- Research
- Open access
- Published:
Superimposed signaling inspired channel estimation in full-duplex systems
EURASIP Journal on Advances in Signal Processing volume 2018, Article number: 8 (2018)
Abstract
Residual self-interference (SI) cancellation in the digital baseband is an important problem in full-duplex (FD) communication systems. In this paper, we propose a new technique for estimating the SI and communication channels in a FD communication system, which is inspired from superimposed signaling. In our proposed technique, we add a constant real number to each constellation point of a conventional modulation constellation to yield asymmetric shifted modulation constellations with respect to the origin. We show mathematically that such constellations can be used for bandwidth efficient channel estimation without ambiguity. We propose an expectation maximization (EM) estimator for use with the asymmetric shifted modulation constellations. We derive a closed-form lower bound for the mean square error (MSE) of the channel estimation error, which allows us to find the minimum shift energy needed for accurate channel estimation in a given FD communication system. The simulation results show that the proposed technique outperforms the data-aided channel estimation method, under the condition that the pilots use the same extra energy as the shift, both in terms of MSE of channel estimation error and bit error rate. The proposed technique is also robust to an increasing power of the SI signal.
1 Introduction
1.1 Background
Full-duplex (FD) communication, allowing devices to transmit and receive over the same temporal and spectral resources, is a promising mechanism to potentially double the spectral efficiency of future wireless communication systems [1]. The main challenge in implementing a FD communication system is the cancellation of the strong self-interference (SI) signal, which is caused by transmission and reception in a single frequency band [2, 3]. This strong self-interference signal has to be suppressed to the receiver noise floor in order to ensure that it does not degrade the system performance. For instance, for small-cells in Long Term Evolution (LTE), the maximum transmit power is typically 23 dBm (200 mW) and the typical noise floor is − 90 dBm [4]. Ideally, this requires a total of 113 dB SI cancellation for realizing the full potential of FD systems [4].
Recently, there has been a lot of interest in SI cancellation techniques for FD systems [5–11]. The SI cancellation techniques in the literature can be divided into two main categories [5]: (i) passive suppression in which the SI signal is suppressed by suitably isolating the transmit and receive antennas [5, 6] and (ii) active cancellation which uses knowledge of the SI signal to cancel the interference in either the analog domain (i.e., before the signal passes through the analog-to-digital converter) [5, 7] and/or the digital domain [8–10]. Depending upon the design, passive suppression and analog cancellation can provide about 40–60 dB cancellation in total [11]. Hence, in practice, the SI is cancelled in multiple stages, beginning with passive suppression and followed by cancellation in the analog and digital domains. In this paper, we focus on the SI after the passive suppression and analog cancellation, termed residual SI.
1.2 Motivation and related work
The residual SI can still be relatively strong in the baseband digital signal, e.g., for the LTE small-cell example, it can be as high as 50 dB assuming state-of-the-art passive suppression and analog cancellation provide 60 dB of the total required SI cancellation of 113 dB. Thus, accurate digital SI cancellation is required to bring the SI as close to the noise floor as possible. The effectiveness of any digital interference cancellation technique depends strongly on the quality of the available channel estimates for both the SI and desired communication channels [12–14]. Typically, the baseband channels are estimated by using data-aided channel estimation techniques, where a portion of the data frame is allocated for known training sequences or pilot symbols [13, 15–17]. In this regard, a maximum-likelihood (ML) approach was proposed in [13] to jointly estimate the residual SI and communication channels by exploiting the known transmitted symbols and both the known pilot and unknown data symbols from the other intended transceiver. Another approach was proposed in [18] where a sub-space-based algorithm was developed to jointly estimate the residual SI and communication channels.
Compared to half-duplex (HD) systems, data-aided channel estimation in FD systems can be bandwidth inefficient. This is because, firstly, two channels need to be estimated and, secondly, accurate channel estimation requires a larger number of pilots [19, 20]. A bandwidth efficient channel estimation technique in HD systems is superimposed training, where no explicit time slots are allocated for channel estimation. Instead, a periodic low power training sequence is superimposed with the data symbols at the transmitter before modulation and transmission [21, 22]. The downside of this approach is that some power is consumed in superimposed training which could have otherwise been allocated to the data transmission. This lowers the effective signal-to-noise ratio (SNR) for the data symbols and affects the bit error rate (BER) at the receiver. In contrast to data-aided and superimposed training-based channel estimation techniques, blind techniques avoid the use of pilots altogether by exploiting statistical and other properties of the transmitted signal [23–27]. However, blind estimators can only estimate the channel up to a scaling factor and cannot recover the channel phases [23]. The necessary and sufficient conditions for ambiguity-free blind estimation can be determined using identifiability analysis, which determines whether a parameter can be uniquely estimated without any ambiguity [19, 23, 28–30]. To the best of our knowledge, bandwidth efficient and accurate channel estimation methods for FD systems are still an important open area of research.
1.3 Paper contributions
In this paper, we consider the problem of bandwidth efficient channel estimation in a single-input single-output (SISO) FD communication system. We propose a new technique for channel estimation and residual SI cancellation in FD systems. Our approach draws inspiration from (i) blind channel estimation techniques in that we examine the condition for identifiability of channel parameters in FD systems and (ii) superimposed signaling in that we superimpose (i.e., add) a constant real number to each constellation point of the modulation constellation. However, our proposed technique is distinct from superimposed signaling. In superimposed signaling, the superimposed signal is typically a periodic training sequence that is added to the data signal after the data symbols are modulated. Hence, the additional power of the superimposed signal is only used for channel estimation. In our proposed technique, the superimposed signal is a constant (non-random) signal and the objective is to shift the modulation constellation away from the origin, which we exploit for estimating the SI and communication channels without ambiguity. In addition, the additional power of the superimposed signal is used for both modulating the data symbols and channel estimation, which does not reduce the effective SNR as in superimposed signaling. The novel contributions are as follows:
-
We derive the condition for identifiability of channel parameters in a FD system (cf. Theorem 1) and show that symmetric modulation constellations with respect to the origin cannot be used for ambiguity-free channel estimation in a FD system. Based on Theorem 1, our proposed technique is able to resolve the inherent ambiguity of blind channel estimation in FD communication via shifting the modulation constellation away from origin.
-
Using the proposed technique, we derive a computationally efficient expectation maximization (EM) estimator for simultaneous estimation of both SI and communication channels. We derive a lower bound for the channel estimation error, which depends on the energy used for shifting the modulation constellations, and use it to find the minimum signal energy needed for accurate channel estimation in a given FD communication system.
-
We use simulations to compare the performance of the proposed technique against that of the data-aided channel estimation method, under the condition that the pilots use the same extra power as the shift. Our results show that the proposed technique performs better than the data-aided channel estimation method both in terms of the mean square error (MSE) of channel estimation and BER. In addition, the proposed technique is robust to an increasing SI power.
1.4 Notation and paper organization
The following notation is used in this paper. Capital letters are used for random variables, and lower case letters are used for their realizations. f Y (y) denotes the probability density function (PDF) of random variable Y. \(\mathbb {E}_{Y}[\!\cdot ]\) denotes the expectation with respect to the random variable Y. p X (x) denotes the probability mass function (PMF) of a discrete random variable X, and P(X=a) is the probability of the discrete random variable X taking the value a. \(\mathcal {CN}\left (\mu,\sigma ^{2}\right)\) denotes a complex Gaussian distribution with mean μ and variance σ2. Bold face capital letters, e.g., Y, are used for random vectors, and bold face lower case letters, e.g., y, are used for their realizations. Capital letters in upright Roman font, e.g., G, are used for matrices. Lower case letters in upright Roman font, e.g., g, are used for functions. I N represents the N×N identity matrix. [·]T denotes vector and matrix transpose. \(\mathrm {j}\triangleq \sqrt {-1}\) and the real and imaginary parts of a complex quantity are represented by ℜ{·} and I{·}, respectively. z∗ and |z| indicate scalar complex conjugate and the absolute value of complex number z, respectively. Finally, det(·) is the determinant operator.
This paper is organized as follows. The system model is presented in Section 2. The channel estimation problem and the proposed technique are formulated in Section 3. The EM estimator and the lower bound on the channel estimator error are derived in Section 4. The performance of the proposed technique is assessed in Section 5. Finally, conclusions are presented in Section 6.
2 System model
Consider the channel estimation problem for a SISO FD communication system between two nodes a and b, as illustrated in Fig. 1. Transceiver nodes a and b are assumed to have passive suppression and analog cancellation stages, and we only consider the digital cancellation to remove the residual SI, i.e., the SI, which is still present after the passive suppression and analog cancellation. We consider the received signal available at the output of the analog-to-digital converter (ADC). The received signal at node a is given byFootnote 1
where \(\mathbf {x}_{\mathbf {a}}\triangleq \left [x_{a_{1}},\cdots, x_{a_{N}}\right ]^{T}\) and \(\mathbf {x}_{\mathbf {b}}\triangleq \left [x_{b_{1}},\cdots, x_{b_{N}}\right ]^{T}\) are the N×1 vectors of transmitted symbols from nodes a and b, respectively, \(\mathbf {y}_{\mathbf {a}}\triangleq \left [y_{a_{1}},\cdots, y_{a_{N}}\right ]^{T} \) is the N×1 vector of observations, w a is the noise vector, which is modeled by N independent Gaussian random variables, i.e., \(f_{\mathbf {W}_{\mathbf {a}}}(\mathbf {w}_{\mathbf {a}}) = \mathcal {CN}\left (\mathbf {0},\sigma ^{2} \mathrm {I}_{N}\right)\), and h aa and h ba are the residual SI and communication channel gains, respectively. Furthermore, we model h aa and h ba as independent random variables that are constant over one frame of data and change independently from frame to frame [12].
Remark 1
Including all the hardware impairments and unknown parameters in mathematical modeling of parameter estimation problem in FD communication results in a highly non-linear system model, which may not have a tractable solution. The current approach is to separate the estimation of the linear and non-linear parameters [13,18]. In this paper, we focus on the estimation of linear parameters, while the estimation of non-linear parameters can be the topic of future works.
2.1 Modulation assumptions and definitions
In this paper, we assume that the transmitted symbols are all equiprobable and call the set \(\mathcal {A}\triangleq \{x_{1},x_{2},...,x_{M}\}\), which contains an alphabet of M constellation points, a modulation set. Let \(\mathcal {K} \triangleq \{1,\cdots,M\}\) denote set of indices of the constellation points.
We define E as the average symbol energy of a given constellation, i.e.,
where \(x_{k} \in \mathcal {A}\). Note that the average symbol energy can be related to the average bit energy as \(E_{b} \triangleq E/\log _{2}(M)\).
3 Channel estimation for FD systems
In this section, we first formulate the blind channel estimation problem for the FD system considered in Section 2. Based on this formulation, we present a theorem which provides the necessary and sufficient condition for ambiguity-free channel estimation. Finally, we discuss the proposed technique to resolve the ambiguity problem.
3.1 Problem formulation
Without loss of generality, we consider the problem of baseband channel estimation at node a only (similar results apply at node b). In formulating the problem, we make the following assumptions: (i) the transmitter is aware of its own signal, i.e., x a is known at node a, which is a commonly adopted assumption in the literature [3,5], (ii) the interference channel h aa and the communication channel h ba are unknown deterministic parameters, (iii) the transmit symbol from node b is modeled using a discrete random distribution, and (iv) we observe N independent received symbols.
The blind channel estimation problem requires the knowledge of the joint probability density function (PDF) of all observations, which is derived from the conditional PDF of a single observation. Given the system model in (1), the conditional PDF of a single observation is given by
where \(i \in \mathcal {I}\triangleq \{1,\cdots,N\}\), \(y_{a_{i}}\) is the ith received symbol, and \(x_{a_{i}}\) and \(x_{b_{i}}\) are the ith transmitted symbols from nodes a and b, respectively.
The marginal PDF of a single observation is then found by multiplying (3) by the uniform distribution \(p_{X_{b_{i}}}(x_{b_{i}})=\frac {1}{M}\mathbb {I}_{\{\mathcal {A}\}}(x_{b_{i}})\), and summing the results over all the possible values of \(x_{b_{i}}\), where, \(\mathbb {I}_{\{\mathcal {A}\}}(x) =1\) if \(x\in \mathcal {A}\) and 0 otherwise. Therefore, we have
where the last step follows from the fact that \(\mathbb {I}_{\{\mathcal {A}\}}(x_{b_{i}})=1\) if and only if \(x_{b_{i}}=x_{k}\), where \(x_{k} \in \mathcal {A}\). Finally, since the transmitted symbols are assumed independent, and we observe N independent observations, the joint PDF of all the observations is given by
where we substitute the value of \(f_{Y_{a_{i}}}(y_{a_{i}};h_{aa},h_{ba})\) from (4).
Using (5), we can state the channel estimation problem as shown in the proposition below.
Proposition 1
The blind maximum likelihood (ML) channel estimation problem in a SISO FD system is given by
where \(\phantom {\dot {i}\!}f_{\mathbf {Y}_{\mathbf {a}}}(\mathbf {y}_{\mathbf {a}};h_{aa},h_{ba})\) is given by (5).
In the next subsection, we show that (6) does not have a unique solution if modulation sets which are symmetric around the origin are used.
3.2 Identifiability analysis
In this subsection, we present the identifiability analysis for the blind channel estimation problem in (6), which allows us to determine when ambiguity-free channel estimation is possible. For ease of analysis, we first define \(\boldsymbol {\theta }\triangleq [h_{aa},h_{ba}]\) and rewrite (5) as
where θ(1) and θ(2) represent the first and second elements of θ.
We start the identifiability analysis by presenting the following definition and remark:
Definition 1
([28], Definition 5.2) If Y is a random vector distributed according to f Y (y;θ), then θ is said to be unidentifiable on the basis of y, if ∀y there exists θ′≠θ for which f Y (y;θ)=f Y (y;θ′).
Remark 2
Definition 1 states that θ and θ′ (θ≠θ′) cannot be distinguished from a given set of observations if they both result in the same probability density function for the observations. This implies that if θ is unidentifiable, then it is impossible for any estimator to uniquely determine the value of θ.
In order to present the main result in this subsection, we first give the definitions of a symmetric modulation constellation [31] and a bijective function [32].
Definition 2
We mathematically define modulation constellation as the graph of the function f(x k )=x k , where \(x_{k} \in \mathcal {A} \forall k \in \mathcal {K}\). Then a modulation constellation is symmetric with respect to the origin if and only if \(\mathrm {f}(-x_{k})=-\mathrm {f}(x_{k}) \forall x_{k} \in \mathcal {A}\)[31].
Definition 3
Let \(\mathcal {C}\) and \(\mathcal {D}\) be two sets. A function from \(\mathcal {C}\) to \(\mathcal {D}\) denoted \(\mathrm {t}: \mathcal {C} \rightarrow \mathcal {D}\) is a bijective function if and only if it is both one-to-one and onto.
The above definition states that a bijective function is a function between the elements of two sets, where each element of one set is paired with exactly one element of the other set and there are no unpaired elements. Note that a bijective function from a set to itself is also called a permutation [32].
In this work, we define and use the bijective function g: \(\mathcal {K} \rightarrow \mathcal {K}\), i.e., g is a one-to-one and onto function on \(\mathcal {K}\rightarrow \mathcal {K}\). Using this bijective function, we present the main result as below.
Theorem 1
There exists a θ′≠θ for which the joint probability density \(\phantom {\dot {i}\!}f_{\mathbf {Y}_{\mathbf {a}}}(\mathbf {y}_{\mathbf {a}};\boldsymbol {\theta })\) given by (7) is equal to \(\phantom {\dot {i}\!}f_{\mathbf {Y}_{\mathbf {a}}}(\mathbf {y}_{\mathbf {a}};\boldsymbol {\theta }') \; \forall \mathbf {y}_{a}\), if and only if there exists a bijective function g: \(\mathcal {K} \rightarrow \mathcal {K}\), such that \(\frac {x_{k}}{x_{\mathrm {g}(k)}}=c \; \forall k \in \mathcal {K}\), where c≠1 is a constant and |c|=1, i.e., the modulation constellation is symmetric about the origin.
Proof
We prove the result in Theorem 1 in three steps. First, we assume θ′≠θ for which \(\phantom {\dot {i}\!}f_{\mathbf {Y}_{\mathbf {a}}}(\mathbf {y}_{\mathbf {a}};\boldsymbol {\theta })=f_{\mathbf {Y}_{\mathbf {a}}}(\mathbf {y}_{\mathbf {a}};\boldsymbol {\theta }') \forall \mathbf {y}_{\mathbf {a}}\) exists and show that it leads to a bijective function g satisfying \(\frac {x_{k}}{x_{\mathrm {g}(k)}}=c \forall k \in \mathcal {K}\). Then, we assume that a bijective function g satisfying \(\frac {x_{k}}{x_{\mathrm {g}(k)}}=c \forall k \in \mathcal {K}\) exists and show that there exists a θ′≠θ for which \(\phantom {\dot {i}\!}f_{\mathbf {Y}_{\mathbf {a}}}(\mathbf {y}_{\mathbf {a}};\boldsymbol {\theta })=f_{\mathbf {Y}_{\mathbf {a}}}(\mathbf {y}_{\mathbf {a}};\boldsymbol {\theta }') \forall \mathbf {y}_{\mathbf {a}}\). Finally, using Definition 2, we show that the condition \(\frac {x_{k}}{x_{\mathrm {g}(k)}}=c \forall k \in \mathcal {K}\) is equivalent to the modulation constellation being symmetric with respect to the origin. The details are in Appendix 1. □
Remark 3
From Theorem 1, we can see that since the modulation constellations, such as M-ary quadrature amplitude modulation (M-QAM), satisfy the definition of symmetric modulation constellations in Definition 2, the blind channel estimation problem in (6) does not have a unique solution and suffers from an ambiguity problem.
3.3 Proposed technique
In this subsection, we present our proposed technique to resolve the ambiguity problem in (6).
The rationale behind the proposed technique comes from the fact that Theorem 1 shows that symmetry of the modulation constellation with respect to the origin is the cause of the ambiguity. A simple way to achieve constellation asymmetryFootnote 2 is to add a constant s to each element of \(\mathcal {A}\). The resultant asymmetric shifted modulation constellation is formally defined as follows:
Definition 4
The asymmetric shifted modulation constellation, \(\mathcal {\bar {A}}\), is defined as
where \(\mathbb {R}^{+}\) is the set of positive real numbers.
In the rest of the paper, we also use \(\bar {x}_{k}= x_{k}+s\) to denote the kth element of \(\mathcal {\bar {A}}\).
For illustration, Fig. 2 shows the effect of the proposed technique on the 16-QAM constellation. We can see that the resulting modulation constellation is shifted along the horizontal axis, which increases the average energy per symbol of the modulation constellation. This increase in the average energy per symbol can be justified as follows: in reality, it is inevitable to use some extra energy to estimate the unknown channels, whether it is done by pilots or by the proposed technique. In this regard, it is important to note that the smaller the energy used for shifting the modulation constellation, the closer the average energy of the proposed technique is to the ideal scenario where the channels are perfectly known at the receiver and no extra energy is needed for channel estimation.

Effect of the proposed technique on the constellation of 16-QAM. The resulting constellation is shifted along the horizontal axis, i.e., it is asymmetric around the origin
Remark 4
The addition of the DC component lowers power efficiency similar to the use of superimposed training [22]Footnote 3. However, the proposed shifted modulation technique has the offsetting advantages that (i) bandwidth efficiency is not reduced and (ii) the DC offset can be used to reduce the peak-to-average power of the signal envelope during transmissions resulting in lowered cost/complexity power amplifiers. Moreover, the proposed scheme is well-suited to MQAM as investigated here. Since, this is a spectrally efficient modulation scheme used where power efficiency is not critical
For the sake of numerically investigating the problem of smallest possible shift energy, we define β as the portion of the average energy per symbol that is allocated to the shift and use the real constant \(s\triangleq \sqrt {\beta E}\), where 0<β<1 to shift the symmetric modulation constellation. In this case, the problem of smallest shift energy corresponds to the problem of finding the minimum value of β. The minimum value of β is an indication of how much extra energy is needed compared to the perfect channel knowledge scenario.
In Section 4.1, we derive a lower bound on the estimation error, which allows us to numerically find the minimum value of β.
4 EM-based estimator
In this section, we derive an EM estimator to obtain channel estimates in a FD system with asymmetric shifted modulation constellation defined in Definition 4. We derive a lower bound on the estimation error of the estimator. Finally, we investigate the complexity of the proposed estimator.
For the sake of notational brevity, we first define
We can then reformulate the ML problem in (6) as follows
where \(\phantom {\dot {i}\!}f_{\mathbf {Y}_{\mathbf {a}}} (\mathbf {y}_{\mathbf {a}} ; \boldsymbol \phi)\) is given by (7) and \(\ln f_{\mathbf {Y}_{\mathbf {a}}} (\mathbf {y}_{\mathbf {a}} ; \boldsymbol \phi)\) is known as the log-likelihood function.
In formulating the channel estimation problem in (6) (and hence in (10)), we assumed unknown transmitted symbols. These unknown transmitted symbols can be treated as hidden data. A common approach to solving the maximization problem in (10) in the presence of hidden data is the EM algorithm [33], which is adopted in this work. The main steps of EM algorithm are
-
1.
Expectation step: In the E-step, the expectation of the log-likelihood is taken over all the values of the hidden variable, conditioned on the vector of observations, and the nth estimate of ϕ (ϕ(n)). In (1), the hidden variable is \(\bar {\mathbf {x}}_{\mathbf {b}}\) and consequently, we need to evaluate \(Q(\boldsymbol {\phi }|\boldsymbol {\phi }^{(n)})\triangleq \mathbb {E}_{\bar {\mathbf {X}}_{\mathbf {b}}|\mathbf {y}_{\mathbf {a}},\boldsymbol {\phi }^{(n)}}[\ln {f_{\mathbf {Y}_{\mathbf {a}}}(\mathbf {y}_{\mathbf {a}},\bar {\mathbf {x}}_{\mathbf {b}}|\boldsymbol {\phi })}]\).
-
2.
Maximization step: In the M-step, the function Q(ϕ|ϕ(n)) obtained from the E-step is maximized with respect to ϕ.
-
3.
Iterations: We iterate between the E- and M-steps until convergence is achieved.
The equations needed for the E- and M-steps are summarized in the propositions below.
Proposition 2
The E-step during nth iteration of the algorithm is given by
where \(\boldsymbol {\phi }^{(n)} \triangleq \left [\hat {h}^{(n)}_{aa},\ \hat {h}^{(n)}_{ba}\right ]\) are the estimates of the channels obtained from ϕ(n) during the nth iteration of the algorithm, and \(T_{k,i}^{(n)}\) is defined as
where \(k \in \mathcal {K}\), \(i \in \mathcal {I}\triangleq [1,2,\cdots,N]\), \(\bar {x}_{k} \in \mathcal {\bar {A}}\), \(\bar {x}_{a_{i}} \in \mathcal {\bar {A}}\) and \(\bar {x}_{\bar {k}} \in \mathcal {\bar {A}}\).
Proof
See Appendix 2. □
Proposition 3
The M-step during the nth iteration of the algorithm is given by
where
Proof
See Appendix 2. □
Remark 5
It is well-known that the EM algorithm may be very sensitive to initialization [34]. Although different methods exist for EM initialization, generally they are not computationally efficient [34, 35]. For the given channel assumptions in Section 5, our empirical results showed that initializing the EM algorithm by \(\boldsymbol {\phi }^{(0)} \triangleq [0,0,0,0]\) resulted in the lowest estimation error. Hence, this initialization is used in this work.
4.1 Lower bound on the estimation error
In this section, we derive a closed-form lower bound on the estimation error of the proposed estimator. The derived lower bound directly links the channel estimation error to the parameter β, defined in Section 3.3.
The EM algorithm, defined in Propositions 2 and 3, is a ML estimator for the parameter vector ϕ in (9). Hence, we aim to derive the lower bound for the variance of the proposed ML estimator. The ML estimator is asymptotically efficient [36] and its MSE is lower bounded by the inverse of the Fisher information matrix (FIM) [36]. This result is known as Cramer Rao lower bound (CRLB) and is given by
where ϕ l is the lth element of the parameter vector ϕ, \(\hat {\phi }_{l}\) is an estimate of ϕ l , for l∈{1,2,3,4}, [ ·]l,l is the lth diagonal element of a square matrix, and \(\mathrm {I}^{-1}\left [f_{\mathbf {Y}_{\mathbf {a}}}(\mathbf {y}_{a};\boldsymbol {\phi })\right ]\) is the inverse of FIM. Since the inverse of FIM in (15) cannot be found in closed-form [24, 37], we derive a lower bound on the MSE of the proposed estimator, which is in closed-from. The result is presented in the proposition below.
Proposition 4
The variance of the proposed estimator is lower bounded by
where l∈{1,⋯,4}, N is the number of observations, E is the average symbol energy of the modulation constellation before the shift, and β is the portion of E that is allocated to the shift.
Proof
See Appendix 3. □
Remark 6
The result in (16) links the closed-form lower bound of the estimation error to the average energy of the modulation constellation before the shift and the portion of this average energy allocated to the shift. This is important because in Section 5.1, we will use (16) to find the minimum shift energy needed for the proposed technique.
4.2 Complexity analysis
To evaluate the feasibility in implementing the proposed estimator, we investigate the computational complexity of the estimator in terms of required floating point multiplications and additions (flops) [38].
Table 1 shows the number of multiplications and additions needed for the EM estimator for h ba . Although we only present the complexity analysis of h ba , similar complexity is also observed for estimating h aa . In each row of the table, the number of required additions and multiplications to implement a given equation is presented and are then summed to obtain overall complexity.
It is clear from Table 1 that the complexity of EM estimator per iteration is proportional to NM2. This analysis shows that the EM algorithm is computationally very efficient since, for a given modulation constellation with size M, the computational complexity of the EM estimator only grows linearly with the number of observations, N.
Remark 7
In data-aided approaches to channel estimation, both x a and x b in (1) are assumed to be known. Consequently, linear channel estimation can be performed for linear Gaussian models (LGMs) as explained in [36]. It is a well-known fact that linear estimator complexity estimators for LGM is independent of the modulation size M, and only grows linearly with the number of observations [36]. The extra complexity of the proposed algorithm compared to linear estimators is expected. This is because as opposed to linear estimators, the proposed estimator requires no data-aided piloting, and hence, it allows for efficient use of the bandwidth for channel estimation.
5 Simulation results
In this section, we present numerical and simulation results to investigate the performance of the proposed estimator with asymmetric shifted modulation constellation. We consider a FD communication system as illustrated in Fig. 1. The analysis in Section 4.1 shows an identical lower bound for the estimation error of both h aa and h ba . Hence, in this section, we only present the results for the communication channel h ba since identical results are obtained for the SI channel h aa .
For each simulation run, N data and interfering symbols are randomly generated assuming shifted 16-QAM modulation constellation is used (M=16). The channels are constant for the transmission of N symbols, i.e., the quasi static assumption. We assume that there is no line-of-sight (LOS) communication link between the transmitter of node b and the receiver of node a. Hence, the communication channel h ba can be modeled as a Rayleigh fading channel, i.e., \(h_{ba} \sim \mathcal {CN}\left (0,\sigma ^{2}_{h_{ba}}\right)\). For the SI channel, experimental results have shown that before passive and active cancellation, the SI channel has a strong LOS component and can be modeled as a Rician distribution with a large K factor (approximately 20–25 dB). After passive suppression and analog cancellation, the strong LOS component is significantly reduced but still present and can be modeled as a Ricean distribution with K=0 dB [5]. Hence, we generate the SI channel as
where ζ is uniformly distributed angle of arrival of the LOS component of the SI channel [39].
For the simulations, the signal-to-interference-noise ratio (SINR) is given by [5]
where the signal-to-interference ratio \(\text {SIR}=\frac {\sigma ^{2}_{h_{ba}}}{\sigma ^{2}_{h_{aa}}}\) assuming both nodes use constellations with the same average energy, the desired signal-to-noise ratio \(\text {SNR}=\frac {\sigma ^{2}_{h_{ba}}\log _{2}{(M)}E_{b}}{N_{0}}\), E b is the average bit energy which is defined below (2) and N0 is the noise power spectral density.
As discussed in Section 1, even with state-of-the-art passive suppression and analog cancellation, the SIR can still be around − 5 dB [5,40]. Hence, we adopt this value of the SIR in the simulations while assuming that the communication channel has average energy of unity, i.e., \(\mathbb {E}\left [|h_{ba}|^{2}\right ]=\sigma ^{2}_{h_{ba}}=1\). Furthermore, in order to investigate the performance of the proposed estimator over a range of SINR, we fix N0=1 and run the simulations for different values of E b /N0 (in dB). The figures of merit used are the average mean square error (MSE) and the BER, which are obtained by averaging over 5000 Monte Carlo simulation runs.
5.1 Minimum energy needed for channel estimation
In this subsection, we are interested in finding the minimum value of β, for a given E b /N0 and N. As discussed in Section 3.3, we use \(s\triangleq \sqrt {\beta E}\), where 0<β<1, to shift the symmetric modulation constellation. Hence, a lower value of β is desirable since it means less energy is used to shift the modulation constellation.
In order to find a minimum value of β suitable for a practical range of E b /N0 and N, we use the average MSE lower bound in (16) to observe the behavior of the proposed estimator as a function of β at low N and low E b /N0. This is motivated by the fact that the minimum value of β found for low N and low E b /N0 will ensure that the desired estimation error will also be achieved for high E b /N0 and/or when the number of observations N is large. This intuition is confirmed from (16), which indicates that higher values of β are needed at low E b /N0 to reach a given estimation error. Furthermore, since the lower bound on the estimation error also decreases with N, the minimum value of β found for smaller N can also serve for larger N. Since the experimental results of [5,41] show that the FD communication channel is normally constant for more than N>128 symbols, we propose to find the minimum β at N=128 and E b /N0=0 dB.
Figure 3 shows the MSE performance of the proposed technique versus β for E b /N0=0 dB, N=128, and SIR =− 50 dB. If the desired estimation error is taken to be within 10% of the lower bound error, then we can see from the figure that for β<0.2, the MSE of the proposed estimator is within 10% of the lower bound. Consequently, the minimum value of β is 0.2.

MSE performance of the proposed channel estimator for different values of β for E b /N0=0 dB, N=128, and SIR =− 50 dB
Figure 4 shows the MSE performance of the proposed estimator with β=0.2 (the selected minimum value of β) vs. E b /N0 (dB) for N=128 and SIR =− 50 dB. The lower bound in (16) is plotted as a reference. The figure shows that as E b /N0 increases, the gap between the performance of the proposed estimator and the lower bound decreases. The gap is less than 2 dB after E b /N0=20 dB.

MSE performance of the proposed channel estimator vs. E b /N0 for β=0.2, N=128, and SIR =− 50 dB
In the following sections, we set β=0.2 and N=128 to study the performance of the FD communication system.
5.2 Comparison with data-aided channel estimation
In this section, we compare the MSE and BER performance of the proposed estimator against a data-aided channel estimator for the case that the average energy per transmitted frame is the same for both methodsFootnote 4. For the proposed technique, we assume that (i) all the transmitted symbols are data symbols and (ii) shifting the modulation constellation increases the average energy by 20% compared to the ideal scenario when no channel estimation is needed (corresponds to β=0.2). For the data-aided channel estimation, we assume that (i) 64 pilot symbols are used in a frame of 128 symbols and (ii) these pilots also require an extra 20% energy.
5.2.1 MSE performance
The average MSE reveals the accuracy of the channel estimation. Figure 5 plots the average MSE vs. E b /N0 with β=0.2, N=128, and SIR =− 50 dB. The lower bound from (16) is plotted as a reference. We also plot the MSE for data-aided channel estimation with (i) 64 pilot symbols in a frame of 128 symbols and (ii) 128 pilot symbols in a frame of 128 symbols. Figure 5 shows that the proposed technique outperforms data-aided channel estimation when both methods use the same extra amount of energy for channel estimation. At high E b /N0, the MSE performance of the proposed technique is within 3−4 dB of the lower bound.

MSE performance of the proposed technique
It has been shown in [9] that the effect of quantization error in FD communication system can be modeled as an additive Gaussian noise. This means the system model given by (1) implicitly includes the effect of quantization noise as well as the effect of thermal noise in the Gaussian noise term w a . Consequently, the effect of quantization noise on the performance of the proposed estimator can be studied by observing the MSE results of the proposed estimator in the low SNR region as shown by Fig. 5. The results of Fig. 5 show that at low SNR region, a noticeable MSE gain is not obtained by using the proposed estimator instead of the data-aided technique that uses 128 pilots. However, the proposed technique is still more attractive compared to the data-aided technique because of the bandwidth efficiency.
5.2.2 BER performance
Figure 6 shows the average BER vs. E b /N0 (dB) with β=0.2, N=128, and SIR =− 50 dB. The BER performance with perfect channel knowledge is plotted as a reference. We also plot the BER for data-aided channel estimation with 64 pilot symbols in a frame of 128 symbols. Figure 6 shows that the proposed technique outperforms the data-aided channel estimation in terms of the BER. This is to be expected since, as shown in Fig. 5, for the same extra amount of energy for channel estimation the proposed technique has much lower MSE compared to data-aided channel estimation. In addition, at high E b /N0, the BER performance of the proposed technique is within 1 dB of the ideal performance obtained with perfect channel knowledge.

BER performance of the proposed technique
As shown in this sub-section, in comparison to the data-aided algorithms, the proposed algorithm is more bandwidth efficient. Also compared to the existing blind algorithms, which suffer from phase ambiguity [23], the proposed algorithm can estimate the channel with no phase ambiguity. These advantages have been obtained by an increase in complexity as explained in Remark 7. However, the superior performance of the proposed algorithm as shown in Figs. 5 and 6 produces attractive tradeoffs compared to the existing data-aided and blind algorithms.
5.3 Effect of power of SI signal
In the results so far, we have set the SIR to − 50 dB. In this section, we assess the impact of the SI power level on the performance of the proposed technique.
Figure 7 plots the BER versus the SIR (dB) for E b /N0=0,10,20 dB, with β=0.2 and N=128. We can see that as the SI power increases, the BER performance of the proposed technique remains nearly constant. This is because in FD communication the self-interference signal is completely known to the receiver [3]. Consequently, for relatively small channel estimation error of the proposed estimator, the SI can be cancelled regardless of its power. Figure 7 illustrates the robustness of the proposed technique, i.e., even with weak passive suppression and analog cancellation requiring digital SI cancellation to handle a very large SIR (e.g., − 100 dB), the BER is not significantly altered.

Effect of SI power level on the BER performance of the proposed technique
6 Conclusions
In this paper, we have proposed a new technique to estimate the SI and communication channels in a FD communication systems for residual SI cancellation. In the proposed technique, we add a real constant number to each constellation point of a modulation constellation to yield asymmetric shifted modulation constellations with respect to the origin. Using identifiability analysis, we show mathematically that such a modulation constellation can be used for ambiguity-free channel estimation in FD communication systems. We proposed a computationally efficient EM-based estimator to estimate the SI and communication channels simultaneously using the proposed technique. We also derived a lower bound for the estimation error of the proposed estimator. The results showed that the proposed technique is robust to the level of SI power.
7 Appendix 1
7.1 Proof of Theorem 1
The proof consists of three main steps.
Step 1: We show that if θ′≠θ exists such that \(\phantom {\dot {i}\!}f_{\mathbf {Y}_{\mathbf {a}}}(\mathbf {y}_{\mathbf {a}};\boldsymbol {\theta }')=f_{\mathbf {Y}_{\mathbf {a}}}(\mathbf {y}_{\mathbf {a}};\boldsymbol {\theta }) \forall \mathbf {y}_{a}\), then a bijective function \(\mathrm {g}: \mathcal {K}\rightarrow \mathcal {K}\) exists, such that \(\frac {x_{k}}{x_{\mathrm {g}(k)}}=c \forall k\in \mathcal {K}\), where c≠1 is a constant and |c|=1. This is done as follows.
If the two joint probability densities \(\phantom {\dot {i}\!}f_{\mathbf {Y}_{\mathbf {a}}}(\mathbf {y}_{\mathbf {a}};\boldsymbol {\theta }')\) and \(\phantom {\dot {i}\!}f_{\mathbf {Y}_{\mathbf {a}}}(\mathbf {y}_{\mathbf {a}};\boldsymbol {\theta })\) are equal ∀y a , then it easily follows that the marginal densities \(f_{Y_{a_{i}}}(y_{a_{i}};\boldsymbol {\theta }')\) and \(f_{Y_{a_{i}}}(y_{a_{i}};\boldsymbol {\theta })\) are also equal \(\forall y_{a_{i}}\). From (4), \(f_{Y_{a_{i}}}(y_{a_{i}};\boldsymbol {\theta }')\) and \(f_{Y_{a_{i}}}(y_{a_{i}};\boldsymbol {\theta })\) are given by
If \(f_{Y_{a_{i}}}(y_{a_{i}};\boldsymbol {\theta }')\) and \(f_{Y_{a_{i}}}(y_{a_{i}};\boldsymbol {\theta })\) are equal \(\forall y_{a_{i}}\), they should also be equal for \(y_{a_{i}}=\boldsymbol {\theta }(1)x_{a_{i}}+\boldsymbol {\theta }(2)x_{1}\). In this case, we have
The left hand side (LHS) of (21) is independent of i, while the right hand side (RHS) of (21) depends on i through \(x_{a_{i}}\). Consequently, for (21) to hold for \(\forall y_{a_{i}}\), the coefficient of \(x_{a_{i}}\) should be zero, i.e., θ′(1)=θ(1). Knowing that θ′(1)=θ(1) and equating (19) and (20), we have
By taking the first and second order derivatives of both sides of (22) with respect to \(y_{a_{i}}\), it can be shown that \(\forall k \in \mathcal {K}\), the points \(y_{a_{i}}= \boldsymbol {\theta }(1)x_{a_{i}}+\boldsymbol {\theta }(2)x_{k}\) and \(y_{a_{i}}= \boldsymbol {\theta }(1)x_{a_{i}}+\boldsymbol {\theta }'(2)x_{k}\) maximize the summations of the M exponential functions on the LHS and RHS of (22), respectively. Consequently, since (22) holds \(\forall y_{a_{i}}\), the points that maximize the summation of M exponential on the LHS of (22) are the same as the points that maximize the summation of M exponentials on the RHS of (22). Hence, for a bijective function \(\mathrm {g}: \mathcal {K}\rightarrow \mathcal {K}\)
It can easily be verified that if (23) holds \(\forall y_{a_{i}}\), then,
or
The LHS of (25) does not depend on k; consequently, the RHS of (25) should also be independent of k and should be a constant. Hence, for bijective function g, \(\frac {x_{k}}{x_{\mathrm {g}(k)}}=c\), where c≠1 is a constant. We note that if c=1 then θ(2)=θ′(2) and hence θ=θ′, which violates the assumption that \(\phantom {\dot {i}\!}f_{\mathbf {Y}_{\mathbf {a}}}(\mathbf {y}_{\mathbf {a}};\boldsymbol {\theta }')=f_{\mathbf {Y}_{\mathbf {a}}}(\mathbf {y}_{\mathbf {a}};\boldsymbol {\theta })\) for θ≠θ′.
Let us now define permutation Π on the ordered set \(\mathcal {A}=\{x_{1},\cdots,x_{M}\}\) as
The sequence (x k ,Π(x k ),Π(Π(x k )),⋯,x k ) forms an orbit of the permutation Π [32]. If \(x_{k}=c x_{\mathrm {g(k)}} \forall k \in \mathcal {K}\), then from the definition of the orbit it is clear that \(x_{k}=c^{m}x_{k} \forall k \in \mathcal {K}\), where m is the length of the orbit sequence and c≠1 is a constant. Since, \(x_{k}=c^{m}x_{k} \forall k \in \mathcal {K}\), we can conclude that cm=1 and |c|=1.
Step 2: We show that if the bijective function g: \(\mathcal {K} \rightarrow \mathcal {K}\) exists, such that \(\frac {x_{k}}{x_{\mathrm {g}(k)}}=c \forall k \in \mathcal {K}\), then there exists a θ′≠θ for which \(\phantom {\dot {i}\!}f_{\mathbf {Y}_{\mathbf {a}}}(\mathbf {y}_{\mathbf {a}};\boldsymbol {\theta }')=f_{\mathbf {Y}_{\mathbf {a}}}(\mathbf {y}_{\mathbf {a}};\boldsymbol {\theta }) \forall \mathbf {y}_{a}\). This is done as follows.
Firstly, in Section 3.2 we showed that the joint PDF of all the observations is given by
We can see that for a fixed i in (27), M different exponential functions corresponding to different values of \(x_{k} \in \mathcal {A}\) are summed together. Since, \(\mathrm {g}:\mathcal {K}\rightarrow \mathcal {K}\) is a bijective function and consequently replacing x k by xg(x) only affects the order of the exponential functions, we can rewrite (27) as
Secondly, for \(\boldsymbol {\theta }'\triangleq [\boldsymbol {\theta }(1),\frac {\boldsymbol {\theta }(2)}{c}]\), \(\phantom {\dot {i}\!}f_{\mathbf {Y}_{\mathbf {a}}}(\mathbf {y}_{\mathbf {a}};\boldsymbol {\theta }')\) is given by
and since \(\frac {x_{k}}{c}=x_{\mathrm {g}(k)} \forall k \in \mathcal {K}\), (29) can be written as
Comparing (30) with (28) reveals that for θ′≠θ, \(\phantom {\dot {i}\!}f_{\mathbf {Y}_{\mathbf {a}}}(\mathbf {y}_{\mathbf {a}};\boldsymbol {\theta }')=f_{\mathbf {Y}_{\mathbf {a}}}(\mathbf {y}_{\mathbf {a}};\boldsymbol {\theta }) \forall \mathbf {y}_{a}\). Consequently, if bijective function g: \(\mathcal {K} \rightarrow \mathcal {K}\) exits, such that \(\frac {x_{k}}{x_{\mathrm {g}(k)}}=c \forall k \in \mathcal {K}\), then there exists a θ′≠θ for which \(\phantom {\dot {i}\!}f_{\mathbf {Y}_{\mathbf {a}}}(\mathbf {y}_{\mathbf {a}};\boldsymbol {\theta }')=f_{\mathbf {Y}_{\mathbf {a}}}(\mathbf {y}_{\mathbf {a}};\boldsymbol {\theta }) \forall \mathbf {y}_{a}\).
Step 3: Thirdly, we show that the condition \(\frac {x_{k}}{x_{\mathrm {g}(k)}}=c \forall k \in \mathcal {K}\) is equivalent to the modulation constellation being symmetric around the origin. To prove this equivalency, we need to consider the following two sub-cases:
-
(i)
Firstly, we need to show that if a bijective function \(\mathrm {g}:\mathcal {K}\rightarrow \mathcal {K}\) exists such that \(\frac {x_{k}}{x_{\mathrm {g}(k)}}=c\), then the modulation constellation is symmetric with respect to origin. Equivalently, we can show that if a bijective function \(\mathrm {g}:\mathcal {K}\rightarrow \mathcal {K}\) does not exist such that \(\frac {x_{k}}{x_{\mathrm {g}(k)}}=c\), then the modulation constellation is not symmetric with respect to origin. To prove this equivalent statement, we use proof by contradiction. We assume \(\mathrm {g}:\mathcal {K}\rightarrow \mathcal {K}\) does not exist such that \(\frac {x_{k}}{x_{\mathrm {g}(k)}}=c\), but the modulation constellation is symmetric with respect to origin. If the modulation is symmetric with respect to the origin, then it satisfies the condition of Definition 2 and hence,
$$\begin{array}{*{20}l} \mathrm{f}(-x_{k})=-\mathrm{f}(x_{k}). \end{array} $$(31)However, since the function f(x k ) is defined on set \(\mathcal {A}\), (31) holds if and only if both x k and −x k are in the set \(\mathcal {A}\). Consequently, set \(\mathcal {A}\) can be represented by
$$\begin{array}{*{20}l} \mathcal{A}=\{x_{1},x_{2},\cdots,x_{\frac{M}{2}},-x_{1},-x_{2},\cdots,-x_{\frac{M}{2}}\}. \end{array} $$(32)Now, if the bijective function g is defined as \(\mathrm {g}(k)=k+\frac {M}{2}\), then \(\frac {x_{k}}{x_{\mathrm {g}(k)}}=-1\). However, this contradicts the assumption that bijective function \(\mathrm {g}:\mathcal {K}\rightarrow \mathcal {K}\) does not exist, such that \(\frac {x_{k}}{x_{\mathrm {g}(k)}}=c\forall k \in \mathcal {K}\). Hence, if \(\mathrm {g}:\mathcal {K}\rightarrow \mathcal {K}\) does not exist such that \(\frac {x_{k}}{x_{\mathrm {g}(k)}}=c\), then the modulation constellation cannot be symmetric with respect to origin.
-
(ii)
Secondly, we need to show that if the modulation is symmetric then a bijective function \(\mathrm {g}:\mathcal {K}\rightarrow \mathcal {K}\) exists such that \(\frac {x_{k}}{x_{\mathrm {g}(k)}}=c \forall k \in \mathcal {K}\). This easily follows from the proof of previous step, where we showed that if the modulation constellation is symmetric then \(\mathcal {A}\) can be represented by (32). Consequently, a bijective function \(\mathrm {g}:\mathcal {K}\rightarrow \mathcal {K}\) exists such that \(\frac {x_{k}}{x_{\mathrm {g}(k)}}=-1 \forall k \in \mathcal {K}\), i.e., \(\mathrm {g}(k)=k+\frac {M}{2} \forall k \in \mathcal {K}\).
Combining the proofs of the three steps, Theorem 1 is proved.
8 Appendix 2
8.1 Proof of Propositions 2 and 3
Propositions 2 and 3 correspond to the E and M steps of the EM algorithm. We assume that both transmitters at nodes a and b use the asymmetric shifted modulation constellation \(\mathcal {\bar {A}}\) defined in Definition 4, i.e., \(\bar {x}_{a_{i}},\bar {x}_{b_{i}} \in \mathcal {\bar {A}}\) and assume a uniform discrete distribution for the transmitted symbols.
8.1.1 Proof of E-step
In the E-step of the algorithm function Q(ϕ|ϕ(n)) is given by
To calculate (33), we require
\(\ln {f_{\mathbf {Y}_{\mathbf {a}}}(\mathbf {y}_{a},\bar {\mathbf {x}}_{\mathbf {b}}|\boldsymbol {\phi })}\). Hence, we start with the following joint PDF
where, \(\delta _{\bar {x}_{k},\bar {x}_{b_{i}}}\) is the Kronecker delta function and \(\delta _{\bar {x}_{k},\bar {x}_{b_{i}}}=1\) if \(\bar {x}_{b_{i}}=\bar {x}_{k}\) and 0 otherwise [31]. Consequently, the log-likelihood of all the observations is given by
The expectation in (33) is conditioned on knowing ϕ(n) during the nth iteration of the algorithm, which is obtained from the M-step. Substituting (35) in (33), we have
The assumption of independent transmitted symbols allows to rewrite (36) as follows
We define
Then, it can easily be shown that
Finally, substituting (39) into (37), Q(ϕ|ϕ(n)) can be found as in (33). This concludes the proof of Proposition 2.
8.1.2 Proof of M-step
The maximization-step of the EM algorithm is given by
We define the following function
The minimum of function ϕ (the maximum of the likelihood function), which corresponds to the solution of the M-step of the EM algorithm during the nth iteration, happens at the critical point ϕ(n+1) for which the Jacobian is zero, i.e., J=0 [43]. To find this critical point, the Jacobian matrix should be constructed and set equal to zero. This is done by taking the derivative of r(ϕ) with respect to the four elements of vector ϕ, as defined by (9), to construct the Jacobian matrix and then set it equal to zero. Then, it can be easily shown that the critical point ϕ(n+1) is given by
where
where the elements of S and v are given by (14b)–(14d).
However, to ensure that the critical point ϕ(n+1) is the minimum of function r(ϕ), the Hessian matrix H should be positive semi-definite [43]. By taking the second derivatives of r(ϕ) with respect to the four elements of vector ϕ, we can show that H=2S. Then, according to Sylvester’s criterion [43], H is positive semi-definite if and only if all the following are positive
It can easily be shown that \(\det (\mathrm {S})=\left (s_{1}s_{4}-s_{2}^{2}-s_{3}^{2}\right)^{2}\) and is always positive. According to (14b), s1 is always positive, and it is clear that the second determinant is always positive. However, the positivity of the third determinant, i.e., \(s_{1}s_{4}-s_{2}^{2}-s_{3}^{2}\), directly depends on the initialization. This is evident from definitions in (14b)–(14d), which link s1, s2, s3, and s4 to the function \(T_{k,i}^{(n)}\) and the derivation of function \(T_{k,i}^{(n)}\) in (39), which is a function of \(\hat {h}^{(n)}_{aa}\) and \(\hat {h}^{(n)}_{ba}\), i.e., the estimates from the nth iteration. Our numerical investigation shows that for the initialization vector \(\boldsymbol {\phi }^{(0)}\triangleq [0,0,0,0]\), the Hessian matrix H is always positive and hence the critical point ϕ(n+1) is indeed the minimum of function r(ϕ). Consequently, the EM algorithm with initialization vector \(\boldsymbol {\phi }^{(0)}\triangleq [0,0,0,0]\) converges to the maximum of the likelihood function.
This concludes the proof of Proposition 3.
9 Appendix 3
9.1 Proof of Proposition 4
It is shown in [44] that for any random variables X and Y and any parameter θ, if the probability distribution of X is independent of the parameter θ, then I[f Y (y;θ)]<I[f Y (y|x;θ)], where I[·] is the FIM and f(·;θ) is the probability density function parameterized by θ. Consequently, the performance of the proposed estimator is lower bounded by the inverse of \(\mathrm {I}[f_{\mathbf {Y}_{\mathbf {a}}}(\mathbf {y}_{\mathbf {a}}|\bar {\mathbf {x}}_{\mathbf {b}};\boldsymbol {\phi })]\), i.e.,
where ϕ l is the lth element of the parameter vector ϕ, \(\hat {\phi }_{l}\) is an estimate of ϕ l , and [·]l,l is the lth diagonal element of matrix. This is because (i) the performance of the proposed estimator is lower bounded by \(\phantom {\dot {i}\!}\mathrm {I}[f_{\mathbf {Y}_{\mathbf {a}}}(\mathbf {y}_{\mathbf {a}};\boldsymbol {\phi })]\) according to (15) and (ii) \(p_{\bar {\mathbf {X}}_{\mathbf {b}}}(\bar {\mathbf {x}}_{\mathbf {b}})\) is independent of ϕ. Furthermore, since (45) holds \(\forall \bar {\mathbf {x}}_{\mathbf {a}}, \bar {\mathbf {x}}_{\mathbf {b}}\), then the variance is also lower-bounded by
where \(\mathrm {I}_{avg}=\mathbb {E}_{\bar {\mathbf {X}}_{\mathbf {b}}, \bar {\mathbf {X}}_{\mathbf {a}}}\left [\mathrm {I}[f_{\mathbf {Y}_{\mathbf {a}}}(\mathbf {y}_{\mathbf {a}}|\bar {\mathbf {x}}_{\mathbf {b}};\boldsymbol {\phi })]\right ]\). The value of \(\mathrm {I}[f_{\mathbf {Y}_{\mathbf {a}}}(\mathbf {y}_{\mathbf {a}}|\bar {\mathbf {x}}_{\mathbf {b}};\boldsymbol {\phi })]\), needed to evaluate I avg , is presented in the Lemma below.
Lemma 1
\(\mathrm {I}[f(\mathbf {y}_{\mathbf {a}}|\bar {\mathbf {x}}_{\mathbf {b}};\boldsymbol {\phi })]\) is a 4×4 matrix with its elements given by
Proof
It can be easily seen from (5) that \(\phantom {\dot {i}\!}f_{\mathbf {Y}_{\mathbf {a}}}(\mathbf {y}_{\mathbf {a}}|\bar {\mathbf {x}}_{\mathbf {b}}; h_{aa},h_{ba})\) is given by
Then, for l,l′∈{1,2,3,4}, \(\mathrm {I}[f_{\mathbf {Y}_{\mathbf {a}}}(\mathbf {y}_{\mathbf {a}}|\bar {\mathbf {x}}_{\mathbf {b}};h_{aa},h_{ba})]\) is [36]
where m,n∈{1,2,3,4}, ϕ m and ϕ n are the mth and nth elements of ϕ=[ℜ{h aa },I{h aa },ℜ{h ba },I{h ba }]. By evaluating (49), using the joint PDF given by (48), the non-zero elements of \(\mathrm {I}[f_{\mathbf {Y}_{\mathbf {a}}}(\mathbf {y}_{\mathbf {a}}|\bar {\mathbf {x}}_{\mathbf {b}};h_{aa},h_{ba})]\) can be found and are given by (47b)–(47c). □
Using the value of \(\mathrm {I}[f(\mathbf {y}_{\mathbf {a}}|\bar {\mathbf {x}}_{\mathbf {b}};\boldsymbol {\phi })]\) given by the above lemma, we need to evaluate the expectations in order to find I avg . As discussed in Section 3.3, we assume that both nodes a and b use a real constant \(s\triangleq \sqrt {\beta E}\) to shift the modulation constellation. Since all the constellation points are equally likely to be transmitted, before shifting the modulation constellation we have \(\mathbb {E}_{\Im \{\bar {X}_{a_{i}}\}}[\Im \{x_{a_{i}}\}]=\mathbb {E}_{\Im \{\bar {x}_{b_{i}}\}}[\Im \{x_{b_{i}}\}]=\mathbb {E}_{\Re \{\bar {X}_{a_{i}}\}}[\Re \{{x}_{a_{i}}\}]=\mathbb {E}_{\Re \{\bar {X}_{b_{i}}\}}[\Re \{x_{b_{i}}\}]=0\). However, after the shift, \(\mathbb {E}_{\Re \{\bar {X}_{a_{i}}\}}[\Re \{\bar {x}_{a_{i}}\}]=\mathbb {E}_{\Re \{\bar {X}_{b_{i}}\}}[\Re \{\bar {x}_{b_{i}}\}]=\sqrt {\beta E}\) and \(\mathbb {E}_{\Im \{\bar {X}_{a_{i}}\}}[\Im \{\bar {x}_{a_{i}}\}]=\mathbb {E}_{\Im \{\bar {X}_{b_{i}}\}}[\Im \{\bar {x}_{b_{i}}\}]=0\). Furthermore, \(\mathbb {E}_{X_{a_{i}}}[|\bar {x}_{a_{i}}|^{2}]=\mathbb {E}_{X_{b_{i}}}[|\bar {x}_{b_{i}}|^{2}]=E+\beta E\) since the average energy of the constellation after the shift is increased by the shift energy (|s|2=βE). Consequently, the average FIM with respect to \(\bar {\mathbf {x}}_{\mathbf {a}}\) and \(\bar {\mathbf {x}}_{\mathbf {b}}\) is given by
and \(\mathrm {I}^{-1}_{avg}\) is given by
Using (46) and considering the diagonal elements of (51), we arrive at the result in (16).
Notes
Note that the system model for FD communication in (1) is applicable to per subcarrier communication in orthogonal frequency division multiplexing (OFDM) FD communication [3, 5, 41].
Fig. 1 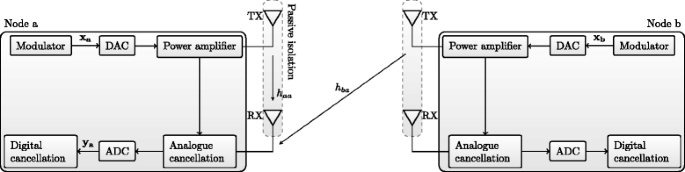
Illustration of full-duplex communication between two transceivers, each with a single transmit and a single receive antenna. ADC analog-to-digital converter, DAC digital-to-analog converter, TX transmit, RX receive
Note that it may be possible to achieve constellation asymmetry through other means, such as design of irregular modulation constellations. The optimum design of such modulation constellations is outside the scope of this work.
Note that the existing hardware implementations for superimposed training [42] can also be used here for shifting the modulation constellation.
Note that the simulation results have been obtained by normalizing the shifted modulation so the extra power needed to shift the modulation does not push the power amplifiers into saturation and hence, power amplifiers do not experience any non-linearities.

References
D Korpi, J Tamminen, M Turunen, T Huusari, YS Choi, L Anttila, S Talwar, M Valkama, Full-duplex mobile device: pushing the limits. IEEE Commun. Mag. 54(9), 80–87 (2016).
Z Zhang, X Chai, K Long, AV Vasilakos, L Hanzo, Full duplex techniques for 5G networks: self-interference cancellation, protocol design, and relay selection. IEEE Commun. Mag. 53(5), 128–137 (2015).
A Sabharwal, P Schniter, D Guo, DW Bliss, S Rangarajan, R Wichman, In-band full-duplex wireless: challenges and opportunities. IEEE J. Sel. Areas Commun. 32(9), 1637–1652 (2014).
MS Sim, M Chung, D Kim, J Chung, DK Kim, CB Chae, Nonlinear self-interference cancellation for full-duplex radios: from link-level and system-level performance perspectives. IEEE Commun. Mag. 55(9), 158–167 (2017).
M Duarte, C Dick, A Sabharwal, Experiment-driven characterization of full-duplex wireless systems. IEEE Trans. Wireless Commun. 11(12), 4296–4307 (2012).
E Everett, A Sahai, A Sabharwal, Passive self-interference suppression for full-duplex infrastructure nodes. IEEE Trans. Wireless Commun. 13(2), 680–694 (2014).
B Kaufman, J Lilleberg, B Aazhang, in Proc. Asilomar Conf. on Signals, Syst. and Computers. An analog baseband approach for designing full-duplex radios, (2013).
D Korpi, T Riihonen, V Syrjala, L Anttila, M Valkama, R Wichman, Full-duplex transceiver system calculations: analysis of ADC and linearity challenges. IEEE Trans. Wireless Commun. 13(7), 3821–3836 (2014).
D Korpi, L Anttila, V Syrjala, M Valkama, Widely-linear digital self-interference cancellation in direct-conversion full duplex transceiver. IEEE J. Sel. Areas Commun. 32(9), 1674–1687 (2014).
E Ahmed, AM Eltawil, All-digital self-interference cancellation technique for full-duplex systems. IEEE Trans. Wireless Commun. 14(7), 3519–3532 (2015).
A Nadh, J Samuel, A Sharma, S Aniruddhan, RK Ganti, A linearization technique for self-interference cancellation in full-duplex radios. (2017). arXiv Technical Report. [Online]. Available: https://arxiv.org/abs/1605.01345.
D Kim, H Ju, S Park, D Hong, Effects of channel estimation error on full-duplex two-way networks. IEEE Trans. Veh. Technol. 62(9), 4666–4672 (2013).
A Masmoudi, T Le-Ngoc, A maximum-likelihood channel estimator for self-interference cancelation in full-duplex systems. IEEE Trans. Veh. Technol. 65(7), 5122–5132 (2016).
X Li, C Tepedelenliolu, H Şenol, Channel estimation for residual self-interference in full-duplex amplify-and-forward two-way relays. IEEE Trans. Wirel. Commun. 16(8), 4970–4983 (2017).
S Li, RD Murch, in Proc. IEEE GLOBECOM. Full-duplex wireless communication using transmitter output based echo cancellation, (2011).
M Sohaib, H Nawaz, K Ozsoy, O Gurbuz, I Tekin, A low complexity full-duplex radio implementation with a single antenna (accepted to appear.)IEEE Trans. Veh. Technol (2017).
F Shu, J Wang, J Li, R Chen, W Chen, Pilot optimization, channel estimation, and optimal detection for full-duplex OFDM systems with IQ imbalances. IEEE Trans. Veh. Technol. 66(8), 6993–7009 (2017).
A Masmoudi, T Le-Ngoc, Channel estimation and self-interference cancellation in full-duplex communication systems. IEEE Trans. Veh. Technol. 66(1), 321–334 (2017).
A Koohian, H Mehrpouyan, M Ahmadian, M Azarbad, in Proc. IEEE ICC. Bandwidth efficient channel estimation for full duplex communication systems, (2015).
A Koohian, H Mehrpouyan, AA Nasir, S Durrani, SD Blostein, in Proc. IEEE ICC. Residual self-interference cancellation and data detection in full-duplex communication systems, (2017).
F Mazzenga, Channel estimation and equalization for M-QAM transmission with a hidden pilot sequence. IEEE Trans. Broadcast. 46(2), 170–176 (2000).
JK Tugnait, W Luo, On channel estimation using superimposed training and first-order statistics. IEEE Commun. Lett. 7(9), 413–415 (2003).
E de Carvalho, DTM Slock, Blind and semi-blind FIR multichannel estimation: (global) identifiability conditions. IEEE Trans. Signal Process. 52(4), 1053–1064 (2004).
S Abdallah, IN Psaromiligkos, EM-based semi-blind channel estimation in amplify-and-forward two-way relay networks. IEEE Wirel. Commun. Lett. 2(5), 527–530 (2013).
S Abdallah, IN Psaromiligkos, Blind channel estimation for amplify-and-forward two-way relay networks employing M-PSK modulation. IEEE Trans. Signal Process. 60(7), 3604–3615 (2012).
S Zhang, S-C Liew, H Wang, Blind known interference cancellation. IEEE J. Sel. Areas Commun. 31(8), 1572–1582 (2013).
Y Zhu, D Guo, ML Honig, A message-passing approach for joint channel estimation, interference mitigation, and decoding. IEEE Trans. Wirel. Commun. 8(12), 6008–6018 (2009).
E Lehmann, G Casella, Theory of Point Estimation (Springer Verlag, New York, 1998).
L Tong, S Perreau, Multichannel blind identification: from subspace to maximum likelihood methods. Proc. IEEE. 86(10), 1951–1968 (1998).
K Abed-Meraim, W Qiu, Y Hua, Blind system identification. Proc. IEEE. 85(8), 1310–1322 (1997).
PJ Pahl, R Damrath, Mathematical Foundations of Computational Engineering: A Handbook (Springer, Berlin Heidelberg, 2001).
N Loehr, Bijective Combinatorics, 1st ed (Chapman & Hall/CRC, Boca Raton, 2011).
AP Dempster, NM Laird, DB Rubin, Maximum likelihood from incomplete data via the EM algorithm. J. R. Stat. Soc. Ser. B. 39:, 1–38 (1977).
V Melnykov, I Melnykov, Initializing the EM algorithm in Gaussian mixture models with an unknown number of components. Comput. Stat. Data Anal. 56(6), 1381–1395 (2012).
C Biernacki, G Celeux, G Govaert, Choosing starting values for the EM algorithm for getting the highest likelihood in multivariate Gaussian mixture models. Comput. Stat. Data Anal. 41(3-4), 561–575 (2003).
SM Kay, Fundamentals of Statistical Signal Processing: Estimation Theory (Prentice-Hall, Inc., Upper Saddle River, 1993).
S Abdallah, IN Psaromiligkos, Exact Cramer Rao bounds for semiblind channel estimation in amplify-and-forward two-way relay networks employing square QAM. IEEE Trans. Wirel. Commun. 13(12), 6955–6967 (2014).
H Mehrpouyan, SD Blostein, Bounds and algorithms for multiple frequency offset estimation in cooperative networks. IEEE Trans. Wirel. Commun. 10(4), 1300–1311 (2011).
D Tse, P Viswanath, Fundamentals of Wireless Communication (Cambridge University Press, New York, 2005).
E Ahmed, AM Eltawil, All-digital self-interference cancellation technique for full-duplex systems. IEEE Trans. Wirel. Commun. 14(7), 3519–3532 (2015).
M Duarte, A Sabharwal, in Proc. Asilomar Conf. on Signals, Syst. and Computers. Full-duplex wireless communications using off-the-shelf radios: feasibility and first results, (2010).
E Romero-Aguirre, R Parra, AG Orozco, R Carrasco-Alvarez, in Workshop on Signal Processing Systems (SiPS). Full-hardware architectures for data-dependent superimposed training channel estimation, (2011).
G Strang, Linear Algebra and Its Applications (Harcourt Brace Jovanovich Publishers, Essex England, 1988).
R Zamir, A proof of the Fisher information inequality via a data processing argument. IEEE Trans. Inf. Theory. 44(3), 1246–1250 (1998).
Acknowledgements
The authors would like to thank Mohammad Azarbad for insightful discussions and comments.
Funding
This work was supported by the Australian Research Councils Discovery Project Funding Scheme (Project number DP140101133). The work of Abbas Koohian was supported by an Australian Government Research Training Program (RTP) Scholarship. The work of Hani Mehrpouyan was partially funded by the NSF ERAS grand award number 1642865. The work of Steven Blostein was partially funded by the Natural Sciences and Engineering Research Council of Canada 05061-2014.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Additional information
Authors’ contribution
All authors contributed equally to this work. The final manuscript has been read and approved by all authors for submission.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License(http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Koohian, A., Mehrpouyan, H., Nasir, A.A. et al. Superimposed signaling inspired channel estimation in full-duplex systems. EURASIP J. Adv. Signal Process. 2018, 8 (2018). https://doi.org/10.1186/s13634-018-0529-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13634-018-0529-9