- Research Article
- Open access
- Published:
Time-Frequency-Based Speech Regions Characterization and Eigenvalue Decomposition Applied to Speech Watermarking
EURASIP Journal on Advances in Signal Processing volume 2010, Article number: 572748 (2010)
Abstract
The eigenvalues decomposition based on the S-method is employed to extract the specific time-frequency characteristics of speech signals. This approach is used to create a flexible speech watermark, shaped according to the time-frequency characteristics of the host signal. Also, the Hermite projection method is applied for characterization of speech regions. Namely, time-frequency regions that contain voiced components are selected for watermarking. The watermark detection is performed in the time-frequency domain as well. The theory is tested on several examples.
1. Introduction
Digital watermarking has been developed to provide efficient solutions for ownership protection, copyright protection, and authentication of digital multimedia data by embedding a secret signal called the watermark into the cover media. Depending on the applications, two watermarking scenarios are available: robust and fragile. The robust watermarking assumes that the watermark should be resistant to various signal processing techniques called attacks. At the same time, the watermark should be imperceptible. In order to meet these requirements, a number of watermarking techniques have been proposed, many of which are related to speech and audio signals [1–11]. One of the earliest and simplest techniques is based on the LSB coding [1–4]. The watermark embedding is done by altering the individual audio samples represented by 16 bits per sample. The human auditory system is sensitive to the noise introduced by LSB replacement, which limits the number of LSBs that can be imperceptibly modified. The main disadvantage of these methods is their low robustness [1]. In a number of watermarking algorithms, the spread-spectrum technique has been employed [5–7]. The spread spectrum sequence can be embedded in the time domain, FFT coefficients, cepstral coefficients, and so forth. The embedding is performed in a way to provide robustness to common attacks (noise, compression, etc.). Furthermore, several algorithms use the phase of audio signal for watermarking, such are the phase coding and phase modulation approaches [8, 9], assuring good imperceptibility. Namely, imperceptible phase modifications are exploited by the controlled phase alternation of the host signal. However, the fact that they are nonblind watermarking methods (the presence of the original signal is required for watermark detection) limits the number of their applications.
Most of existing watermarking techniques are based on either the time domain or the frequency domain. In both cases, the changes in the signal may decrease the subjective quality, since the time-frequency characteristics of the watermark do not correspond to the time-frequency characteristics of the host signal. This may cause watermark audibility because it will be present in the time-frequency regions where speech components do not exist. In order to adjust the location and the strength of the watermark to the time-varying spectral content of the host signal, a time-frequency domain-based approach is proposed in this paper. The watermark, shaped in accordance with the formants in the time-frequency domain, will be more imperceptible and more robust at the same time.
The time-frequency distributions have been used to characterize the time-varying spectral content of nonstationary signals [12–16]. As the most commonly used, the Wigner distribution can provide an ideal representation for linear frequency-modulated monocomponent signals [12, 15]. For multicomponents signals, the S-method, that is, a cross-terms-free Wigner distribution, can be used [16]. The S-method can be also used to separate the signal components. Note that the signal components separation could be of interest in many applications. In particular, in watermarking it allows creating the watermark that is shaped by using an arbitrary combination of the signal components. The eigenvalues-based S-method decomposition is applied to separate the signal components [17, 18].
In order to provide suitable compromise between imperceptibility and robustness, the watermark should be shaped according to the time-frequency components of speech signal, as proposed in [19, 20]. Therein, the speech components selection is performed by using the time-frequency support function with a certain energy threshold. However, the threshold is chosen empirically and it does not provide sufficient flexibility. Namely, it includes all components with the energy between the maximum and the threshold level.
Therefore, in this paper, the eigenvalue decomposition method is employed to create a time-frequency mask as an arbitrary combination of speech components (formants). Only the components from voiced time-frequency regions are considered [19]. The Hermite projection method-based procedure for regions characterization is applied[21, 22]. The speech regions are reconstructed within the time-frequency plane by using a certain number of Hermite expansion coefficients. The mean square error between the original and reconstructed region is used to characterize dynamics of regions. It allows distinguishing between voiced, unvoiced, and noisy regions. Finally, the watermark embedding and detection are performed in the time-frequency domain. The robustness of the proposed procedure is proved under various common attacks.
The considered watermarking approach can be useful in numerous applications assuming speech signals. These applications include, but are not limited to, the intellectual property rights, such as proof of ownership, speaker verification systems, VoIP, and mobile applications such as cell-phone tracking. Recently, an interesting application of speech watermarking has appeared in air traffic control [11]. The air traffic control relies on voice communication between the aircraft pilot and air traffic control operators. Thus, the embedded digital information can be used for aircraft identification.
The paper is organized as follows. A theoretical background on the time-frequency analysis is given in Section 2. Section 3 describes the speech regions characterization procedure. In Section 4, the formants selection based on the eigenvalues decomposition is proposed. The time-frequency-based watermarking procedure is presented in Section 5. The performance of the proposed procedure is tested on examples in Section 6. Concluding remarks are given in Section 7.
2. Theoretical Background—Time-Frequency Analysis
The simplest time-frequency distribution is the spectrogram. It is defined as a square module of the short-time Fourier transform (STFT) [15]:

where x(t) is a signal while w(t) is a window function.
The time-frequency resolution in spectrogram depends on the window function w(t) (window shape and window width). Namely, if the signal phase is not linear, it cannot simultaneously provide a good time and frequency resolution. Various quadratic distributions have been introduced to improve the spectrogram resolution. Among them, the most commonly used, [1, 14, 15], is the Wigner distribution, defined as follows:

However, for multicomponent signals the Wigner distribution produces a large amount of cross-terms. The S-method has been introduced to reduce or remove the cross-terms while keeping the autoterms concentration as in the Wigner distribution [16]:

A finite frequency domain window is denoted as  . Note that, for
. Note that, for  and
and  , the spectrogram and the pseudo-Wigner distribution are obtained, respectively. By taking the rectangular frequency domain window, the discrete form of the S-method can be written as follows:
, the spectrogram and the pseudo-Wigner distribution are obtained, respectively. By taking the rectangular frequency domain window, the discrete form of the S-method can be written as follows:

where n and k are discrete time and frequency samples. If the minimal distance between autoterms is greater than the window width ( ), the cross-terms will be completely removed. Also, if the autoterms width is equal to
), the cross-terms will be completely removed. Also, if the autoterms width is equal to  , the S-method produces the same autoterms concentration as the Wigner distribution. Moreover, since the convergence within P(l) is fast, in many practical applications a good concentration can be achieved by setting
, the S-method produces the same autoterms concentration as the Wigner distribution. Moreover, since the convergence within P(l) is fast, in many practical applications a good concentration can be achieved by setting  .
.
The advantages of time-frequency representations have also been used to provide an efficient time-varying filtering. The output of the time-varying filter is defined as follows [23]:

where  is a space-varying transfer function (i.e., support function) which is defined as Weyl symbol mapping of the impulse response into the time-frequency domain. Assuming that the signal components are located within the time-frequency regionR
f
, the support function
is a space-varying transfer function (i.e., support function) which is defined as Weyl symbol mapping of the impulse response into the time-frequency domain. Assuming that the signal components are located within the time-frequency regionR
f
, the support function  can be defined as follows:
can be defined as follows:

Although it was initially introduced for signal denoising, the concept of nonstationary filtering can be used to retrieve the signal with specific characteristics from the time-frequency domain.
Therefore, the time-frequency analysis can provide complete information about the time-varying spectral components, even when their number is significant as in the case of speech signals. Namely, these components appear in the time-frequency plane as recognizable time-varying structures that could be used to characterize different speech regions (voiced, unvoiced, noisy, etc.), as proposed in the sequel. Furthermore, the extraction of individual speech components from the time-frequency domain could be useful in many applications assuming speech signals. This is generally a highly demanding task due to the number of speech components. As an effective solution, a method based on the eigenvalues decomposition and the speech signal time-frequency representation is presented in Section 4.
3. Speech Regions Characterization by Using the Fast Hermite Projection Method of Time-Frequency Representation
3.1. Fast Hermite Projection Method
The fast Hermite projection method has been introduced for image expansion into a Fourier series by using an orthonormal system of Hermite functions [21, 22]. Namely, the Hermite functions provide better computational localization in both the spatial and the transform domain, in comparison with the trigonometric functions. The Hermite projection method has been mainly used in image processing applications, such as image filtering, and texture analysis. Here, we provide a brief overview of the method.
The i th order Hermite function is defined as follows:

Generally, the Hermite projection method for two-dimensional signal f(x,y) can be defined as follows:

where  are the two-dimensional Hermite functions while
are the two-dimensional Hermite functions while  are the Hermite coefficients.
are the Hermite coefficients.
In our case, the two-dimensional function f(x,y) is a time-frequency representation of a speech region, which will be represented by a certain number of Hermite coefficients c ij . Note that the number of coefficients c ij depends on the number of the employed Hermite functions. The more functions is used, the less error is introduced in the reconstructed version F(x,y).
However, for the sake of simplicity, the expansion can be performed even along one dimension only. Thus, the decomposition into N Hermite functions can be defined as follows:

where  holds for a fixed
holds for a fixed  while the coefficients of the Hermite expansion are obtained as follows:
while the coefficients of the Hermite expansion are obtained as follows:

Accordingly, the functions  correspond to the rows of the time-frequency representation.
correspond to the rows of the time-frequency representation.
The Hermite coefficients could also be defined by using the Hermite polynomials as follows:

where

is the Hermite polynomial. Thus, the calculation of the Hermite coefficients could be approximated by the Gauss-Hermite quadrature:

where  are zeros of Hermite polynomials while
are zeros of Hermite polynomials while  are associated weights.
are associated weights.
By using Hermite functions instead of Hermite polynomials, the following simplified expression is obtained:

The constants  are obtained by
are obtained by

3.2. Speech Regions Characterization by Using the Concept of Hermite Projection Method
According to (8) or its simplified form (9), the time-frequency representation of a speech region as a two-dimensional function can be expanded into a certain number of Hermite functions. Thus, we may assume that  and
and  , where D denotes the original time-frequency region and D r is the region reconstructed from the Hermite expansion coefficients. The difference between D and D r will depend on the number of Hermite functions used for the expansion, as well as on the complexity of the considered region.
, where D denotes the original time-frequency region and D r is the region reconstructed from the Hermite expansion coefficients. The difference between D and D r will depend on the number of Hermite functions used for the expansion, as well as on the complexity of the considered region.
The S-method is used for time-frequency representation of speech signals. By observing time-frequency characteristics, a significant difference between noise, pauses, and speech can be noted. Moreover, the voiced and unvoiced speech parts are significantly different. The voiced parts are characterized by higher energy and complex structure.
Let us consider different regions of speech signal having different structure complexity. The fast Hermite projection method is applied to these regions. By using a small number of Hermite functions, a certain error will be intentionally produced. The regions with simpler structures will have smaller errors, and vise versa. The mean square errors are calculated as follows:

where D
i
(t,ω) and  denote the original and the reconstructed
denote the original and the reconstructed  th region from
th region from  while d1 and d2 are dimensions of the regions. Thus, the region
while d1 and d2 are dimensions of the regions. Thus, the region  , containing either noise or unvoiced sounds, will produce a significantly lower MSE than the region
, containing either noise or unvoiced sounds, will produce a significantly lower MSE than the region  with complex voiced structures. The dimensions
with complex voiced structures. The dimensions  and
and  are the same for all regions. They are chosen experimentally such that the region includes most of the sound components.
are the same for all regions. They are chosen experimentally such that the region includes most of the sound components.
An illustration of various regions within a speech signal is given in Figure 1. The MSEs are presented in Table 1 (ten Hermite functions have been used). It can be observed that the noisy regions (without speech components) have MSEs below 10-3 while the regions containing complex formant structures have a large value of MSE (generally, it is significantly above 103). The MSEs for the unvoiced regions are between the two cases.

Illustration of various regions within the speech signal.
Therefore, based on the numerous experiments, the voiced regions with emphatic formants are determined by  . These regions have a rich formants structure and they will be appropriate for watermarking. A set of arbitrary selected formants could be used to shape the watermark. It will provide a flexibility to create the watermark with very specific time-frequency characteristics. The combination of time-frequency components could be an additional secret key to increase robustness and security of this procedure.
. These regions have a rich formants structure and they will be appropriate for watermarking. A set of arbitrary selected formants could be used to shape the watermark. It will provide a flexibility to create the watermark with very specific time-frequency characteristics. The combination of time-frequency components could be an additional secret key to increase robustness and security of this procedure.
4. Eigenvalue Decomposition Based on the Time-Frequency Distribution
The S-method produces a representation that is equal to or very close approximates the sum of the Wigner distributions calculated for each signal component separately. This property is used to introduce the eigenvalue decomposition method. Let us start from the discrete form of the Wigner distribution

where m is a discrete lag coordinate. Consequently, the inverse of the Wigner distribution can be written as follows:

where  and
and  . Furthermore, for a multicomponent signal,
. Furthermore, for a multicomponent signal,  , (18) can be written as follows [17, 18]:
, (18) can be written as follows [17, 18]:

Having in mind that the S-method is  , the previous equation can be written as follows:
, the previous equation can be written as follows:

By introducing the following notation:

we have

The eigenvalue decomposition of the matrix  is defined as follows [17, 18]:
is defined as follows [17, 18]:

where  are eigenvalues and
are eigenvalues and  are eigenvectors of R
SM
. Furthermore,
are eigenvectors of R
SM
. Furthermore,  (
( is the energy of the i th component), and
is the energy of the i th component), and  for
for  , that is,
, that is,

where  denotes the Kronecker symbol.
denotes the Kronecker symbol.
As it will be explained in the sequel, the autocorrelation matrix  is calculated according to (21) for each time-frequency region
is calculated according to (21) for each time-frequency region  (obtained by using the S-method). Then, the eigenvalue decomposition is applied to
(obtained by using the S-method). Then, the eigenvalue decomposition is applied to  according to (23), resulting in eigenvalues and eigenvectors. Each of these components is characterized by a certain location in the time-frequency plane.
according to (23), resulting in eigenvalues and eigenvectors. Each of these components is characterized by a certain location in the time-frequency plane.
Once separated, they could be further combined in various ways to provide an arbitrary time-frequency map used as a support function in watermark modelling.
4.1. Selection of Speech Formants Suitable for Watermarking
After the regions have been selected, the formants that will be used for watermark modeling need to be determined. This can be realized by considering the formants whose energy is above a certain floor value, as it is done in [19]. Namely, the energy floor was defined as a portion of the maximum energy value of the S-method within the selected region. Therein, it has been assumed that the significant components have approximately the same energy. However, this may not always be the case as the number of selected components could vary between different regions. Consequently, it may lead to a variable amount of watermark within different regions. Thus, in order to overcome these difficulties, the eigenvalue decomposition method is employed for speech formants selection.
For each selected region within the S-method  , the autocorrelation matrix
, the autocorrelation matrix  is calculated according to (21). The eigenvalues and eigenvectors are obtained by using the eigenvalues decomposition of
is calculated according to (21). The eigenvalues and eigenvectors are obtained by using the eigenvalues decomposition of  . The eigenvectors are equal to the signal components up to the phase and amplitude constants. Furthermore, the number of components of interest can be limited to K. Each of these components can be reconstructed as
. The eigenvectors are equal to the signal components up to the phase and amplitude constants. Furthermore, the number of components of interest can be limited to K. Each of these components can be reconstructed as  . Thus, a signal that contains
. Thus, a signal that contains  components of the original speech is obtained as:
components of the original speech is obtained as:

The S-method of the signal  will be denoted as
will be denoted as  . Note that it represents a time-frequency map that is used for watermark modelling.
. Note that it represents a time-frequency map that is used for watermark modelling.
The original S-method, the S-method of reconstructed signal, as well as the corresponding eigenvalues are shown in Figure 2. The reconstructed formants that will be used in watermarking procedure and their support function are zoomed in Figure 3. The formants separated by the proposed eigenvalues decomposition are shown in Figure 4 (although  is used, only ten formants are related to the positive frequency axes).
is used, only ten formants are related to the positive frequency axes).

An illustration of the formants reconstruction by using the eigenvalues decomposition method.

The reconstructed region of formants and the corresponding support function.

The formants components isolated by using the eigenvalues decomposition method.
5. Time-Frequency-Based Speech Watermarking Procedure
5.1. Watermark Modelling and Embedding
The time-frequency representation of the formants selected from  is used as a time-frequency mask to shape the watermark. This time-frequency representation is an arbitrary combination of decomposed formants. The procedure for watermark modelling can be described through the following steps:
is used as a time-frequency mask to shape the watermark. This time-frequency representation is an arbitrary combination of decomposed formants. The procedure for watermark modelling can be described through the following steps:
-
(1)
consider a random sequence
 ,
, -
(2)
calculate the STFT of the sequence s denoted as
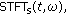
-
(3)
the support function
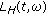 is defined by using
is defined by using  as follows:
as follows: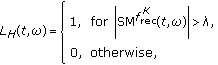 (26)
(26)where λ could be set to zero or, for a sharpen mask, to a small positive value,
-
(4)finally,
the watermark is obtained at the output of the time-varying filter as follows [19]:
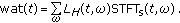 (27)
(27)
 ,
,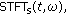
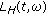 is defined by using
is defined by using  as follows:
as follows: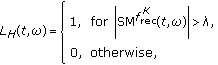
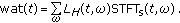
The signal is watermarked according to

where  is the STFT of the host signal within the selected region.
is the STFT of the host signal within the selected region.
5.2. Watermark Detection
Following the similar concept as in the embedding process, the watermark detection is performed, within the time-frequency domain, by using the standard correlation detector [19]

where  and
and  are the S-method of the watermarked signal and watermark, respectively.
are the S-method of the watermarked signal and watermark, respectively.
The watermark detection is tested by using a set of wrong keys (trials), created in the same way as the watermark. Hence, the successful detection is provided if

that is, if

holds for any wrong trial.
Note that the S-method is used in the detection procedure. The detection performance is improved due to the higher components concentration. Additionally, for larger values of L (in the S-method), the cross-terms appear and they are included in detection, as well [19]. Namely, the cross-terms also contain the watermark, and hence they contribute to the watermark detection. The detection performance is tested by using the following measure of detection quality [24, 25]:

where  and
and  represent the mean value and the standard deviation of the detector responses, while the subscripts w
r
and w
w
indicate the right and wrong keys (trials), respectively. The corresponding probability of error is calculated as follows:
represent the mean value and the standard deviation of the detector responses, while the subscripts w
r
and w
w
indicate the right and wrong keys (trials), respectively. The corresponding probability of error is calculated as follows:

6. Examples
Example 1.
In this example, we will demonstrate the advantages of the proposed formants selection procedure over the threshold-based procedure given in [19]. Namely, two cases are observed.
-
(1)
Formants whose energy is above a threshold ξ are selected for watermarking. The threshold is determined as a portion of the S-method's maximum value
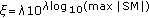 (
( is the maximum energy value of the S-method within the observed region), [19]. Thus, the threshold is adapted to the maximum energy within the region.
is the maximum energy value of the S-method within the observed region), [19]. Thus, the threshold is adapted to the maximum energy within the region. -
(2)
The eigenvalues-based decomposition is used to create an arbitrary composed time-frequency map.
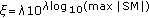 (
( is the maximum energy value of the S-method within the observed region), [
is the maximum energy value of the S-method within the observed region), [In the first case, the number of selected formants depends on the threshold value. An illustration of formants selected by using two different thresholds  and
and 
 is given in Figure 5(a). Note that a higher threshold
is given in Figure 5(a). Note that a higher threshold  (calculated for
(calculated for  ) selects only the strongest low-frequency formants (Figure 5(a) left). On the other hand, a lower threshold
) selects only the strongest low-frequency formants (Figure 5(a) left). On the other hand, a lower threshold  (for
(for  ) yields more components (Figure 5(a) right). However, it is difficult to control their number. Also, the amount of signal energy is varying through different time-frequency regions. Thus, an optimal threshold should be determined for each region. This is a demanding task and it could cause difficulties in practical applications. Namely, if the threshold selects too many components, the watermark may produce perceptual changes. Otherwise, if there are not enough components, it could be difficult to detect the watermark. An illustration of two different regions, obtained by using the threshold ξ with
) yields more components (Figure 5(a) right). However, it is difficult to control their number. Also, the amount of signal energy is varying through different time-frequency regions. Thus, an optimal threshold should be determined for each region. This is a demanding task and it could cause difficulties in practical applications. Namely, if the threshold selects too many components, the watermark may produce perceptual changes. Otherwise, if there are not enough components, it could be difficult to detect the watermark. An illustration of two different regions, obtained by using the threshold ξ with  , is given in Figure 5(b). Although the threshold is calculated for both regions in the same way
, is given in Figure 5(b). Although the threshold is calculated for both regions in the same way  , the number of selected components is significantly different. The components in the first region (Figure 5(b)left) are approximately at the same energy level. Thus, a significant number of them will be selected with this threshold. However, in the second region (Figure 5(b) right), the energy varies for different components and the given threshold selects just a few strongest components.
, the number of selected components is significantly different. The components in the first region (Figure 5(b)left) are approximately at the same energy level. Thus, a significant number of them will be selected with this threshold. However, in the second region (Figure 5(b) right), the energy varies for different components and the given threshold selects just a few strongest components.
On the other hand, the eigenvalues decomposition method provides a flexible choice of the components number. Furthermore, it is possible to arbitrarily combine the components that belong to the low-, middle- or high-frequency regions. Consequently, an arbitrary time-frequency mask can be composed as a combination of signal components. It will be used for watermark modelling. Some illustrative examples are shown in Figure 6. Each component is available separately and we can freely choose the number and positions of the components that we intend to use within the time-frequency mask. For instance, when observing the region in Figure 5(a) (right), we can combine a few strong low-frequency components with a few high-frequency components, as shown in Figure 6 (upper row, left), which could be difficult to achieve by using the threshold-based approach.

(a) The components selected by two different thresholds  and
and  within the same region. (b) The components selected within two different regions when the threshold is
within the same region. (b) The components selected within two different regions when the threshold is  .
.

Illustrations of components selections provided by the proposed method.
Example 2.
The speech signal with maximal frequency 4 kHz is considered. A voiced time-frequency region is used for watermark modelling and embedding. The procedure is implemented in Matlab 7. The STFT is calculated using the rectangular window with 1024 samples, and then, it is used to obtain the signal S-method. Since the speech components are very close to each other in the time-frequency domain, the S-method is calculated with the parameter  to avoid the presence of cross-terms. After calculating the inverse transform (the IFFT routine is applied to the S-method), the eigenvalues and eigenvectors are obtained by using the Matlab built-in function (eigs). Twenty eigenvectors are selected, weighted by the corresponding eigenvalues, and merged into a signal with desired components. Furthermore, the S-method is calculated for the obtained signal providing the support function L
H
for watermark shaping. Here, the Hanning window with 512 samples is used for the STFT calculation while in the S-method
to avoid the presence of cross-terms. After calculating the inverse transform (the IFFT routine is applied to the S-method), the eigenvalues and eigenvectors are obtained by using the Matlab built-in function (eigs). Twenty eigenvectors are selected, weighted by the corresponding eigenvalues, and merged into a signal with desired components. Furthermore, the S-method is calculated for the obtained signal providing the support function L
H
for watermark shaping. Here, the Hanning window with 512 samples is used for the STFT calculation while in the S-method  . The watermark is created as a pseudorandom sequence, whose length is determined by the length of the voiced speech region (approximately 1300 samples). The STFT of the watermark is also calculated by using the Hanning window with 512 samples. It is then multiplied by the function L
H
to shape its time-frequency characteristics. For each of the right keys (watermarks), a set of 50 wrong trials is created following the same modelling procedure as for the right keys. The correlation detector based on the S-method coefficients is applied with
. The watermark is created as a pseudorandom sequence, whose length is determined by the length of the voiced speech region (approximately 1300 samples). The STFT of the watermark is also calculated by using the Hanning window with 512 samples. It is then multiplied by the function L
H
to shape its time-frequency characteristics. For each of the right keys (watermarks), a set of 50 wrong trials is created following the same modelling procedure as for the right keys. The correlation detector based on the S-method coefficients is applied with  .
.
The proposed approach preserves favourable properties of the time-frequency-based watermarking procedure [19], which outperforms some existing techniques. An illustration of normalized detector responses for right keys (red line) and wrong trials (blue line) is shown in Figure 7. Furthermore, the robustness is tested against several types of attacks, all being commonly used in existing procedures [5, 8, 10]. Namely, in the existing algorithms, the usual amount of attacks is time scaling up to 4%, wow up to 0.5% or 0.7%, echo 50 ms or 100 ms [5], and so forth, providing the probability of error of order 10-6. We have applied the same types of attacks, but with higher strength, showing that the proposed approach provides robustness even in this case. The proposed procedure is tested on: mp3 compression with constant bit rate (128 Kbps), mp3 compression with variable bit rate (40–50 Kbps), delay (180 ms), Echo (200 ms), pitch scaling (5%), wow (delay 20%), flutter, and amplitude normalization. The measures of detection quality and corresponding probabilities of error are calculated according to (32). The results are given in Table 2. Note that the proposed method provides very low probabilities of error, mostly of order 10-7, even in the presence of stronger attacks. Also, the robustness to pitch scaling has been improved when compared to the results reported in [19].
As expected, the detection results are similar as in [19] where the threshold is well adapted to the energy within the considered speech region. However, in the previous example, it is shown that the optimal threshold selection for one region does not have to be optimal for the other ones. Thus, it can include only a few formants (Figure 5(b) right). Consequently, the detection performance decreases, due to the smaller number of components available for correlation in the time-frequency domain. The procedure performance can vary significantly for different regions, since it is not easy to adjust thresholds separately for each of them. In this example, a single threshold is used. The detection results obtained for the region where the threshold is not optimal are shown in Figure 8. The measures of detection quality have decreased, as shown in Table 3. From this point of view, the flexibility of components selection provided by the proposed approach assures more reliable results.
The proposed procedure is secure in the following sense: the watermark is shaped and added directly to the formants in the time-frequency domain, and thus, it is hard to remove it without the key, which is assumed to be private (hidden). Namely, supposing that the quality of voiced data is important for the application, any attempt to remove the watermark will produce significant quality degradation. In order to achieve higher degree of security, the watermarking can be combined with the cryptography [26]. For example, the cryptography can be used to prove the presence of a specific watermark in a digital object without compromising the watermark security.

The normalized detector responses for a set of right keys and wrong trials (for the proposed approach).

The normalized detector responses for a set of right keys and wrong trials; the threshold is not optimal for the considered region.
7. Conclusion
The paper proposes an improved formants selection method for speech watermarking purposes. Namely, the eigenvalues decomposition based on the S-method is used to select different formants within the time-frequency regions of speech signal. Unlike the threshold-based selection, the proposed method allows for an arbitrary choice of components number and their positions in the time-frequency plane. This method results in better performance when compared to the method based on a single threshold. An additional improvement is achieved by adapting the Hermite projection method for characterization of speech regions. This has led to an efficient selection of voiced regions with formants suitable for watermarking. Finally, the watermarking procedure based on the proposed approach provides greater flexibility in implementation and it is characterised by reliable detection results.
References
Pal SK, Saxena PK, Mutto SK: The future of audio steganography. Proceedings of Pacific Rim Workshop on Digital Steganography, 2002
Cvejic N, Seppänen T: Increasing the capacity of LSB based audio steganography. Proceedings of the 5th IEEE International Workshop on Multimedia Signal Processing, December 2002, St. Thomas, Virgin Islands, USA 336-338.
Shieh C-S, Huang H-C, Wang F-H, Pan J-S: Genetic watermarking based on transform-domain techniques. Pattern Recognition 2004, 37(3):555-565. 10.1016/j.patcog.2003.07.003
Wang F-H, Jain LC, Pan J-S: VQ-based watermarking scheme with genetic codebook partition. Journal of Network and Computer Applications 2007, 30(1):4-23. 10.1016/j.jnca.2005.08.002
Kirovski D, Malvar HS: Spread-spectrum watermarking of audio signals. IEEE Transactions on Signal Processing 2003, 51(4):1020-1033. 10.1109/TSP.2003.809384
Malik H, Ansari R, Khokhar A: Robust audio watermarking using frequency-selective spread spectrum. IET Information Security 2008, 2(4):129-150. 10.1049/iet-ifs:20070145
Cvejic N, Keskinarkaus A, Seppanen T: Audio watermarking using m-sequences and temporal masking. Proceedings of IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, October 2001, New York, NY, USA 227-230.
Cvejic N: Algorithms for audio watermarking and steganography, Academic dissertation. University of Oulu, Oulu, Finland; 2004.
Kuo S-S, Johnston JD, Turin W, Quackenbush SR: Covert audio watermarking using perceptually tuned signal independent multiband phase modulation. Proceedings of IEEE International Conference on Acoustic, Speech and Signal Processing, May 2002, Orlando, Fla, USA 1753-1756.
Xiang S, Huang J: Histogram-based audio watermarking against time-scale modification and cropping attacks. IEEE Transactions on Multimedia 2007, 9(7):1357-1372.
Hofbauer K, Hering H, Kubin G: Speech watermarking for the VHF radio channel. Proceedings of EUROCONTROL Innovative Research Workshop (INO '05), December 2005, Brétigny-sur-Orge, France 215-220.
Cohen L: Time-frequency distributions—a review. Proceedings of the IEEE 1989, 77(7):941-981. 10.1109/5.30749
Loughlin PJ: Scanning the special issue on time-frequency analysis. Proceedings of the IEEE 1996, 84(9):1195. 10.1109/JPROC.1996.535239
Boashash B: Time-Frequency Analysis and Processing. Elsevier, Amsterdam, The Netherlands; 2003.
Hlawatsch F, Boudreaux-Bartels GF: Linear and quadratic time-frequency signal representations. IEEE Signal Processing Magazine 1992, 9(2):21-67. 10.1109/79.127284
Stankovic L: Method for time-frequency analysis. IEEE Transactions on Signal Processing 1994, 42(1):225-229. 10.1109/78.258146
Stanković L, Thayaparan T, Daković M: Signal decomposition by using the S-method with application to the analysis of HF radar signals in sea-clutter. IEEE Transactions on Signal Processing 2006, 54(11):4332-4342.
Thayaparan T, Stanković L, Daković M: Decomposition of time-varying multicomponent signals using time-frequency based method. Proceedings of Canadian Conference on Electrical and Computer Engineering (CCECE '06), May 2006, Ottawa, Canada 60-63.
Stanković S, Orović I, Žarić N: Robust speech watermarking procedure in the time-frequency domain. EURASIP Journal on Advances in Signal Processing 2008, 2008:-9.
Stanković S, Orović I, Žarić N, Ioana C: An approach to digital watermarking of speech signals in the time-frequency domain. Proceedings of the 48th International Symposium focused on Multimedia Signal Processing and Communications (ELMAR '06), June 2006, Zadar, Croatia 127-130.
Kortchagine D, Krylov A: Image database retrieval by fast Hermite projection method. Proceedings of the 15th International Conference on Computer Graphics and Applications (GraphiCon '05), June 2005, Novosibirsk Akademgorodok, Russia 308-311.
Kortchagine D, Krylov A: Projection filtering in image processing. Proceedings of the 10th International Conference on Computer Graphics and Applications (GraphiCon '00), August-September 2000, Moscow, Russia 42-45.
Stanković S: About time-variant filtering of speech signals with time-frequency distributions for hands-free telephone systems. Signal Processing 2000, 80(9):1777-1785. 10.1016/S0165-1684(00)00087-6
Heeger D: Signal Detection Theory. Department of Psychiatry, Stanford University, Stanford, Calif, USA; 1997.
Wickens TD: Elementary Signal Detection Theory. Oxford University Press, Oxford, UK; 2002.
Adelsbach A, Katzenbeisser S, Sadeghi A-R: Watermark detection with zero-knowledge disclosure. Multimedia Systems 2003, 9(3):266-278. 10.1007/s00530-003-0098-z
Acknowledgment
This work is supported by the Ministry of Education and Science of Montenegro.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License (https://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Orović, I., Stanković, S. Time-Frequency-Based Speech Regions Characterization and Eigenvalue Decomposition Applied to Speech Watermarking. EURASIP J. Adv. Signal Process. 2010, 572748 (2010). https://doi.org/10.1155/2010/572748
Received:
Revised:
Accepted:
Published:
DOI: https://doi.org/10.1155/2010/572748