- Research Article
- Open access
- Published:
Robust Real-Time Background Subtraction Based on Local Neighborhood Patterns
EURASIP Journal on Advances in Signal Processing volume 2010, Article number: 901205 (2010)
Abstract
This paper describes an efficient background subtraction technique for detecting moving objects. The proposed approach is able to overcome difficulties like illumination changes and moving shadows. Our method introduces two discriminative features based on angular and modular patterns, which are formed by similarity measurement between two sets of RGB color vectors: one belonging to the background image and the other to the current image. We show how these patterns are used to improve foreground detection in the presence of moving shadows and in the case when there are strong similarities in color between background and foreground pixels. Experimental results over a collection of public and own datasets of real image sequences demonstrate that the proposed technique achieves a superior performance compared with state-of-the-art methods. Furthermore, both the low computational and space complexities make the presented algorithm feasible for real-time applications.
1. Introduction
Moving object detection is a crucial part of automatic video surveillance systems. One of the most common and effective approach to localize moving objects is background subtraction, in which a model of the static scene background is subtracted from each frame of a video sequence. This technique has been actively investigated and applied by many researchers during the last years [1–3]. The task of moving object detection is strongly hindered by several factors such as shadows cast by moving object, illuminations changes, and camouflage. In particular, cast shadows are the areas projected on a surface because objects are occluding partially or totally direct light sources. Obviously, an area affected by cast shadow experiences a change of illumination. Therefore in this case the background subtraction algorithm can misclassify background as foreground [4, 5]. Camouflage occurs when there is a strong similarity in color between background and foreground; so foreground pixels are classified as background. Broadly speaking, these issues rise problems such as shape distortion, object merging, and even object losses. Thus a robust and accurate algorithm to segment moving object is highly desirable.
In this paper, we present an adaptive background model, which is formed by temporal and spatial components. These components are basically computed by measuring the angle and the Euclidean distance between two sets of color vectors. We will show how these components are combined to improve the robustness and the discriminative sensitivity of the background subtraction algorithm in the presence of  moving shadows and
moving shadows and  strong similarities in color between background and foreground pixels. Another important advantage of our algorithm is its low computational complexity and its low space complexity that makes it feasible for real-time applications.
strong similarities in color between background and foreground pixels. Another important advantage of our algorithm is its low computational complexity and its low space complexity that makes it feasible for real-time applications.
The rest of the paper is organized as follows. Section 2 introduces a brief literature review. Section 3 presents our method. In Section 4 experimental results are discussed. Concluding remarks are available in Section 5.
2. Related Work
Many publications are devoted to the background subtraction technique [1–3]. However in this section we consider only the papers that are directly related to our work.
Haritaoglu et al. state that in W4 [6] the background is modeled by representing each pixel by three values: its minimum and maximum intensity values and the maximum intensity differences between consecutive frames observed during this training period. Pixels are classified as foreground if the differences between the current value and the minimum and maximum values are greater than the values of the maximal interframe difference. However, this approach is rather sensitive to shadows and lighting changes, since the only illumination intensity cue is used and the memory resource to implement this algorithm is extremely high.
Horprasert et al. [7] implement a statistical color background algorithm, which use color chrominance and brightness distortion. The background model is built using four values: the mean, the standard deviation, the variation of the brightness, and chrominance distortion. However, this approach usually fails for low and high intensities.
Kim et al. [8] use a similar approach as [7], but they obtain more robust motion segmentation in the presents of the illumination and scene changes using background model with codebooks. The codebooks idea gives the possibility to learn more about the model in the training period. The authors propose to cope with the unstable information of the dark pixels, but still they have some problems in the low- and the high-intensity regions. Furthermore, the space complexity of their algorithm is high.
Stauffer and Grimson [9] address the low- and the high-intensity regions problem by using a mixture of Gaussians to build a background color model for every pixel. Pixels from the current frame are checked against the background model by comparing them with every Gaussian in the model until a matching Gaussian is found. If so, the mean and variance of the matched Gaussian are updated; otherwise a new Gaussian with the mean equal to the current pixel color and some initial variance is introduced into the mixture.
McKenna et al. [10] assume that cast shadows result in significant change in intensity without much change in chromaticity. Pixel chromaticity is modeled using its mean and variance and the first-order gradient of each background pixel modeled using gradient means and magnitude variance. Moving shadows are then classified as background if the chromaticity or gradient information supports their classification.
Cucchiara et al. [11] use a model in Hue-Saturation-Value (HSV) and stress their approach in shadow suppression. The idea is that shadows change the hue component slightly and decrease the saturation component significantly. In the HSV color space a more realistic noise model can be done. However, this approach also has drawbacks. The similarity measured in the nonlinear HSV color space usually generates ambiguity at gray levels. Furthermore threshold handling is the major limitation of this approach.
3. Proposed Algorithm
A simple and common background subtraction procedure involves subtraction of each new image from a static model of the scene. As a result a binary mask with two labels (foreground and background) is formed for each pixel in the image plane. Broadly speaking, this technique can be separated in two stages, one dealing with the scene modeling and another with the motion detection process. The scene modeling stage represents a crucial part in the background subtraction technique [12–17].
Usually a simple unimodal approach uses statistical parameters such as mean and standard deviation values, for example, [7, 8, 10], and so forth. Such statistical parameters are obtained during a training period and then these are dynamically updated. In the background modeling process the statistical values depend on both the low- and high-frequency changes of the camera signal. If the standard deviations of the low- and high-frequency components of the signal are comparable, methods based on such statistical parameters exhibit robust discriminability. When the standard deviation of the high-frequency change is significantly less than the low-frequency change, then the background model can be improved to make the discriminative sensitivity much higher. Since a considerable change in the low-frequency domain is produced for the majority of real video sequences, we propose to build a model that is insensitive to low-frequency changes. The main idea is to estimate only the high-frequency change per each pixel value as one interframe interval. The general background model in this case can be explained as the subtraction between the current frame and the previous frame, which suppose to be the background image. Two values for each pixel in the image are computed to model background changes during the training period: the maximum difference in angular and Euclidean distances between the color vectors of the consecutive image frames. The angular difference is used because it can be considered as photometric invariant of color measurement and in turn as significant cues to detect moving shadows.
Often pixelwise comparison is not enough to distinguish background from foreground and in our classification process we further analyze the neighborhood of each pixel position. In the next section we give a formal definition of the proposed similarity measurements.
3.1. Background Scene Modeling
3.1.1. Similarity Measurements
Four similarity measurements are used to compare a background image with a current frame.
-
(i)
Angular similarity measurement
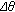 between two color vectors
between two color vectors 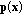 and
and 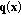 at position x in the RGB color space is defined as follows:
at position x in the RGB color space is defined as follows: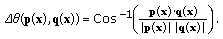 (1)
(1) -
(ii)
Euclidean distance similarity measurement
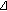 I between two color vectors
I between two color vectors  and
and 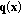 in the RGB color space is defined as follows:
in the RGB color space is defined as follows: (2)
(2)For each of the described similarity measurements a threshold function is associated:
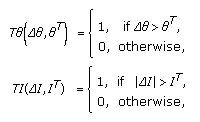 (3)
(3)where
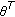 and
and 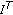 are intrinsic parameters of the threshold functions of the similarity measurements.
are intrinsic parameters of the threshold functions of the similarity measurements.To describe a neighbourhood similarity measurem-ent let us first characterize the index vector
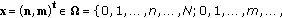
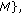 which define the position of a pixel in the image. Also we need to name the neighbourhood radius vector
which define the position of a pixel in the image. Also we need to name the neighbourhood radius vector 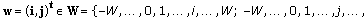
 which define the positions of pixels that belong to the neighbourhood relative to any current pixel. Indeed, the domain
which define the positions of pixels that belong to the neighbourhood relative to any current pixel. Indeed, the domain 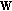 is just a square window around a chosen pixel.
is just a square window around a chosen pixel. -
(iii)
Angular neighborhood similarity measurement
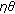 between two sets of color vectors in the RGB color space
between two sets of color vectors in the RGB color space 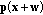 and
and 
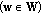 can be written as
can be written as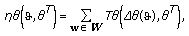 (4)
(4)where
 ,
, 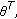 and
and 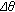 are defined in (3) and (1), respectively, and
are defined in (3) and (1), respectively, and  is (
is ( ,
, 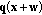 ).
). -
(iv)
Euclidean distance neighborhood similarity measurement
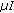 between two sets of color vectors in the RGB color space
between two sets of color vectors in the RGB color space 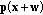 and
and 
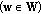 can be written as
can be written as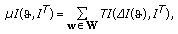 (5)
(5)where
 ,
,  and
and 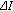 are defined in (3) and (2), respectively. With each of the neighbourhood similarity measurements we associate a threshold function:
are defined in (3) and (2), respectively. With each of the neighbourhood similarity measurements we associate a threshold function: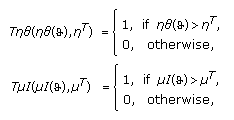 (6)
(6)where
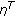 and
and 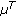 are intrinsic parameters of the threshold functions of the neighborhood similarity measurements.
are intrinsic parameters of the threshold functions of the neighborhood similarity measurements.
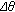 between two color vectors
between two color vectors 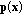 and
and 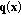 at position x in the RGB color space is defined as follows:
at position x in the RGB color space is defined as follows: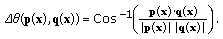
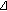 I between two color vectors
I between two color vectors  and
and 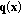 in the RGB color space is defined as follows:
in the RGB color space is defined as follows:
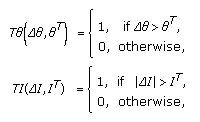
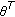 and
and 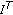 are intrinsic parameters of the threshold functions of the similarity measurements.
are intrinsic parameters of the threshold functions of the similarity measurements.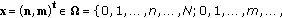
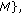 which define the position of a pixel in the image. Also we need to name the neighbourhood radius vector
which define the position of a pixel in the image. Also we need to name the neighbourhood radius vector 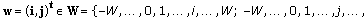
 which define the positions of pixels that belong to the neighbourhood relative to any current pixel. Indeed, the domain
which define the positions of pixels that belong to the neighbourhood relative to any current pixel. Indeed, the domain 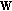 is just a square window around a chosen pixel.
is just a square window around a chosen pixel.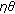 between two sets of color vectors in the RGB color space
between two sets of color vectors in the RGB color space 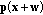 and
and 
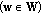 can be written as
can be written as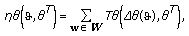
 ,
, 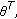 and
and 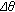 are defined in (3) and (1), respectively, and
are defined in (3) and (1), respectively, and  is (
is ( ,
, 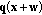 ).
).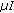 between two sets of color vectors in the RGB color space
between two sets of color vectors in the RGB color space 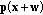 and
and 
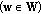 can be written as
can be written as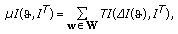
 ,
,  and
and 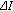 are defined in (3) and (2), respectively. With each of the neighbourhood similarity measurements we associate a threshold function:
are defined in (3) and (2), respectively. With each of the neighbourhood similarity measurements we associate a threshold function: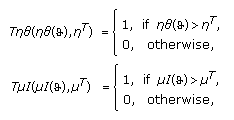
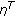 and
and 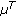 are intrinsic parameters of the threshold functions of the neighborhood similarity measurements.
are intrinsic parameters of the threshold functions of the neighborhood similarity measurements.3.1.2. Scene Modeling
Our background model (BG) will be represented with two classes of components, namely, running components (RCs) and training components (TCs). The RC is a color vector in RGB space and only this component can be updated in running process. The TC is a set of fixed thresholds values obtained during the training.
The background model is represented by

where  is maxima of the chromaticity variation;
is maxima of the chromaticity variation;  is maxima of the intensity variation;
is maxima of the intensity variation;  is the half size of the neighbourhood window.
is the half size of the neighbourhood window.
A training process has to be performed to obtain the background parameters defined by (7). This first step consists of estimating the value of the RC and TC during the training period. To initialize our  we put the
we put the  as the initial frame.
as the initial frame.  and
and  are estimated during the training period by computing the angular difference and the Euclidean distance between the pixel belonging to the previous frame and the pixel belonging to the current frame:
are estimated during the training period by computing the angular difference and the Euclidean distance between the pixel belonging to the previous frame and the pixel belonging to the current frame:

where  is the number of frames in the training period.
is the number of frames in the training period.
3.2. Classification Process
Our classification rules consist of two steps.
Step One
Pixels that have strong dissimilarity with the background are classified directly as foreground, in the case when the following rule expression is equal to 1 (TRUE):

where  and
and  are experimental scale factors. Otherwise, when (9) is not TRUE, the classification has to be done in the following step.
are experimental scale factors. Otherwise, when (9) is not TRUE, the classification has to be done in the following step.
Step Two
This step consists of two test rules. One verifies a test pixel for the shadow class (10) and another verifies for the foreground class (11):


The rest of the pixels that are not classified as shadow or foreground pixels must be classified as background pixels. Figure 1 illustrates the classification regions. All the implemented thresholds were obtained on the base of a tuning process with different video sequences (



 and
and  ).
).

(a) Angle and magnitude difference between two color vector in RGB space. (b) Difference in angle and magnitude in 2D "polar difference space." The axes are computed as  and
and 
3.3. Model Updating
In order to maintain the stability of the background model through the time, the model needs to be dynamically updated. As it was explained before, only the RCs have to be updated. The update process is done at every frame, but only in the case when the updated pixels are classified as a background. The model is updated as follows:

where  is the updated rate. Due to our experiments the value of this parameter has to be
is the updated rate. Due to our experiments the value of this parameter has to be  = 0.45.
= 0.45.
4. Experimental Results
In this section we present the performance of our approach in terms of quantitative and qualitative results applied to 5 well-known datasets taken from 7 different video sequences: PETS 2009 (http://www.cvg.rdg.ac.uk/ (View 7 and 8)), ATON (http://cvrr.ucsd.edu/aton/shadow/ (Laboratory and Intelligentroom)), ISELAB (http://iselab.cvc.uab.es (ETSE Outdoor)), LVSN (http://vision.gel.ulaval.ca/CastShadows/ (HallwayI)), and VSSN, (http://mmc36.informatik.uni-augsburg.de/VSSN06_OSAC/).
Quantitative Results
We have applied our proposed algorithm in several indoor and outdoor video scenes. Ground-truth masks have been manually extracted to numerically evaluate and compare the performance of our proposed technique with respect to most similar state-of-the-art approaches [6–9]. Two metrics were considered to evaluate the segmentation results, namely, False Positive Error (FPE) and False Negative Error (FNE). FPE means that the background pixels were set as Foreground while FNE indicates that foreground pixels were identified as Background. We show this comparison in terms of accuracy in Figure 2:


Segmentation errors. (a) FPE and (b) FNE.
Qualitative Results
Figure 3 shows a visual comparison between our techniques and some well-known methods. It can be seen that our method performs better in terms of camouflage areas segmentation and suppressing strong shadows. In Figure 4 also visual results are shown. In this case we have applied our method in several sequences. It can be seen that the foreground objects are detected without shadows, in such a way preserving their shape properly.

(a) Original image, segmentation result of (b) our method, (c) Stauffer method, and (d) K. Kim method.

Sample visual results of our background subtraction algorithm in various environment. (a) Background Image, (b) Current Image, and (c) Foreground (red) /Shadows (green) /Background (black) detection. (1) PETS 2009 View 7, (2) PETS 2009 View 8, (3) ATON (Laboratory), (4) ISELAB (ETSE Outdoor), (5) LVSN (HallwayI), (6) VSSN, and (7) ATON (Intelligentroom).
5. Conclusions
This paper proposes an efficient background subtraction technique which overcomes difficulties like illumination changes and moving shadows. The main novelty of our method is the incorporation of two discriminative similarity measures based on angular and Euclidean distance patterns in local neighborhoods. Such patterns are used to improve foreground detection in the presence of moving shadows and strong similarities in color between background and foreground. Experimental results over a collection of public and own datasets of real image sequences demonstrate the effectiveness of the proposed technique. The method shows an excellent performance in comparison with other methods. Most recent approaches are based on very complex models designed to achieve an extremely effective classification; however these approaches become unfeasible for real-time applications. Alternatively, our proposed method exhibits low computational and space complexities that make our proposal very appropriate for real-time processing in surveillance systems with low-resolution cameras or Internet web-cams.
References
Karaman M, Goldmann L, Yu D, Sikora T: Comparison of static background segmentation methods. Visual Communications and Image Processing, 2005, Proceedings of SPIE 5960(4):2140-2151.
Piccardi M: Background subtraction techniques: a review. Proceedings of the IEEE International Conference on Systems, Man and Cybernetics (SMC '04), October 2004, The Hague, The Netherlands 4: 3099-3104.
McIvor A: Background subtraction techniques. Proceedings of the International Conference on Image and Vision Computing, 2000, Auckland, New Zealand
Prati A, Mikic I, Trivedi MM, Cucchiara R: Detecting moving shadows: algorithms and evaluation. IEEE Transactions on Pattern Analysis and Machine Intelligence 2003, 25(7):918-923. 10.1109/TPAMI.2003.1206520
Obinata G, Dutta A: Vision Systems: Segmentation and Pattern Recognition. I-TECH Education and Publishing, Vienna, Austria; 2007.
Haritaoglu I, Harwood D, Davis LS: W4: real-time surveillance of people and their activities. IEEE Transactions on Pattern Analysis and Machine Intelligence 2000, 22(8):809-830. 10.1109/34.868683
Hoprasert T, Harwood D, Davis LS: A statistical approach for real-time robust background subtraction and shadow detection. Proceedings of the 7th IEEE International Conference on Computer Vision, Frame Rate Workshop (ICCV '99), September 1999, Kerkyra, Greece 4: 1-9.
Kim K, Chalidabhongse TH, Harwood D, Davis L: Real-time foreground-background segmentation using codebook model. Real-Time Imaging 2005, 11(3):172-185. 10.1016/j.rti.2004.12.004
Stauffer C, Grimson WEL: Learning patterns of activity using real-time tracking. IEEE Transactions on Pattern Analysis and Machine Intelligence 2000, 22(8):747-757. 10.1109/34.868677
McKenna SJ, Jabri S, Duric Z, Rosenfeld A, Wechsler H: Tracking groups of people. Computer Vision and Image Understanding 2000, 80(1):42-56. 10.1006/cviu.2000.0870
Cucchiara R, Grana C, Piccardi M, Prati A, Sirotti S: Improving shadow suppression in moving object detection with HSV color information. Proceedings of the IEEE Intelligent Transportation Systems Proceedings, August 2001, Oakland, Calif, USA 334-339.
Toyama K, Krumm J, Brumitt B, Meyers B: Wallflower: principles and practice of background maintenance. Proceedings of the 7th IEEE International Conference on Computer Vision (ICCV '99), September 1999, Kerkyra, Greece 1: 255-261.
Elgammal A, Harwood D, Davis LS: Nonparametric background model for background subtraction. Proceedings of the European Conference on Computer Vision (ECCV '00), 2000, Dublin, Ireland 751-767.
Mittal A, Paragios N: Motion-based background subtraction using adaptive kernel density estimation. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR '04), July 2004, Washington, DC, USA 2: 302-309.
Chen Y-T, Chen C-S, Huang C-R, Hung Y-P: Efficient hierarchical method for background subtraction. Pattern Recognition 2007, 40(10):2706-2715. 10.1016/j.patcog.2006.11.023
Li L, Huang W, Gu IY-H, Tian Q: Statistical modeling of complex backgrounds for foreground object detection. IEEE Transactions on Image Processing 2004, 13(11):1459-1472. 10.1109/TIP.2004.836169
Zhong J, Sclaroff S: Segmenting foreground objects from a dynamic textured background via a robust Kalman filter. Proceedings of the 9th IEEE International Conference on Computer Vision (ICCV '03), October 2003, Nice, France 44-50.
Acknowledgments
This work has been supported by the Spanish Research Programs Consolider-Ingenio 2010:MIPRCV (CSD200700018) and Avanza I+D ViCoMo (TSI-020400-2009-133) and by the Spanish projects TIN2009-14501-C02-01 and TIN2009-14501-C02-02.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License ( https://creativecommons.org/licenses/by/2.0 ), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Amato, A., Mozerov, M.G., Roca, F.X. et al. Robust Real-Time Background Subtraction Based on Local Neighborhood Patterns. EURASIP J. Adv. Signal Process. 2010, 901205 (2010). https://doi.org/10.1155/2010/901205
Received:
Accepted:
Published:
DOI: https://doi.org/10.1155/2010/901205