNR measures. Since both SSIM and PSNR have been adopted in advanced video coding standard, H.264/AVC, we apply both the region-selective SSIM and PSNR metrics [34] to evaluate the proposed MVC scheme. The SSIM index [34] between two images is computed as

where R and D are two nonnegative image signals to be compared,  and
and  are the means of images R and D,
are the means of images R and D,  and
and  are standard deviation of images R and D, respectively, and
are standard deviation of images R and D, respectively, and  is covariance of images R and D,
is covariance of images R and D,  and
and  are constants. The PSNR of illumination component (PSNR_Y) measures the fidelity difference of two image signals I
R
(x,y) and I
D
(x,y) on a pixel-by-pixel basis as
are constants. The PSNR of illumination component (PSNR_Y) measures the fidelity difference of two image signals I
R
(x,y) and I
D
(x,y) on a pixel-by-pixel basis as

where Γ is the maximum pixel value, here it is 255.
The objective image quality metrics have been used to independently assess the image quality of ROI and background region to enable region-selective quality metric design. An ROI quality metric  is calculated on ROI of reference and distorted images. Similarly, background regions of reference and distorted images are used to assess quality of the background region by computing
is calculated on ROI of reference and distorted images. Similarly, background regions of reference and distorted images are used to assess quality of the background region by computing  . In a pooling stage,
. In a pooling stage,  and
and  are combined with a region-selective metric, and the final Predictive Mean Opinion Score (PMOS) is computed as follows [34]:
are combined with a region-selective metric, and the final Predictive Mean Opinion Score (PMOS) is computed as follows [34]:

where  ,
, 
 ,
, ,
, ,
, , and
, and  are derived from the subjective quality evaluation experiments in [34]. In the following sections, PMOSs of PSNR_Y and SSIM are denoted by PMOS_PSNR and PMOS_SSIM, respectively.
are derived from the subjective quality evaluation experiments in [34]. In the following sections, PMOSs of PSNR_Y and SSIM are denoted by PMOS_PSNR and PMOS_SSIM, respectively.
6. Experimental Results and Analyses
In this section, the performance of SVA-based ROI extraction algorithms and SVA-based MVC are evaluated. Experiments include three steps. First, SVA-based ROI extraction experiments are performed and evaluated with subjective experiments. Secondly, regional bit allocation optimization experiments are performed for allocating reasonable mounts of bits among ROI and background regions and optimal  QP is determined. Finally, MVC experiments are implemented to verify the efficiency of the SVA-based bit allocation optimization. In these experiments, we adopt seven typical multiview video sequences provided by Heinrich Hertz Institute (HHI) [36], Microsoft Research (MSR) [37], and Nagoya University [38]. These 3DV sequences are with different textures, motion properties, resolutions, capturing frame rates, and camera arrangements. Eight views of the test sequences are illustrated in Figure 6. Table 1 shows the properties of the test multiview video sequences. Depth maps of Breakdancers and Ballet test sequences, marked as "A" in last column, are available. The depth maps of the rest videos, marked as "N/A", are generated by Depth Estimation Reference Software (DERS) [39].
QP is determined. Finally, MVC experiments are implemented to verify the efficiency of the SVA-based bit allocation optimization. In these experiments, we adopt seven typical multiview video sequences provided by Heinrich Hertz Institute (HHI) [36], Microsoft Research (MSR) [37], and Nagoya University [38]. These 3DV sequences are with different textures, motion properties, resolutions, capturing frame rates, and camera arrangements. Eight views of the test sequences are illustrated in Figure 6. Table 1 shows the properties of the test multiview video sequences. Depth maps of Breakdancers and Ballet test sequences, marked as "A" in last column, are available. The depth maps of the rest videos, marked as "N/A", are generated by Depth Estimation Reference Software (DERS) [39].

Eight views of multiview video test sequences. BalletBreakdancersDoorflowersAlt MoabitDogPantomimeChampagne tower
6.1. SVA-Based ROI Extraction
In the 3DV, motion saliency object is usually the most salient regions in the visual attentive area; next is the image saliency. Depth saliency is relatively less important and is given smaller weighted coefficient while comparing with motion saliency and image saliency except that the 3DV provides strong depth perception. So in the experiments, relative larger weighted coefficient value is given to dominative or more important motion saliency, and  ,
,  , and
, and  are empirically set as 0.2, 0.35, and 0.45 under the constraints
are empirically set as 0.2, 0.35, and 0.45 under the constraints  and
and  . On the other hand, in the Multiview video, image, motion, and depth saliencies are correlated with each other. The correlation between image and motion saliencies is higher than the other two correlations, that is, correlations between depth and image saliency, depth and motion saliency. It is because detected moving objects are likely textural objects. However, there are no explicit correlations between depth and image/motion saliency. Thus, the weighted coefficients
. On the other hand, in the Multiview video, image, motion, and depth saliencies are correlated with each other. The correlation between image and motion saliencies is higher than the other two correlations, that is, correlations between depth and image saliency, depth and motion saliency. It is because detected moving objects are likely textural objects. However, there are no explicit correlations between depth and image/motion saliency. Thus, the weighted coefficients  are larger than
are larger than  ,
, , and they empirically are set as 0.6, 0.2, and 0.2, respectively. Actually, in order to accurately simulate the mechanism of human visual attention, values of parameters
, and they empirically are set as 0.6, 0.2, and 0.2, respectively. Actually, in order to accurately simulate the mechanism of human visual attention, values of parameters  ,
,  , and
, and  , and
, and  ,
,  , and,
, and,  should be adjusted according to motion, textual, and depth characteristics of the multiview video sequences.
should be adjusted according to motion, textual, and depth characteristics of the multiview video sequences.
In the depth video, the z f and z n planes are mapped to 0 and 255, respectively, with the non-uniform quantization process in (8), which treats z f plane as infinite far away and supposes that saliency in z f plane is completely unimportant. However, z f planes of the video sequences are usually not infinite. So, we use the scaling function  , where
, where  is a positive constant, to map the z n
is a positive constant, to map the z n z f plane to
z f plane to  and take the saliency in z f plane into account. Usually,
and take the saliency in z f plane into account. Usually,  shows the importance of the saliency in z f plane compared with that of z n plane. It increases as z f plane closes toz n plane and decreases to 0 as z f becomes infinite. In the SVA extraction experiments,
shows the importance of the saliency in z f plane compared with that of z n plane. It increases as z f plane closes toz n plane and decreases to 0 as z f becomes infinite. In the SVA extraction experiments,  is set to 50 because most of the test video sequences are indoor scene and their z f planes close to z n plane.
is set to 50 because most of the test video sequences are indoor scene and their z f planes close to z n plane.
Figure 7 shows the SVA-based ROI extraction results for different multiview test sequences. Figure 7(a) renders one view of original multiview video. Figure 7(b) shows one view of multiview depth video in which large depth comes with small intensity and small depth with large intensity. Figures 7(c), 7(d), and 7(e) show feature maps of intensity, color, and orientation, respectively. In these feature maps and saliency maps followed, white pixel indicates a high saliency pixel and black pixel indicates a low saliency pixel in the multiview video. Figure 7(f) exhibits static image saliency combining feature maps of intensity, color, and orientation. Figure 7(j) shows the extracted ROI based on static image saliency only. The spatial attention model can simulate the visual attention mechanisms well for some sequences with simple background, such as Champagne tower and Pantomime. However, for the sequences with complex background, such as Ballet and Dog, the spatial attention model is not accurate enough. Other information, such as motion and depth, shall be utilized to improve visual attention model for dynamic stereoscopic visual scenes.

SVA-based ROI extraction results. (a) One view of original multiview video; (b) One view of multiview depth video; (c) Feature maps of intensity; (d) Feature maps of color; (e) Feature maps of orientation; (f) Static image saliency map; (g) Motion saliency map; (h) Depth saliency map; (i) Final SVA saliency map (proposed); (j) Extracted ROI using static image saliency (S-scheme); (k) Extracted ROI using motion saliency (T-scheme); (l) Extracted ROI using spatiotemporal saliency (ST-scheme); (m) Extracted ROI based on SVA model (proposed); (n) MB-level ROI mask (proposed).BalletBreakdancersDoorflowersAlt MoabitDogPantomimeChampagne tower
Figure 7(g) illustrates motion saliency maps and Figure 7(k) shows the ROI extracted on the basis of motion saliency only. Generally, large motion contrast areas are very likely to be potential attention areas. However, it is not always true. For example, for Ballet sequence, the shadow of the dancing girl exhibits high motion contrast, but it is not an attentive area. This kind of noise can be eliminated by combining the depth saliency and static image saliency. Figure 7(h) shows the depth saliency extracted from depth video by using the proposed algorithm in Section 3.3. As we can see from the depth saliency map, the depth contrast regions are extracted as the most salient, which is coinciding with the discovery that people are in particularly interested in depth contrast regions because it provides more impressive stereoscopic perception. Besides, regions with small depth, that is, large intensity in depth map, are also extracted as salient region, which is also in accordance with the fact that people are usually more interested in an object close to them in a view than that far away from them. According to the extracted depth saliency of various test sequences, the proposed depth saliency detection algorithm is efficient and maintains high accuracy as the depth map is accurate. However, for inaccurate depth and the sequences with weak depth perception, only depth saliency turns out to be not sufficient to simulate visual attention. Such cases can be noted in Pantomime and Breakdancers.
Figure 7(i) shows the final SVA saliency map generated by the proposed SVA model. We can see that Figure 7(i) can simulate visual attention mechanism of HVS better for all sequences when compared with Figures 7(f)–7(h). Taking Ballet sequence as an example, the proposed SVA model can depress the noise in spatial saliency map (black region on the wall in color image), noise in motion saliency map (shadow of the dancing girl), and noise in depth (the foreground floor). Favorable saliency map and ROI are created. For Doorflowers sequence, multiple attention cues including motion (two men and the door), static image attention (clock, painting, and chair), and depth (the sculpture) are integrated together very well by the proposed model. Similar results can be found for other multiview video sequences. Therefore, it can be concluded that the proposed model detects the SVA accurately and simulates HVS well by fusing depth information, static image saliency, and motion saliency. Additionally, though there are noises in both the depth map and/or the image saliency, the proposed model still can obtain satisfactory SVA jointly using depth, motion, and texture information and depress noises in each channel. Thus, the proposed model is error resilient and with high robustness.
The ROI extraction results, as illustrated in Figures 7(j)–7(m), are generated by four schemes, that is, S-scheme, T-scheme, ST-scheme, and proposed SVA scheme. S-scheme denotes ROI extraction only using static image information. T-scheme denotes that ROI is extracted only using motion information. ST-scheme indicates ROI extraction using both static image information and motion information. SVA denotes ROI is extracted based on our proposed SVA model. Figure 7(m) shows the extracted MB level ROI based on SVA and Figure 7(n) is MB level ROI mask in which Black blocks are ROI MBs, gray blocks are transitional MBs, and white blocks are background MBs. Comparing Figures 7(j), 7(k), and 7(l) with Figure 7(m), we can see that extracted ROIs based on SVA model are similar to this ROI extraction based on static image saliency (S-scheme) for simple textural multiview video, such as Pantomime and Champagne tower. However, for complex textural multiview video, such as Dog, Ballet, Alt Moabit, and Doorflowers, the ROIs extracted based on the proposed SVA model are much better and more favorable than S-scheme, T-scheme, and ST-scheme because they lack of information from depth or motion channel.
6.2. Subjective Evaluation for SVA-Based ROI Extraction
Subjective evaluation of SVA-based ROIs extraction results has also been performed. Polarization-multiplexed display method is used for displaying stereo video and image. Stereoscopic images are played back through a stereoscopic dual projection system, where two BenQ P8265 DLP projectors are used to project left and right view images on a 150-inche silver screen. Viewers wear polarized glasses to watch the stereo video. Extracted ROI results are randomly ordered and displayed on a traditional monoview  LCD display at the time when stereoscopic video is being displayed via the stereoscopic video system. The experiment is conducted in a special room with ambient illumination, color temperature, and ambient sound controlled according to the requirements in ITU-R Recommendation 500 [40]. There are 20 participants recruited in campus, age from 22 to 32, 7 females and 13 males, 2 participants are experts, 15 participants have some stereoscopic image processing knowledge, and the rest 3 participants do not have image processing knowledge. That is the 18 participants are nonexpert and they are not concerned with the visual attention and the ROI extraction in their normal work. All participants passed the color vision test and achieved the minimum criteria: acuity of 20 : 30 vision, stereoscopic visual acuity of 40 sec.arc.
LCD display at the time when stereoscopic video is being displayed via the stereoscopic video system. The experiment is conducted in a special room with ambient illumination, color temperature, and ambient sound controlled according to the requirements in ITU-R Recommendation 500 [40]. There are 20 participants recruited in campus, age from 22 to 32, 7 females and 13 males, 2 participants are experts, 15 participants have some stereoscopic image processing knowledge, and the rest 3 participants do not have image processing knowledge. That is the 18 participants are nonexpert and they are not concerned with the visual attention and the ROI extraction in their normal work. All participants passed the color vision test and achieved the minimum criteria: acuity of 20 : 30 vision, stereoscopic visual acuity of 40 sec.arc.
Seven multiview video sequences illustrated in Figure 6 are adopted for ROI subjective evaluation. Sequences are displayed in the order of Champagne tower, Dog, Doorflowers, Breakdancers, Alt Moabit, Pantomime, and then Ballet. The ROI extraction results, as illustrated in Figure 7(j)–7(m), are generated by the four schemes, S-scheme, T-scheme, ST-scheme, and proposed SVA scheme, respectively. Example of stereoscopic video displaying is shown in Figure 8(a). ROIs by different schemes are randomly displayed on four areas of monoview LCD display and example of the demonstration is shown as Figure 8(b). The displaying time interval for each sequence is shown in Figure 9. Both stereoscopic video and stereoscopic image are displayed on the dual projection system in different time slot. Before the subjective experiment, participants had a try of the stereo vision system with several stereopair images from Middlebury Stereo Vision Page (http://vision.middlebury.edu/stereo/). All participants were informed of the stereo video and ROI images displaying procedure for each sequence, shown as Figure 9. And in the ranking stage after showing stereo video/images, they were asked to make a comparison on the four extracted ROIs and rank them from 1 to 4 for the ROIs shown on monoview LCD display based on their viewing experience of stereo video/images, where 1 indicates the best one (the ROI is most identical to their ROI impression) and 4 indicates the worst one (the ROI is least identical to their ROI impression).

(a) Example of stereoscopic video (b) ROIs on monoview LCD display.

Displaying time interval of stereoscopic video and the extracted ROIs.
With the ranking scores, the preference metrics of SVA scheme over other schemes are obtained. Then, Thurstone model and paired comparisons [41] have been adopted to analyze the performance of the four ROI extraction schemes. Table 2 shows the z-scores, Mean Opinion Score (MOS), and its standard errors for four ROI extraction schemes with different test 3DVs. The proposed SVA-based ROI extraction scheme is set as 0 for reference and proper identification for the z-scores. Higher z-score indicates better performance and the best performance scheme for each sequence is shown in yellow shadow.
As shown in Table 2, for the five sequences, including Champagne tower, Dog, Doorflowers, Alt Moabit, and Ballet sequences, ROIs generated by the proposed SVA-based ROI extraction scheme are of the highest z-scores which means these ROIs are most identical to people's preference. However, for Breakdancers sequence, the z-score of ST-scheme is 0.401 (better than the SVA scheme) because the sequence has dramatically high speed motion attracting more attentions. For Pantomime sequences, the proposed SVA scheme is ranked no. 2 because the sequence is with simple background and provides relatively weak stereoscopic perception. In addition, the extracted ROIs of the four schemes are quite similar and hard to be distinguished. Generally, according to the average z-scores, the proposed SVA extraction scheme achieves the best performance for the test 3DV. Then, the performance ST-scheme comes next. S-scheme and T-scheme have relatively low performance and low robust because they highly depend on the texture and motion properties of video sequences.
The middle four rows of the Table 2 show MOS of the ranking ROIs, in which smaller value indicates better performance. As far as MOS is concerned, similar results can be found. The proposed SVA-based ROI extraction scheme has the best performance as it has the lowest MOS for five test sequences and lowest average MOS. In the last four rows, standard errors for MOS are also illustrated. We can see that the deviation for SVA scheme (0.99 on average) is larger than ST-Scheme (0.77 on average). It is because the participants' depth sensations vary from person to person. While viewing the stereo video and images, some non-expert viewers seem to be more sensitive to depth perception. On the contrary, expert viewers pay more attentions on motion, textural, or semantic areas because they are already familiar with the depth sensation.
6.3. SVA-based Regional Bit Allocation Optimization for MVC
To determine the optimal  used in the MVC scheme, video coding experiments are implemented on JMVM7.0 [42] with MVC-HBP prediction structure, bQP and
used in the MVC scheme, video coding experiments are implemented on JMVM7.0 [42] with MVC-HBP prediction structure, bQP and  are set as
are set as  and
and  . Multiview video sequences, Ballet and Breakdancers, are adopted because they have both slow and fast motion characteristic. Eight views and 91 frames in each view (6 GOPs while GOP length is 15) are encoded. Parameter
. Multiview video sequences, Ballet and Breakdancers, are adopted because they have both slow and fast motion characteristic. Eight views and 91 frames in each view (6 GOPs while GOP length is 15) are encoded. Parameter  and
and  are empirically set as 3 and 6 for first and second level transitional areas.
are empirically set as 3 and 6 for first and second level transitional areas.
Figure 10 shows the relation maps of  to
to  for Ballet and Breakdancers sequences. More bit-rate can be saved as
for Ballet and Breakdancers sequences. More bit-rate can be saved as  becomes larger. However, the gradient of
becomes larger. However, the gradient of  decreases as the
decreases as the  increases, The bit-rate saving ratio,
increases, The bit-rate saving ratio,  , obeys the exponential decaying function described in (21). Besides, the gradient and up-boundary of
, obeys the exponential decaying function described in (21). Besides, the gradient and up-boundary of  decreases as bQP increases. Figures 11 and 12 show the relationships between bQP and the coefficients, that is, T andA. Each point in the figures is fitted from each curve of Figure 10 adopting exponential function in (15). The red points are the coefficients fitted from Ballet sequence and the black points are fitted from Breakdancers sequence.
decreases as bQP increases. Figures 11 and 12 show the relationships between bQP and the coefficients, that is, T andA. Each point in the figures is fitted from each curve of Figure 10 adopting exponential function in (15). The red points are the coefficients fitted from Ballet sequence and the black points are fitted from Breakdancers sequence.  indicates amplitude of bit-rate saving and decreases as bQP increases. As bQP increases, the up-boundary of bit-rate saving ratio decreases to zero and little coding gain can be expected as bQP is bigger than 35. T indicates the velocity of bit-rate saving becoming saturated. As bQP increases, the velocity is getting faster. Then, we fit the obtained points in Figures 11 and 12 using a linear and Boltzman function. Parameters T andA are expressed as
indicates amplitude of bit-rate saving and decreases as bQP increases. As bQP increases, the up-boundary of bit-rate saving ratio decreases to zero and little coding gain can be expected as bQP is bigger than 35. T indicates the velocity of bit-rate saving becoming saturated. As bQP increases, the velocity is getting faster. Then, we fit the obtained points in Figures 11 and 12 using a linear and Boltzman function. Parameters T andA are expressed as

where  ,
,  ,
,  ,
,  ,
,  and
and  .
.

The relation maps of bit saving ratio ( b QP,0, QP) to QP. BreakdancersBallet

Relation map of bQP and coefficient T .

Relation map of bQP and coefficient A .
We use the PMOS_PSNR index to evaluate the reconstructed image quality, that is,  in (22) is derived from (30), and Φ is PSNR_Y. The average PMOS_PSNR value to
in (22) is derived from (30), and Φ is PSNR_Y. The average PMOS_PSNR value to  is illustrated in Figure 13. Each line in the figure has one bQP but different
is illustrated in Figure 13. Each line in the figure has one bQP but different  . We can see that the image quality evaluated by PMOS_PSNR linearly decreases as
. We can see that the image quality evaluated by PMOS_PSNR linearly decreases as  increases. Besides, the slope of image quality degradation is getting flat as
increases. Besides, the slope of image quality degradation is getting flat as  increases. Figure 14 shows the relationship between
increases. Figure 14 shows the relationship between  and the coefficient
and the coefficient  , which indicates the slope of image quality degradation,
, which indicates the slope of image quality degradation,  . Each point in the figure is the coefficient
. Each point in the figure is the coefficient  fitted from
fitted from  using linear function in (23). The red points are the coefficients,
using linear function in (23). The red points are the coefficients,  , fitted from Ballet sequence and the black points are fitted from Breakdancers sequence. We fit these points in Figure 14 using exponential decaying function and obtain
, fitted from Ballet sequence and the black points are fitted from Breakdancers sequence. We fit these points in Figure 14 using exponential decaying function and obtain

where  ,
,  , and
, and  .
.

The relation maps of image quality to . BreakdancersBallet

Relation map of bQP and b 1 .
Applying (31) and (32) to (27), optimal  for different
for different  s is obtained, shown as Figure 15. The maximum point of
s is obtained, shown as Figure 15. The maximum point of  increases as
increases as  decreases. However, the trends of the optimal
decreases. However, the trends of the optimal  are similar for different scaling
are similar for different scaling  s. We set
s. We set  as 0.08 to scale
as 0.08 to scale  and
and  D into a same scale according to the test sequence. Then, the final optimal
D into a same scale according to the test sequence. Then, the final optimal  is obtained. For low bQP, for example,
is obtained. For low bQP, for example,  , significant bit-rate saving can be achieved by selecting large
, significant bit-rate saving can be achieved by selecting large  . However, the image quality is also degraded a lot. Thus,
. However, the image quality is also degraded a lot. Thus,  is reasonable to be smaller than 8 so that a wise tradeoff between bit-rate saving ratio and image quality degradation can be achieved. As for large bQP, for example,
is reasonable to be smaller than 8 so that a wise tradeoff between bit-rate saving ratio and image quality degradation can be achieved. As for large bQP, for example,  , most MBs in background regions are already coded with SKIP/DIRECT mode, in which no residuals are coded, and little coding gain can be expected by choosing large
, most MBs in background regions are already coded with SKIP/DIRECT mode, in which no residuals are coded, and little coding gain can be expected by choosing large  . In some cases, the bit-rate saving ratio will not increase as
. In some cases, the bit-rate saving ratio will not increase as  increases because the encoding bits of
increases because the encoding bits of  will increase along with the increasing
will increase along with the increasing  . Therefore, it is reasonable to limit
. Therefore, it is reasonable to limit  within the range from 2 to 4 at low bit rate (large bQP).
within the range from 2 to 4 at low bit rate (large bQP).

Optimal and integer for different μs.
6.4. MVC Experiments
SVA-based MVC experiments are implemented on the JMVM 7.0 reference software with seven multiview video sequences and their ROI masks, Ballet, Breakdancers, Doorflowers, Alt Moabit, Pantomime, Champagne tower, and Dog, to evaluate the effectiveness of the proposed SVA-based bit allocation. The MVC-HBP prediction structure is adopted for MVC simulation. Eight views and GOP Length are 15, fast motion/disparity estimation is enabled, and search range is 64. There are three kinds of picture in the MVC-HBP prediction structure: intracoded picture (I-picture), interpredicted picture (P-picture), and hierarchical bidirectional predicted picture (B-picture). In the coding experiment, all B- and P-pictures are coded with regional bit allocation optimization and I-pictures are coded with original MVC scheme without bit allocation optimization. The bQP is set as 12, 17, 22, 27, or 32, and the QPs of background and ROI are set according to (16) and obtain optimal  in Figure 15. PMOS_SSIM and PMOS_PSNR are adopted to evaluate image quality of the reconstructed video frames.
in Figure 15. PMOS_SSIM and PMOS_PSNR are adopted to evaluate image quality of the reconstructed video frames.
Figure 16 shows the rate-distortion curves of the proposed MVC and JMVM, where the distortions are measured with PMOS_PSNR. Figure 17 shows the rate-distortion curves of the proposed MVC and JMVM, where the distortions are measured with PMOS_SSIM. Curves in the figures are fitted with the algorithm provided in [43]. As we can see from Figure 16, more than 10% bit rate is saved while maintaining the same PMOS_PSNR for Breakdancers when bit rate is higher than 4 Mbps. For Ballet sequences, the proposed scheme attains the same coding performance at low bit rate, but improves coding performance significantly at high bit rate, that is, more than 20% bit rate is saved at high bit rate. Similar results can be found for Doorflowers, Alt Moabit, Pantomime, Champagne tower, and Dog sequences. Also, as we can see from Figure 17 in which distortion is measured with PMOS_SSIM, the proposed MVC scheme outperforms JMVM more distinctively, with  bit rate saving while maintaining the same PMOS_SSIM, from low bit rate to high bit-rate for most of these test multiview video sequences.
bit rate saving while maintaining the same PMOS_SSIM, from low bit rate to high bit-rate for most of these test multiview video sequences.

Rate-distortion performances comparisons between the proposed MVC and JMVM (distortions are measured with PMOS_PSNR). BreakdancersBalletDoorflowersAlt MoabitPantomimeDogChampagne tower

Rate-distortion performances comparisons between the proposed MVC and JMVM (Distortions are measured with PMOS_SSIM). BreakdancersBalletDoorflowersAlt moabitPantomimeDogChampagne tower
Figure 18 shows images reconstructed with the proposed MVC scheme and the JMVM benchmark and Table 3 shows the objective image quality value and coding bits corresponding to Figure 18. They show the reconstructed images of the 15th frame of the 2nd view (i.e., S1T15 in Figure 4) of the test 3DV sequences. Encoding bits and another five image quality indices including PSNR_ , PSNR_
, PSNR_ , PSNR_Y, PMOS_SSIM, and PMOS_PSNR are compared for each sequence. PSNR_
, PSNR_Y, PMOS_SSIM, and PMOS_PSNR are compared for each sequence. PSNR_ , PSNR_
, PSNR_ , and PSNR_Y denote the PSNR of illumination component for SVA-based ROI regions, background region, and the entire picture, respectively. PMOS_PSNR and PMOS_SSIM represent the PMOS of PSNR_Y and SSIM, respectively. In addition, the differences of the bit-rate saving ratio and image quality indices are also given and they are computed using the following formulas:
, and PSNR_Y denote the PSNR of illumination component for SVA-based ROI regions, background region, and the entire picture, respectively. PMOS_PSNR and PMOS_SSIM represent the PMOS of PSNR_Y and SSIM, respectively. In addition, the differences of the bit-rate saving ratio and image quality indices are also given and they are computed using the following formulas:

where  ,
,  ,
,  ,
,  is the bit-rate saving ratio for the proposed MVC scheme with respect to the encoded picture at (i,j) position of a GOP.
is the bit-rate saving ratio for the proposed MVC scheme with respect to the encoded picture at (i,j) position of a GOP.  and
and  denote encoding bits of the coded pictures by using JMVM and the proposed MVC scheme, respectively.
denote encoding bits of the coded pictures by using JMVM and the proposed MVC scheme, respectively.

Subjective and objective quality comparison of the reconstructed images (Left: JMVM, Right: Proposed). BreakdancersBalletDoorflowersAlt moabitPantomimeDogChampagne tower
Because people usually pay less attention to the background regions and more attention to ROIs, HVS is less perceptible to distortion in the background regions than that of ROIs. This implies that people are more sensitive to distortions in the ROIs than in the background region. As a result, high image quality is required in ROIs. For Ballet multiview video sequence, ΔPSNR_ is 0.46 dB while ΔPSNR_
is 0.46 dB while ΔPSNR_ is
is  dB. It means that the proposed SVA-based MVC scheme improves image quality of ROI up to 0.46 dB; meanwhile, to improve compression ratio, the proposed SVA-based MVC scheme allocates fewer bits on the background regions and at the cost of its PSNR_
dB. It means that the proposed SVA-based MVC scheme improves image quality of ROI up to 0.46 dB; meanwhile, to improve compression ratio, the proposed SVA-based MVC scheme allocates fewer bits on the background regions and at the cost of its PSNR_ . In the proposed MVC scheme, the image quality of ROIs is getting better than that of background region, that is, PSNR_
. In the proposed MVC scheme, the image quality of ROIs is getting better than that of background region, that is, PSNR_
 PSNR_
PSNR_ , which meets the requirements of HVS. Thus, the quality of the reconstructed images is improved. While evaluated by the regional selective image quality metrics, ΔPMOS_SSIM is 0.78 and ΔPMOS_PSNR is −0.70. It means the difference between the qualities of reconstructed images coded by the proposed MVC scheme and JMVM is tiny and imperceptible. However, the important and interesting fact is that
, which meets the requirements of HVS. Thus, the quality of the reconstructed images is improved. While evaluated by the regional selective image quality metrics, ΔPMOS_SSIM is 0.78 and ΔPMOS_PSNR is −0.70. It means the difference between the qualities of reconstructed images coded by the proposed MVC scheme and JMVM is tiny and imperceptible. However, the important and interesting fact is that  is 21.06%, which indicates that 21.06% bit rate saving is achieved by the proposed MVC scheme while comparing with JMVM benchmark. Similar results can also be found for Breakdancers, Doorflowers, Alt Moabit, and Dog sequence. For Pantomime and Champagne tower sequences, because the background regions are very flat and smooth, MBs in these regions are coded with SKIP/DIRECT mode and only very few bits are allocated by original JMVM, thus, a relative low saving ratio, 8.19% and 8.58%, is achieved by the proposed MVC.
is 21.06%, which indicates that 21.06% bit rate saving is achieved by the proposed MVC scheme while comparing with JMVM benchmark. Similar results can also be found for Breakdancers, Doorflowers, Alt Moabit, and Dog sequence. For Pantomime and Champagne tower sequences, because the background regions are very flat and smooth, MBs in these regions are coded with SKIP/DIRECT mode and only very few bits are allocated by original JMVM, thus, a relative low saving ratio, 8.19% and 8.58%, is achieved by the proposed MVC.
In summary, the proposed MVC scheme achieves significant bit-rate saving ratio, up to  ; meanwhile, the ROIs' image quality is improved up to
; meanwhile, the ROIs' image quality is improved up to  dB at the cost of imperceptible quality degradation at background regions. Additionally, PSNR_Y of ROI is better than that of background, which meets requirements of HVS. Moreover, the proposed MVC scheme can save over 20% bit rate with imperceptible image quality degradation according to the evaluation of region selective image quality metrics.
dB at the cost of imperceptible quality degradation at background regions. Additionally, PSNR_Y of ROI is better than that of background, which meets requirements of HVS. Moreover, the proposed MVC scheme can save over 20% bit rate with imperceptible image quality degradation according to the evaluation of region selective image quality metrics.
7. Conclusions
A stereoscopic visual attention- (SVA-) based regional bit allocation optimization scheme is proposed to improve the compression efficiency of MVC. We proposed a bottom-up SVA model to simulate the visual attention mechanisms of the human visual system with stereoscopic perception. This model adopts multiple low level perceptual stimuli, including color, intensity, orientation, motion, depth, and depth contrast. Then the semantic region-of-interest (ROI) is extracted based on the saliency maps of SVA. The proposed model is not only able to efficiently simulate stereoscopic visual attention of human eyes, but also can reduce noise in each stimulus channel. Based on the extracted semantic ROIs, a regional bit allocation optimization scheme is also proposed for high compression efficiency by exploiting visual redundancies. Experimental results on MVC showed that the proposed bit allocation algorithm can achieve over  bit-rate saving at high bit rate while maintaining the same objective image quality and subjective image qualities. Meanwhile, the image quality of ROIs is improved by
bit-rate saving at high bit rate while maintaining the same objective image quality and subjective image qualities. Meanwhile, the image quality of ROIs is improved by  dB at the cost of indiscriminate image quality degradation in background regions, which is less conspicuous and sensitive to human visual system. It can be foreseen that the stereoscopic visual attention will play a more important role in the areas such as content-oriented three-dimensional video processing, video retrieval, and computer vision in future.
dB at the cost of indiscriminate image quality degradation in background regions, which is less conspicuous and sensitive to human visual system. It can be foreseen that the stereoscopic visual attention will play a more important role in the areas such as content-oriented three-dimensional video processing, video retrieval, and computer vision in future.
References
Muller K, Merkle P, Wiegand T: Compressing time-varying visual content. IEEE Signal Processing Magazine 2007, 24(6):58-65.
Tanimoto M: Overview of free viewpoint television. Signal Processing: Image Communication 2006, 21(6):454-461. 10.1016/j.image.2006.03.009
Merkle P, Smolic A, Müller K, Wiegand T: Multi-view video plus depth representation and coding. Proceedings of the International Conference on Image Processing (ICIP '07), 2007, San Antonio, Tex, USA 1: 201-204.
Survey of algorithms used for multi-view video coding (MVC) ISO/IEC JTC1/SC29/WG11, N6909, Hong Kong, China, January 2005
Yea S, Vetro A: View synthesis prediction for multiview video coding. Signal Processing: Image Communication 2009, 24(1-2):89-100. 10.1016/j.image.2008.10.007
Yun Z, Jiang GY, Mei Y, Yo SH: Adaptive multiview video coding scheme based on spatiotemporal correlation analyses. ETRI Journal 2009, 31(2):151-161. 10.4218/etrij.09.0108.0350
Merkle P, Müller K: Efficient prediction structures for multiview video coding. IEEE Transactions on Circuits and Systems for Video Technology 2007, 17(11):1461-1473.
Lu Z, Lin W, Yang X, Ong E, Yao S: Modeling visual attention's modulatory aftereffects on visual sensitivity and quality evaluation. IEEE Transactions on Image Processing 2005, 14(11):1928-1942.
Ohm J-R: Encoding and reconstruction of multiview video objects. IEEE Signal Processing Magazine 1999, 16(3):47-54. 10.1109/79.768572
Han J, Ngan KN, Li M, Zhang H-J: Unsupervised extraction of visual attention objects in color images. IEEE Transactions on Circuits and Systems for Video Technology 2006, 16(1):141-145.
Ma Y-F, Hua X-S, Lu L, Zhang H-J: A generic framework of user attention model and its application in video summarization. IEEE Transactions on Multimedia 2005, 7(5):907-919.
Itti L, Koch C: Computational modelling of visual attention. Nature Reviews Neuroscience 2001, 2(3):194-203. 10.1038/35058500
Treisman AM, Gelade G: A feature-integration theory of attention. Cognitive Psychology 1980, 12(1):97-136. 10.1016/0010-0285(80)90005-5
Zhai G, Chen Q, Yang X, Zhang W: Scalable visual sensitivity profile estimation. Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP '08), April 2008, Las Vegas, Nev, USA 873-876.
Zhai Y, Shah M: Visual attention detection in video sequences using spatiotemporal cues. Proceedings of the 14th Annual ACM International Conference on Multimedia (MM '06), October 2006, Santa Barbara, Calif, USA 815-824.
Wang PP, Zhang W, Li J, Zhang Y: Realtime detection of salient moving object: a multi-core solution. Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP '06), April 2008, Las Vegas, Nev, USA 1481-1484.
Kaminsky E, Grois D, Hadar O: Dynamic computational complexity and bit allocation for optimizing H.264/AVC video compression. Journal of Visual Communication and Image Representation 2008, 19(1):56-74. 10.1016/j.jvcir.2007.05.002
Lu Y, Xie J, Li H, Cui H: GOP-level bit allocation using reverse dynamic programming. Tsinghua Science and Technology 2009, 14(2):183-188. 10.1016/S1007-0214(09)70028-8
Shen L, Liu Z, Zhang Z, Shi X: Frame-level bit allocation based on incremental PID algorithm and frame complexity estimation. Journal of Visual Communication and Image Representation 2009, 20(1):28-34. 10.1016/j.jvcir.2008.08.003
Özbek N, Tekalp AM: Content-aware bit allocation in scalable multi-view video coding. Proceedings of the Multimedia Content Representation, Classification and Security (MRCS '06), September 2006, Lecture Notes in Computer Sciences 4105: 691-698.
Chen Z, Han J, Ngi K: Dynamic bit allocation for multiple video object coding. IEEE Transactions on Multimedia 2006, 8(6):1117-1124.
Wang H, Schuster GM, Katsaggelos AK: Rate-distortion optimal bit allocation for object-based video coding. IEEE Transactions on Circuits and Systems for Video Technology 2005, 15(9):1113-1123.
Chi M-C, Chen M-J, Yeh C-H, Jhu J-A: Region-of-interest video coding based on rate and distortion variations for H.263+. Signal Processing: Image Communication 2008, 23(2):127-142. 10.1016/j.image.2007.12.001
Tang C-W, Chen C-H, Yu Y-H, Tsai C-J: Visual sensitivity guided bit allocation for video coding. IEEE Transactions on Multimedia 2006, 8(1):11-18.
Kauff P, Atzpadin N, Fehn C, Müller M, Schreer O, Smolic A, Tanger R: Depth map creation and image-based rendering for advanced 3DTV services providing interoperability and scalability. Signal Processing: Image Communication 2007, 22(2):217-234. 10.1016/j.image.2006.11.013
Zhang Y, Jiang G, Yu M, Chen K: Stereoscopic visual attention model for 3D video. Proceedings of the International Multimedia Modeling Conference (MMM '10), January 2010, Lecture Notes in Computer Sciences 5916: 314-324.
Itti L, Koch C, Niebur E: A model of saliency-based visual attention for rapid scene analysis. IEEE Transactions on Pattern Analysis and Machine Intelligence 1998, 20(11):1254-1259. 10.1109/34.730558
Barron JL, Fleet DJ, Beauchemin SS: Performance of optical flow techniques. International Journal of Computer Vision 1994, 12(1):43-77. 10.1007/BF01420984
Itti L, Koch C: Feature combination strategies for saliency-based visual attention systems. Journal of Electronic Imaging 2001, 10(1):161-169. 10.1117/1.1333677
Tanimoto M, Fujii T, Suzuki K: Improvement of depth map estimation and view synthesis. ISO/IEC JTC1/SC29/WG11, M15090, Antalya, Turkey, January 2008
Qi F, Wu JJ, Shi GM: Extracting regions of attention by imitating the human visual system. Proceedings of the IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP '09), April 2009, Taipei, Taiwan 1905-1908.
Zhang Y, Jiang GY, Yu M, Yang Y, Peng ZJ, Chen K: Depth perceptual region-of-interest based multiview video coding. Journal of Visual Communication and Image Representation 2010, 21(5-6):498-512. 10.1016/j.jvcir.2010.03.002
Takagi K, Takishima Y, Nakajima Y: A study on rate distortion optimization scheme for JVT coder. Visual Communication and Image Processing, July 2003, Lugano, Switzerland, Proceedings of SPIE 5150: 914-923.
Engelke U, Nguyen VX, Zepernick H-J: Regional attention to structural degradations for perceptual image quality metric design. Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP '08), March 2008, Las Vegas, Nev, USA 869-872.
Wang Z, Bovik AC, Sheikh HR, Simoncelli EP: Image quality assessment: from error visibility to structural similarity. IEEE Transactions on Image Processing 2004, 13(4):600-612. 10.1109/TIP.2003.819861
Feldmann I, Mueller M, Zilly F, et al.: HHI test material for 3D video. ISO/IEC JTC1/SC29/WG11, M15413, Archamps, France, April 2008
Zitnick CL, Kang SB, Uyttendaele M, Winder S, Szeliski R: High-quality video view interpolation using a layered representation. In Proceedings of ACM SIGGRAPH Transactions on Graphics, August 2004, Los Angeles, Calif, USA. ACM; 600-608.
Tanimoto M, Fujii T, Fukushima N: 1D parallel test sequences for MPEG-FTV. ISO/IEC JTC1/SC29/WG11, M15378, Archamps, France, April 2008
Stankiewicz O, Wegner K: Depth map estimation software version 2. ISO/IEC JTC1/SC29/WG11, M15338, Archamps, France, April 2008
ITU-R Recommendation BT.500-11 : Methodology for the subjective assessment of the quality of television pictures. 2002.
Rajae-Joordens R, Engel J: Paired comparisons in visual perception studies using small sample sizes. Displays 2005, 26(1):1-7. 10.1016/j.displa.2004.09.003
Vetro A, Pandit P, Kimata H, Smolic A, Wang YK: Joint multiview video model (JMVM) 7.0. Joint Video Team of ITU-T VCEG and ISO/IEC MPEG, Antalya, Turkey; January 2008.
Bjontegaard G: Calculation of average PSNR differences between RD-curves. ITU-T VCEG, VCEG-M33, April 2001
Acknowledgments
The Interactive Visual Media Group at Microsoft Research, HHI, and Nagoya University have kindly provided The authors with multiview video sequences and depth maps. Thanks are due to Dr. Sam Kwong for giving us many good suggestions and help. This work is supported by the Natural Science Foundation of China (Grant 60872094, 60832003), 863 Project of China (2009AA01Z327). It was also sponsored by K.C.Wong Magna Fund in Ningbo University.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License ( https://creativecommons.org/licenses/by/2.0 ), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Zhang, Y., Jiang, G., Yu, M. et al. Stereoscopic Visual Attention-Based Regional Bit Allocation Optimization for Multiview Video Coding. EURASIP J. Adv. Signal Process. 2010, 848713 (2010). https://doi.org/10.1155/2010/848713
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1155/2010/848713