- Research
- Open access
- Published:
On a unified framework for linear nuisance parameters
EURASIP Journal on Advances in Signal Processing volume 2017, Article number: 4 (2017)
Abstract
Estimation problems in the presence of deterministic linear nuisance parameters arise in a variety of fields. To cope with those, three common methods are widely considered: (1) jointly estimating the parameters of interest and the nuisance parameters; (2) projecting out the nuisance parameters; (3) selecting a reference and then taking differences between the reference and the observations, which we will refer to as “differential signal processing.” A lot of literature has been devoted to these methods, yet all follow separate paths.
Based on a unified framework, we analytically explore the relations between these three methods, where we particularly focus on the third one and introduce a general differential approach to cope with multiple distinct nuisance parameters. After a proper whitening procedure, the corresponding best linear unbiased estimators (BLUEs) are shown to be all equivalent to each other. Accordingly, we unveil some surprising facts, which are in contrast to what is commonly considered in literature, e.g., the reference choice is actually not important for the differencing process. Since this paper formulates the problem in a general manner, one may specialize our conclusions to any particular application. Some localization examples are also presented in this paper to verify our conclusions.
1 Introduction
The problem of estimating unknown parameters of interest \(\mathbf {x} \in \mathbb {R}^{L\times 1}\) observed through a linear transformation \(\mathbf {H} \in \mathbb {R}^{N\times L}\) (N>L), and corrupted by additive noise \(\mathbf {n} \in \mathbb {R}^{N \times 1}\), has been well studied and considered in a wide variety of fields [1]. However, the observations \(\mathbf {y}\in \mathbb {R}^{N \times 1}\) are sometimes also influenced by unknown linear nuisance parameters, denoted by \(\mathbf {u} \in \mathbb {R}^{M \times 1}\) which enter y through the linear transformation \(\mathbf {G} \in \mathbb {R}^{N \times M}\) (N>M). For instance, these nuisance parameters could be some common offsets such as the transmit time, the clock bias, and the transmit power in time-of-arrival (TOA) or received signal strength (RSS) based localization [2], or they could represent some redundant signals like the undesired signatures in hyperspectral imaging [3]. In fact, an estimation problem with linear nuisance parameters widely exists in many other fields such as communications [4–6], source separation [7], and machine learning [8, 9]. Though only Bayesian approaches are generally studied in case of nuisance parameters [1, 10, 11], in this paper, we mainly adopt deterministic approaches, for which we first formulate our general model with linear nuisance parameters as
where we assume that
-
1.
The concatenation of H and G has full column rank, i.e., Rank([H G])=L+M;
-
2.
The noise n is zero-mean, i.e., the expected value of n is E(n)=0;
-
3.
The noise n is white (e.g., after whitening), i.e., the covariance matrix Σ n is (scaled) identity Σ n =σ 2 I N , where I N is the N×N identity matrix.
Note the noise n does not have to be Gaussian distributed1, although it is true for many cases.
To cope with this kind of problem in case u is deterministic, three methods are often considered: (1) the joint estimation approach estimates the unknown x together with the unknown nuisance term u (e.g., the location and the unknown clock bias in [12]); (2) the orthogonal subspace projection (OSP) approach projects out the nuisance term u such that the resulting observation vector is only subject to x (e.g., the extraction of the desired signature in [13]); (3) the differential signal processing approach firstly chooses a reference and then estimates x from the differences between the reference and the observations [14–18]. Note that these methods obviously result in three distinct observation sets with different signal-to-noise ratios (SNRs), which will greatly influence the estimation performance. Therefore, a vast amount of research has been conducted on these methods, though all follow separate paths. Admittedly, some early results have been reported bridging the first two methods. For instance, the famous OSP-based solution using a matched filter to maximize the output SNR proposed in [19] was later on proven to be equivalent to the least squares (LS) approach based on the joint estimation [20, 21]. However, the proposed differential approaches are still widely regarded as a common but distinct way to cope with linear nuisance parameters. One of the most famous applications is time-based localization (TOA or time-difference-of-arrival (TDOA)), where many papers exist on selecting an optimal reference [22–24], constructing an optimal observation subset [25–27] or just using the full observation set adopting each sample as a reference [28–30]. All these issues never occur in the first two methods due to the fact that they are free of a reference. In a nutshell, there still seems to be a huge and inevitable gap between the differential approaches and the other two.
This paper analytically investigates the relations between all three methods, where the corresponding best linear unbiased estimators (BLUEs) are presented and discussed. Since the general framework in (1) is used throughout this paper, all the conclusions apply to any kind of problem that can be written in this form, which is exactly the strength of this paper. We also present some localization examples to verify our conclusions. To summarize, the main contributions of this paper are listed below.
-
1.
For the first time, we extend the differential signal processing approach to a more general framework, which can cope with multiple nuisance parameters, whereas most existing methods consider a single nuisance parameter.
-
2.
Surprisingly, the BLUEs of the three considered methods are proven rigorously to be identical to each other if an appropriate preprocessing step is used. This might be expected or known w.r.t. the first two methods, but the equivalence with differential methods has never been reported before.
-
3.
Compared with the joint estimation method, which directly utilizes all the original observations, none of the other two methods suffers any information loss.
-
4.
Although differential methods seem to rely on the selected reference, selecting the right reference is not important since there is no actual trace of the selected reference in the corresponding BLUE. This is in sharp contrast to what is commonly considered in literature.
-
5.
As far as the differencing process is concerned, the differential observation set associated with a single reference already preserves the full data information.
The rest of this paper is organized as follows. Section 2 presents the relations between the three considered methods. Some examples of source localization are shown and numerically studied to support our conclusions in Section 3. Finally, Section 4 summarizes this paper.
2 Handling linear nuisance parameters
In this section, we study the relations between the joint estimation, the OSP-based estimation, and the differential estimation by investigating their corresponding BLUEs, where for the first time, a general differential approach is introduced coping with multiple nuisance parameters.
2.1 Joint estimation
The joint least squares (JLS) estimate of x and u, based on the model (1), is given by
where we have used the fact that the augmented matrix [H G] has a full column rank. Obviously, \(\hat {\mathbf {x}}_{\text {jls}}\) is the BLUE, since n is the zero-mean white noise, according to the Gauss-Markov theorem [1].
2.2 OSP-based estimation
If we prefer to project out the nuisance term u, an orthogonal subspace projector can be formulated [19] as
where [·]† indicates the pseudo-inverse which is given by \(\mathbf {G}^{\dagger }\triangleq (\mathbf {G}^{T}\mathbf {G})^{-1} \mathbf {G}^{T}\), since G is assumed to have a full column rank. Applying \(\mathbf {P}_{\mathbf {G}}^{\perp }\) to our original model in (1) results in a new model
where the impact of the nuisance term u is eliminated. Due to the symmetry and the idempotence of an orthogonal subspace projector, i.e., \(\mathbf {P}_{\mathbf {G}}^{\perp }=\mathbf {P}_{\mathbf {G}}^{\perp T}\) and \(\mathbf {P}_{\mathbf {G}}^{\perp }=\mathbf {P}_{\mathbf {G}}^{\perp 2}\), we obtain the covariance matrix of the model noise in (4) as \(\boldsymbol {\Sigma }_{\mathbf {P}_{\mathbf {G}}^{\perp } \mathbf {n}}=\sigma ^{2} \mathbf {P}_{\mathbf {G}}^{\perp }\mathbf {P}_{\mathbf {G}}^{\perp T}=\sigma ^{2} \mathbf {P}_{\mathbf {G}}^{\perp }\). Then, following the OSP-based model (4), the corresponding LS optimization problem can be formulated as
which leads to the following OSP-based LS estimate Type I of x
However, the model noise \(\mathbf {P}_{\mathbf {G}}^{\perp }\mathbf {n}\) in (4) is not white, i.e., \(\boldsymbol {\Sigma }_{\mathbf {P}_{\mathbf {G}}^{\perp } \mathbf {n}}\) is not a (scaled) identity. Moreover, the orthogonal subspace projector \(\mathbf {P}_{\mathbf {G}}^{\perp }\) is obviously singular, which implies that the covariance matrix \(\boldsymbol {\Sigma }_{\mathbf {P}_{\mathbf {G}}^{\perp } \mathbf {n}}\) is not invertible and hence can not be used to whiten the model (4). Therefore, it is very difficult to decide at this point whether \(\hat {\mathbf {x}}_{\text {osp}-1}\) is the BLUE or not.
To cope with that, we need to introduce another type of OSP-based LS estimator for x. If this estimator can be shown to be the BLUE and can also be proven equivalent to \(\hat {\mathbf {x}}_{\text {osp}-1}\), then we can conclude that both of them are the BLUE.
Assume that \(\mathbf {U}_{n} \in \mathbb {R}^{N \times (N-M) }\) contains orthonormal basis vectors spanning the null space of G. Then, the idea of this second OSP-based estimator is to adopt the null space of G to remove the impact of u. More specifically, pre-multiplying \( \mathbf {U}_{n}^{T}\) on both sides of our original model leads to
Note that (4) can be obtained from (7) by multiplying it on both sides with U n since \(\mathbf {U}_{n}\mathbf {U}_{n}^{T}=\mathbf {P}_{\mathbf {G}}^{\perp }\) [31], and hence these two models are basically equivalent. We can also see that, since U n is an isometry, the model noise \(\mathbf {U}_{n}^{T}\mathbf {n}\) remains white, i.e., the covariance matrix of \(\mathbf {U}_{n}^{T}\mathbf {n}\) is \(\boldsymbol {\Sigma }_{\mathbf {U}_{n}^{T}\mathbf {n}}=\sigma ^{2}\mathbf {U}_{n}^{T}\mathbf {U}_{n}=\sigma ^{2}\mathbf {I}_{N-M}\), which means that the LS estimate of this model is the BLUE.
Applying the LS criterion to the model (7) results in the optimization problem
from which we can obtain the OSP-based LS estimate type II of x as
Due to the fact that \(\mathbf {U}_{n}\mathbf {U}_{n}^{T}=\mathbf {P}_{\mathbf {G}}^{\perp }\), we obtain the equivalence \(\hat {\mathbf {x}}_{\text {osp}-1} \equiv \hat {\mathbf {x}}_{\text {osp}-2}\) and hence both estimators represent the BLUE. In the later simulations, these two OSP-based BLUEs will be considered together for convenience.
Finally, to end this subsection, we would like to focus on the equivalence between the joint estimation and the OSP-based estimation approaches. In fact, the equivalence between \(\hat {\mathbf {x}}_{\text {jls}}\) and \(\hat {\mathbf {x}}_{\text {osp}-1}\) is already known [20, 21, 32], but we found it useful to revisit this result from a different viewpoint. To be explicit, applying the block-wise inversion to (2), we can easily rewrite the joint LS estimate of x and u as
where \(\mathbf {M}_{\mathbf {G}} \triangleq (\mathbf {H}^{T}\mathbf {P}_{\mathbf {G}}^{\perp }\mathbf {H})^{-1}\) and \(\mathbf {M}_{\mathbf {H}}\triangleq (\mathbf {G}^{T} \mathbf {P}_{\mathbf {H}}^{\perp } \mathbf {G})^{-1}\) with \(\mathbf {P}_{\mathbf {H}}^{\perp }\triangleq \mathbf {I}-\mathbf {H} \mathbf {H}^{\dagger }\). From (10), we can directly observe that \(\hat {\mathbf {x}}_{\text {jls}}=\mathbf {M}_{\mathbf {G}} \mathbf {H}^{T}\mathbf {P}_{\mathbf {G}}^{\perp } \mathbf {y}\) and hence
where the equivalence between \(\hat {\mathbf {x}}_{\text {jls}}\) and \(\hat {\mathbf {x}}_{\text {osp}-2}\) is an interesting observation that has never been directly reported before, to the best of our knowledge.
2.3 Differential signal processing
In this subsection, we would like to examine differential approaches. This method firstly selects a reference and then removes the impact of u by taking differences between the observations and the reference. To be specific, if the jth observation y j is selected as the reference, a new differential observation set can be constructed as
where
with 1, the all-one matrix (sizes are mentioned in subscript if needed) and the size of the observation set are reduced to N−1 since j is fixed for every element in d j . This type of observation set is very popular and has wide applications in source localization and many other areas. Clearly, it can only be used to remove a single nuisance parameter in case G=1 N×1.
One may also suggest to select the average of the observations as the reference [16, eq. (28)], thus leading to another kind of differential observation set, given by
where \(\mathbf {P}_{\mathbf {1}_{N\times 1}}^{\perp } \triangleq \mathbf {I}-\mathbf {1}_{N\times 1} \mathbf {1}_{N\times 1}^{\dagger }= \mathbf {I}_{N}-{1 \over N} \mathbf {1}_{N \times N} \). Sometimes, the use of this type of observation set to eliminate the nuisance parameters can be implicit [4], i.e., taking the average of the observations is not clearly pointed out. However, this case can obviously be linked to the OSP-based estimation with a single nuisance parameter in case G=1 N×1. Therefore, we are more interested in the simple differencing process of (11), where the reference index j seems to play a significant role.
As already pointed out, (11) only eliminates one nuisance parameter. Nevertheless, we would like to extend this to tackle multiple nuisance parameters, i.e., we would like to relax the constraint G=1 N×1 to rank(G)=M≥1. The idea we will adopt here is based on eliminating the impact of the nuisance parameters one by one, which requires M differencing steps.
To achieve that, we write G=[g 1,⋯,g M ] with g k the kth column vector of G related to the kth nuisance parameter u k (1≤k≤M). Thus, our original model in (1) can be rewritten as
We then eliminate the nuisance parameters recursively in the order of u 1,⋯,u M , although the explicit ordering is not important. At the kth iteration, when k−1 nuisance parameters have already been canceled, the observation vector containing the remaining nuisance parameters can be written as
where the superscript (·)(k−1) indicates the variables after k−1 differencing steps, \(\mathbf {y}^{(k-1)}, \mathbf {g}_{k}^{(k-1)}, \cdots,\mathbf {g}_{M}^{(k-1)},\mathbf {n}^{(k-1)} \in \mathbb {R}^{(N-k+1) \times 1}\) and \(\mathbf {H}^{(k-1)} \in \mathbb {R}^{(N-k+1) \times L}\). We also assume that, for k=1,d (0)=y and similarly \(\mathbf {H}^{(0)}=\mathbf {H}, \mathbf {g}_{k}^{(0)}=\mathbf {g}_{k}\), and n (0)=n.
To cancel u k , we first notice that some elements of \(\mathbf {g}_{k}^{(k-1)}\) might be zero, i.e, u k yields no impact on the corresponding observations in d (k−1) and hence these observations should not be involved in the differencing process at this iteration. Without loss of generality, we assume that the first K elements of \(\mathbf {g}_{k}^{(k-1)}\) are zero, where 1≤K≤N−k−1 (there should be at least two non-zero elements for executing the differencing process). Then, among the remaining observations impacted by u k , we select the jth element as the reference, K+1≤j≤N−k+1, and perform the following differencing step
where \(\boldsymbol {\Gamma }^{(k)}\triangleq \left [\begin {array}{lc} \mathbf {I}_{K} &\mathbf {0}\\ \mathbf {0}&\boldsymbol {\Gamma }_{\perp }^{(k)}\text {diag}\left (\left [ {1 \over [\mathbf {g}_{k}^{(k-1)} ]_{K+1}}, \cdots,\ {1 \over [\mathbf {g}_{k}^{(k-1)} ]_{N-k-1}} \right ]^{T}\right)\\ \end {array}\right ]\) is the (N−k)×(N−k+1) differencing operator for d (k−1) with
and obviously \(\boldsymbol {\Gamma }^{(k)} \mathbf {g}_{k}^{(k-1)}=\mathbf {0}\). Accordingly, the new differential observation vector d (k) can be formulated as
where u k has been canceled.
We can see that (18) is similar to (15) with k−1 replaced by k. So it is clear that this recursive process can remove all nuisance parameters. Note that the number of zero values K as well as the reference index j could be different in every step, but for simplicity, we use the same notation in every step.
To understand the interaction of the successive differencing steps, let us introduce the total differencing operator Γ=Γ (M)⋯Γ (1), where obviously rank(Γ (k) Γ (k−1))=rank(Γ (k))=N−k and hence Γ has full row rank. Since it is clear that Γ G=0, the final differential observation vector d (M) can be expressed as
where the covariance matrix of Γ n is Σ Γ n =σ 2 Γ Γ T.
Observe that the model noise has become correlated ever since the first step of the differencing process. Therefore, we need to whiten the model in (19) as
where the unknown σ 2 is canceled out at both sides of the equation and \(\mathbf {P}\triangleq (\boldsymbol \Gamma \boldsymbol \Gamma ^{T})^{-1/2} \boldsymbol \Gamma \) which exists since Γ has full row rank. Note that P, as well as Γ and d (k), depend on the reference indices j that have been chosen in the successive differencing steps, although this has not been explicitly stated.
Applying the LS criterion, the corresponding optimization problem is now obtained as
which leads to the following BLUE for model (19)
Finally, to prove the equivalence of the estimate \(\hat {\mathbf {x}}_{\text {d}}\) to the previous estimates, i.e., to prove that
we need to establish the relation \(\mathbf {P}^{T}\mathbf {P}=\mathbf {U}_{n} \mathbf {U}_{n}^{T}=\mathbf {P}_{\mathbf {G}}^{\perp }\). To do that, we first recall that Γ G=0 and that Γ has full row rank. Hence, Γ can always be written as \(\boldsymbol \Gamma =\mathbf {Q}\mathbf {U}_{n}^{T}\), where Q is an (N−M)×(N−M) invertible matrix and U n has already been defined before as a basis that spans the null space of G. The proof is completed by computing
where we surprisingly notice that, even though P and Γ are subject to possibly different reference indices j, there is no trace of any j in P T P and hence in \(\hat {\mathbf {x}}_{\text {d}}\).
A Simple Illustrative Case: We would like to demonstrate these three different methods, particularly the differential signal processing, with a simple example. Given N=3 samples, we only assume a single parameter of interest (L=1), but with two linear nuisance parameters (M=2). We also know that \(\mathbf {H}=\left [\begin {array}{lll} 3&6&7 \end {array}\right ]^{T}\) and \(\mathbf {G}=\left [\begin {array}{lll} 3&5&2\\ 2&4&8\\ \end {array}\right ]^{T}\) and hence the joint estimator in (2) results into \(\left [\begin {array}{l} \hat {x}_{\text {jls}}\\ \hat {\mathbf {u}}_{\text {jls}} \end {array}\right ] =\left [\begin {array}{lll} -3.2&2&-0.2\\ 2&-1&0\\ 2.3& -1.5&0.3 \end {array}\right ]\mathbf {y},\) where the parameter estimate of interest is given by \(\hat {x}_{\text {jls}}=\left [\!\begin {array}{lll} -3.2&2&-0.2 \end {array}\right ] \mathbf {y}.\) Then, we calculate \(\mathbf {P}_{\mathbf {G}}^{\perp }=\left [\begin {array}{lll} 0.7171 & -0.4482& 0.0448\\ -0.4482 & 0.2801& -0.0280\\ 0.0448 & -0.0280& 0.0028 \end {array}\right ]\) and \(\mathbf {U}_{n}=\left [\begin {array}{lll} -0.8468&0.5293&-0.0529 \end {array}\right ]^{T}\) such that two OSP-based estimators in (6) and (9) can easily be carried out and proved to be equal to \(\hat {x}_{\text {jls}}\). We will not present more details for simplicity but particularly focus on the differential method. Since there exist two linear nuisance parameters, it would take two steps for eliminating all of them:
-
1.
In the first step (k=1), we arbitrarily select the third element of y as the reference (j=3). Splitting G by columns, we have \(\mathbf {g}_{1}^{(0)}=[3~~5~~2]^{T} \mathbf {g}_{2}^{(0)}=[2~~4~~8]^{T}.\) According to (16), the new differential observation vector can be obtained as d (1)=[y 1/3−y 3/2 y 2/5−y 3/2]T=Γ (1) y, where \(\boldsymbol \Gamma ^{(1)}=\left [\begin {array}{ccc} 1/3&0&-1/2\\ 0& 1/5&-1/2\\ \end {array}\right ].\) We can observe from \(\boldsymbol \Gamma ^{(1)} \mathbf {G}=\left [\begin {array}{cc} 0&-10/3\\ 0& -16/5\\ \end {array}\right ]\) that the impact of the first nuisance parameter u 1 is already eliminated. Also, \(\mathbf {g}_{2}^{(1)}=\boldsymbol \Gamma ^{(1)}\mathbf {g}_{2}^{(0)}\) corresponds to the last column and the next nuisance parameter u 2.
-
2.
In the second step (k=2), the first element of d (1) is selected as the reference (j=1). The differential observation becomes a scalar as \(\mathbf {d}^{(2)}= -{5 \over 16}(y_{2}/5-y_{3}/2)+ {3 \over 10} (y_{1}/3-y_{3}/2) =\boldsymbol \Gamma ^{(2)}\mathbf {d}^{(1)}=\boldsymbol \Gamma \mathbf {y}\), where Γ (2)=[3/10 −5/16] and Γ=Γ (2) Γ (1)=[1/10 −1/16 1/160]. Now, we can readily observe that all the nuisance parameters are eliminated, since Γ G=0.
With a known Γ, we can easily whiten the model in (19) and obtain the differential estimator in (22). Moreover, the equivalence of the differential estimation can also be proved by observing \(\mathbf {P}^{T}\mathbf {P}=\boldsymbol \Gamma ^{T} (\boldsymbol \Gamma \boldsymbol \Gamma ^{T})^{-1} \boldsymbol \Gamma =\mathbf {P}_{\mathbf {G}}^{\perp }.\)
2.4 Discussion
We have studied estimation problems in the presence of deterministic linear nuisance parameters based on a general model. Therefore, all the conclusions drawn in this paper are applicable to any optimization problem with a data model that matches our general model (1). The equivalences between the BLUEs of the joint estimation, the OSP-based estimation and the differential estimation are summarized in Table 1 and also in Fig. 1. Some interesting observations from these equivalences are listed below:
-
1.
The joint estimation has to estimate both x and the nuisance term u while the other two estimation approaches remove the impact of u before estimating x.
Fig. 1 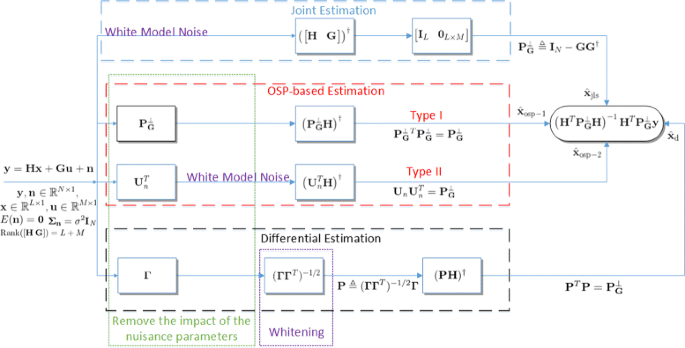
Diagram to illustrate the relations between the BLUEs related to the joint estimation, the OSP-based estimation, and the differential estimation. Note that the noise n is not necessarily Gaussian distributed and the operator [I L 0 L×M ] is used to extract the first L elements of a vector, i.e., \(\hat {\mathbf {x}}_{\text {jls}}\)
Table 1 Relations between the BLUEs related to the joint estimation, the OSP-based estimation, and the differential estimation -
2.
For the OSP-based estimation, in order to remove the impact of u, using \(\mathbf {P}_{\mathbf {G}}^{\perp }\) actually colors the noise, but using \(\mathbf {U}_{n}^{T}\) keeps the model noise white. Interestingly though, the corresponding LS estimates for those two models are theoretically equivalent and hence they are both the BLUE.
-
3.
In many applications, the differential processing is commonly considered as a separate and independent approach. But, in this paper, we have generally proven its equivalence to the joint estimation and the OSP-based estimation. The differential approach removes the impact of the nuisance parameters by taking differences between the reference and the observations. If one of the observations is selected as a reference, the obtained differential observation set has to be properly whitened in order to obtain the BLUE for this model.
-
4.
From an information theoretic perspective, the joint estimation, which directly utilizes the observations y, preserves the full data information, and any preprocessing on the observations might cause an information loss. However, in this paper, all the other BLUEs have been proven to be equivalent to the BLUE of the joint estimation, which implies that neither the OSP-based estimation nor the differential estimation suffers any information loss by removing the impact of the nuisance parameters.
-
5.
It is also worth noting that, for the differential approach, selecting which observation will function as a reference is not important, since the reference index j yields no impact on the BLUE. This is in sharp contrast to what is commonly considered in literature.
-
6.
One might notice that, in the differencing process, N observations can generate a maximum of N(N−1)/2 distinct observation differences. In contrast, we only study the estimation problem based on a subset, which is associated with a single reference and corresponds to N−1 observation differences. However, from the above conclusions, it is clear that the considered subset already preserves all the information (independent of the reference), which implies that the full set obtains no more information than any subset does. Also this is a novel observation.

3 Localization examples
By studying the relations between the BLUE of the joint estimation, the OSP-based estimation, and the differential estimation, the essence of this paper is to provide some in-depth understanding of coping with unknown nuisance parameters. Some important underlying equivalences have been unveiled, especially the one related to the differential method, since, in many applications, this approach is still considered as a separate optimization problem. Owing to the generality of this paper, one may easily apply our analyses and conclusions to some particular applications, if the data model can be (re)formulated to match our general model (1). Some specific localization examples are detailed next.
3.1 Time-based localization
Both TOA- and TDOA-based localization are called time-based localization [2], since they both rely on time measurements (either the global time or the local time). The essence of this kind of localization problem is how to accurately extract distance-related information (e.g., the time of flight (TOF)). Directly using TOA measurements requires not only perfect clock synchronization between the emitters and the receivers but also the knowledge of the transmitting time [33]. In cooperative networks, where clock synchronization is frequently carried out (because the inner clock might drift over time) and the transmitting times are also piggybacked with the transmitted signals, one can precisely calculate the TOFs from the TOA measurements and then localize the target node. However, it is often very expensive to meet those requirements, and most networks are constrained by limited resources and capabilities. Therefore, in most cases, sensors suffer from two linear nuisance parameters, i.e., the unknown clock biases to the global time and the unknown transmitting times.
In this example, we assume N anchor nodes that are perfectly synchronized with the global time and there exists only a clock bias in the target node, which broadcasts beacon signals at unknown local transmit times. We denote \(\mathbf {x}_{t}\in \mathbb {R}^{d}\) as the target location and \(\mathbf {s}_{i}\in \mathbb {R}^{d}\) as the ith anchor location. For convenience, a single unknown global transmit time t 0 is considered for the target node, instead of the local transmit time plus the clock bias. Taking the speed of light c into account, we obtain the TOA measurements as
where the element d i of d indicates the TOA measurement from the ith anchor, r(x t ) stacks \(r_{i} \triangleq ||\mathbf {x}_{t}-\mathbf {s}_{i}||_{2}, r_{o} \triangleq c t_{0}\) and n is the vector of the measurement noise n i with \(\mathbf {n} \sim \mathcal {N}(\mathbf {0},\sigma ^{2}\mathbf {I}_{N})\). Note that, compared with more realistic scenarios, the model (24) is simplified for convenience but still adequate to make our point.
3.1.1 Taylor series expansion
Obviously, the non-linearity of (24) is a very serious issue for localization, other than the nuisance parameter. Many methods, especially those considering mobile scenarios, directly linearize (24) by a Taylor series expansion (TSE) [34]. Note that this kind of method is very similar to the Gauss-Newton (GN) method [35] and holds the maximum likelihood (ML) property. Since we can obtain the estimate of x t by iteratively updating the previous iteration, we first have to apply the TSE to (24) around the target location estimate \(\hat {\mathbf {x}}_{t}^{(k-1)}\) at the (k−1)th iteration, thus resulting into
Then, we rearrange the above equation and present the TSE model for iteration step k as
where \(\boldsymbol {\delta }^{(k-1)} \triangleq \mathbf {d}-\mathbf {r}(\hat {\mathbf {x}}_{t}^{(k-1)})+\boldsymbol \Delta ^{(k-1)}\hat {\mathbf {x}}_{t}^{(k-1)}\) and
The localization problem at the kth iteration boils down to estimating x t from (25) to update the location estimate from the (k−1)th iteration. The relation between the TSE model and the general model (1) is presented in Table 2. Note that since the discussed approaches can directly be applied to the TOA measurements with a single nuisance parameter (M=1), the differential approach applied to the TOA measurements actually corresponds to working with the TDOA measurements, i.e.,
However, to avoid any confusion with the TDOA methods we will discuss later on, we will refer to this method as the differential approach applied to the TSE model of the TOA measurements.
3.1.2 Squared distance
The TSE method highly relies on an appropriate initialization that is near the global solution; otherwise, it might converge to a local minimum. Thus, some closed-form solutions were proposed to solve this non-convex problem, which requires squaring the distance norm (SD) for linearization [36]. Unlike the TSE method, the SD method depends on the type of measurements, since different modeling steps are carried out for TOA and TDOA measurements.
3.1.2.1 TOA:
Let us first focus on the SD method based on the TOA measurements which can be expressed as
Moving r 0 to the other side and squaring both sides of the equation, we obtain
where \({r_{0}^{2}}\) is viewed as a new nuisance parameter. As a result, a linear model with two nuisance parameters (M=2) can be formulated as
where \(\mathbf {A}_{1}\triangleq \left [\!\begin {array}{lll} \vdots & \vdots & ~~~~\vdots \\ -2\mathbf {s}_{i}^{T} &1 &-2d_{i} \\ \vdots & \vdots & ~~~~\vdots \\ \end {array}\!\right ], \boldsymbol {\theta }_{1} \triangleq \left [\vphantom {\dot {\begin {array}{lll} \vdots & \vdots & \vdots \\ -2\mathbf {s}_{i}^{T} &1 &-2d_{i} \\ \vdots & \vdots & \vdots \\ \end {array}}\!}\!\begin {array}{l} \mathbf {x}_{t} \\ ||\mathbf {x}_{t}||_{2}^{2}-{r_{0}^{2}}\\ r_{0} \end {array}\!\right ], \mathbf {z}_{1}\triangleq \left [\begin {array}{l} ~~~~~~~~~~\vdots \\ {d_{i}^{2}}-||\mathbf {s}_{i}||_{2}^{2} \\ ~~~~~~~~~~\vdots \\ \end {array}\right ]\) and
Here, we denote D 1= diag([r 1,⋯,r N ]T) with diag(·) as a diagonal matrix with its argument on the diagonal, and hence \(\boldsymbol \Sigma _{\boldsymbol \epsilon _{1}}=4\sigma ^{2}\mathbf {D}_{1}^{2}\). This SD-TOA model is widely considered [37–41]. Some researchers apply the differencing process to remove the nuisance parameters [24, 33, 42–45] while some others use the OSP method [16, 46]. Note that the model noise in (30a) is still not white, and hence, an appropriate whitening procedure is required. Assuming D 1 is perfectly known, we can whiten the model (29) as
where \(\mathbf {D}_{1}' \triangleq \mathbf {D}_{1}^{-1}\) and the covariance matrix of D1′ε 1 is now a scaled identity, i.e., \(\phantom {\dot {i}\!}\boldsymbol \Sigma _{\mathbf {D}_{1}'\boldsymbol \epsilon _{1}}=4\sigma ^{2}\mathbf {I}_{N}\). In practice, a LS estimate based on the model (29) can first be used to construct an estimate of D 1 for carrying out the whitening. Then, the estimate of D 1 can be repeatedly updated to approach the true D 1 with a more accurate location estimate. In this paper though, we only want to evaluate its best performance and hence directly use the true D 1. Finally, expressing A 1=[A1′,A1″] with A1′ and A1″, respectively, containing the first d and the remaining columns, the relation between the whitened SD-TOA model and the general model (1) is presented in Table 2.
3.1.2.2 TDOA:
Directly applying the differencing process on the TOA observations d removes the unknown nuisance parameter r 0, resulting in the TDOA measurements
where n i,j =n i −n j . Introducing r j =||x t −s j ||2 as a new unknown parameter, we can linearize (32) using the following squaring operation
As a result, a linear model with a single unknown nuisance parameter r j (M=1) can be formulated as
where \(\mathbf {A}_{2}\triangleq -2\left [ \begin {array}{cc} \vdots & \vdots \\ (\mathbf {s}_{i}-\mathbf {s}_{j})^{T}&d_{i,j} \\ \vdots & \vdots \\ \end {array}\right ], \boldsymbol {\theta }_{2} \triangleq \left [ \begin {array}{c} \mathbf {x}_{t} \\ r_{j} \end {array}\right ], \mathbf {z}_{2}\triangleq \left [ \begin {array}{c} \vdots \\ d_{i,j}^{2}+||\mathbf {s}_{j}||_{2}^{2}-||\mathbf {s}_{i}||_{2}^{2} \\ \vdots \\ \end {array}\right ]\), and
Here, we denote D 2=diag([⋯,r i ,⋯ ]T),i≠j, and hence, \(\boldsymbol \Sigma _{\boldsymbol \epsilon _{2}}=4\sigma ^{2}\mathbf {D}_{2} \boldsymbol {\Gamma }_{j} \boldsymbol {\Gamma }_{j}^{T}\mathbf {D}_{2}^{T}\). Also, this SD-TDOA model has been commonly adopted in literature [14, 33, 47–51]. Among the TDOA localization techniques based on this model, the famous Chan algorithm [14], from which many others stem, is actually equivalent to some earlier works [52–54], where the unknown r j is simply removed by the OSP method. Again, note that the model noise (35a) is not white. Assuming D 2 is perfectly known (as already explained for D 1, in practice, D 2 should be iteratively estimated), we can whiten the model (34) as
where \(\mathbf {D}_{2}'\triangleq (\mathbf {D}_{2} \boldsymbol {\Gamma }_{j} \boldsymbol {\Gamma }_{j}^{T}\mathbf {D}_{2}^{T})^{-1/2}\) and the covariance matrix of D2′ε 2 is now a scaled identity, i.e., \(\phantom {\dot {i}\!}\boldsymbol \Sigma _{\mathbf {D}_{2}' \boldsymbol \epsilon _{2}}=4\sigma ^{2}\mathbf {I}_{N-1}\). Finally, we split A 2 into A 2=[A2′,A2″] with A2′ and A2″, respectively, containing the first d and the remaining columns. The relation between the whitened SD-TDOA model and the general model (1) is finally presented in Table 2.
3.1.2.3 Numerical results:
We have conducted a Monte Carlo simulation with 1000 trials to verify our conclusions, where the BLUEs of the joint estimation, the OSP-based estimation, and the differential estimation are carried out for each one of the discussed time-based models. Some LS estimators without a proper whitening process are also presented for comparison. The acronyms of all estimators used in the simulations are summarized in Table 3. We also calculate the Cramér-Rao lower bound (CRLB) with an unknown r 0 based on the original model (24) [1, Chapter 3], since the TSE, SD-TOA, and SD-TDOA models all lose some information by ignoring some high-order terms. The root mean square error (RMSE) of the location estimate, which is defined as \(\sqrt {E[(\hat {\mathbf {x}}-\mathbf {x})^{2}]}\) in general, is used as a performance measure in this paper. From the numerical results in Fig. 2, we can draw the following conclusions.
-
1.
For each model, the corresponding BLUEs yield the same performance as expected.
Fig. 2 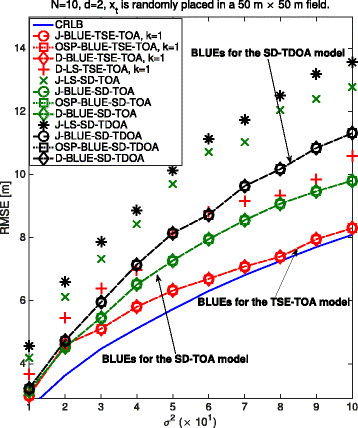
Performance of different time-based estimators: the target node is randomly placed in a 50×50 field and 10 anchors are deployed with coordinates (50,50),(50,0),(0,50),(0,0),(25,7),(25,43),(12,33),(12,16),(37,33), and (37,16)
Table 3 Acronyms of the estimators used in the localization simulations -
2.
Without a proper whitening, it can be observed that the performance of the LS estimators deteriorates. The D-LS-TSE-TOA, J-LS-SD-TOA, and J-LS-SD-TDOA clearly perform worse than their corresponding BLUEs.
-
3.
The TSE model ignores \(\mathcal {O}((\mathbf {x}_{t}-\hat {\mathbf {x}}_{t}^{(k-1)})^{2})\) and accordingly suffers some information loss in modeling. However, the information loss can be reduced with a more accurate \(\hat {\mathbf {x}}_{t}^{(k-1)}\). Therefore, with more iterations, the BLUEs for the TSE model approach the CRLB, which is in fact the essence of the ML property.
-
4.
The SD-TOA model ignores \({n_{i}^{2}}, \forall i\) while the SD-TDOA model ignores \(n_{i,j}^{2}, \forall i, i \neq j\). Ignoring these terms will cause an increasing information loss as the measurement noise gets larger.
-
5.
Even though the BLUEs of the SD-TOA model outperform those of the SD-TDOA model in our simulation, we still cannot decide at this point which model is the best. This is because an optimal localization problem for the SD models should also include any dependence between the (nuisance) parameters, e.g., between x t and \(||\mathbf {x}_{t}||_{2}^{2}\), between r 0 and \({r_{0}^{2}}\) in θ 1, or between x t and r j in θ 2, which explains the huge gap between the CRLB and the BLUEs for the SD models. By contrast, the TSE model obviously does not have this kind of issue. Nevertheless, including these dependencies is beyond the scope of this paper and we will not further consider this.
-
6.
In practice, both the TSE and SD methods require iterations to obtain an accurate location estimate. However, note that, even after serveral iterations, the estimators based on the SD models still need to cope with the abovementioned dependency issue. Therefore, in real life, one often combines those two models, i.e., one uses the TSE model with the J-LS-SD-TDOA or the J-LS-SD-TOA as an initialization.
-
7.
For the SD-TDOA model, ignoring the terms \(n_{i,j}^{2}, \forall i, i \neq j\) implies that the information loss depends on the reference choice of the differencing process in (32). However, this is only because of the SD modeling thereafter, not because of the differencing process itself. Note that, for any other differencing process in this paper, the reference index is not important as long as the model is properly whitened.

3.2 Received signal strength based localization
Due to the simplicity of utilizing received signal strength (RSS) measurements, wireless networks with very constrained resources preferably rely on RSS-based localization [2]. Therefore, it gradually became very popular in recent years, and many efforts have already been put on this topic [55–58].
RSS-based localization mainly suffers from the complicated radio propagation channel. As before, assume that the target node is located at x t and the ith anchor at s i . Based on a large-scale log-normal fading model [59], the RSS measurement can then be modeled as
where P 0 is the received power at the reference distance d 0,γ is the path-loss exponent (PLE), \(n_{i} \sim \mathcal {N}(0,\sigma ^{2})\) is the shadowing effect, and N is the number of anchor nodes. RSS-based localization is aimed at estimating the target location x t from the RSS measurements. However, in some military or hostile scenarios, the transmit power might be unknown. Therefore, without loss of generality, we assume the reference distance d 0 to be 1 m and then the problem of the unknown transmit power can be equivalently converted into that of an unknown P 0. Note that (37) also has the non-linearity issue and, obviously, the iterative TSE model for RSS-based localization will be very similar to that developed for time-based localization. Therefore, to save space, we do not consider directly applying the TSE model but only focus on the SD method here.
To construct a linear data model, we rewrite (37) as
where \(P_{i}' \triangleq 10^{\frac {P_{i}}{5\gamma }}, P_{0}' \triangleq 10^{\frac {P_{0}}{5\gamma }}\) and \(n_{i}' \triangleq 10^{\frac {n_{i}}{5\gamma }}\). Interestingly though, we still need to apply the TSE to n i ′ here2, such that (38) can further be approximated as
Then, a linear SD-RSS model for localization can be formulated from (39) as
where
This model was firstly presented in [57, eq. (18)] but in the absence of the shadowing effect. If we whiten the model (40) utilizing the covariance matrix of ς, i.e.,
where D=diag([P1′, ⋯, P N ′]T), we can obtain
where the covariance matrix of D ς becomes a scaled identity matrix, i.e., \(\boldsymbol \Sigma _{\mathbf {D} \boldsymbol \varsigma }={ln(10)^{2} P_{0}^{\prime {2}} \sigma ^{2} \over 25 \gamma ^{2}} \mathbf {I}_{N}\). Note that this whitening step simply corresponds to an appropriate scaling of every entry of (40).
The whitened model (43b) is found to match our general model (1), since we notice that D F can be split into
where F ′ contains the first d+1 columns of D F. The relation between this model and the general model (1) is presented in Table 2. Note that we only consider a single nuisance parameter P0′ in this model (M=1). Although we could consider both \(||\mathbf {x}_{t}||_{2}^{2}\) and P0′ as nuisance parameters (M=2), which would lead to the same performance after using the correct preprocessing steps, the reason why we take M=1 here is to connect this model to the existing literature. For instance, after removing P0′ using a single differencing step, the model for Γ j D h is equal to the SD-DRSS model used in [57, eq. (22)]. However, without an appropriate whitening procedure, the LS estimators of the SD-RSS and SD-DRSS models yield a different performance, which is why they were treated and studied separately. Now, we realize that they actually are identical to each other as long as the model noise is properly whitened.
Numerical results: A simulation has also been conducted to verify our conclusions for this example. As before, the BLUEs of the joint estimation, OSP-based estimation, and the differential estimation for the SD-RSS model are evaluated and compared with some LS estimators without a proper whitening. Based on the original model in (37), the CRLB with an unknown P 0 is easy to calculate [1, Chapter 3]. From the numerical results in Fig. 3, the critical observation is that all the BLUEs here yield exactly the same performance as expected. Due to the colored model noise, the J-LS-SD-RSS and the D-LS-SD-RSS are relatively worse. Finally, denoting \(R \triangleq ||\mathbf {x}_{t}||_{2}^{2}\), we again point out that neglecting the dependence between R and x t results in the gap between the CRLB and the estimators presented here.

Performance of different RSS-based estimators: the target node is randomly placed in a 50×50 field and 10 anchors are deployed with coordinates of (50,50),(50,0),(0,50),(0,0),(25,7),(25,43),(12,33),(12,16),(37,33), and (37,16). The transmit power is set to 10 dBm and the PLE is set to 2
3.3 Other examples
We believe that there are many other examples with linear nuisance parameters for our results. However, due to the limited space, we will only point out some of them. Besides the aforementioned localization examples, if anchors are separated into groups with different central clocks, multiple relative clock biases might exist in the TDOA measurements for localization, which can be removed by the OSP method [60, eq. (3)]. In cooperative localization, the multidimentional scaling (MDS) also uses the OSP-based method to eliminate the unknown terms [61, eq. (3)]. An acoustic source localization model, which also matches our general model (1), was presented in [62, eq. (6)]. In [4, eq. (2)], the transmission times and clock offsets are the unknown nuisance parameters for the considered clock synchronization problem. The authors claim that those unknown parameters are systematically ML estimated before the synchronization. However, in fact, those nuisance parameters are equivalently removed by using respectively the observations d avg in (13) or the OSP procedure. In hyperspectral imaging, OSP is also a very common procedure to extract the desired signals [19]. And when tracking mobile targets, frequency-difference-of-arrival measurements are often measured to cope with the Doppler effect [17, 18, 63, 64]. Furthermore, multiple-input-multiple-output (MIMO) receiver design might be affected by some nuisance parameters like I-Q imbalance and DC offset [5, eq. (7)]. In machine learning, a well-designed OSP is desired for dimensionality reduction [8, 9]. Extracting and working on the signal space is a strong need for signal separation [7] and underwater communication [6], which can be facilitated by OSP. At last, the famous differential global positioning system (DGPS) introduces a reference station on the ground and constructs a new differential observation set for positioning [65], where even the double differencing process is considered [66–68].
4 Conclusions
In this paper, we have introduced a general framework for estimation in the presence of unknown linear nuisance parameters. Three different kinds of methods to cope with the unknown nuisance parameters have been studied, i.e., the joint estimation, the OSP-based estimation, and the differential estimation. These approaches have been analyzed by investigating their corresponding BLUEs, where a new differential method has been introduced to cope with multiple nuisance parameters. We have discovered that, after a proper whitening procedure, all the BLUEs are equivalent to each other. From this interesting fact, one can draw some useful conclusions:
-
1.
There only exists one unique BLUE for all these methods proposed to cope with unknown nuisance parameters.
-
2.
Compared with the joint estimation, which directly utilizes all the original observations, none of the other two methods suffers any information loss.
-
3.
For the differential approach, which requires selecting some references, the choice of the references is not important since there is no actual trace of the selected references in the corresponding BLUE.
-
4.
In the differencing process, compared with the full differential observation set, any subset related to a single reference already preserves the full data information.
The presented analyses of the general model can be projected onto many practical applications, e.g., hyperspectral imaging, source localization and synchronization. Some localization examples have also been demonstrated, simulated and discussed to verify our conclusions.
5 Endnotes
References
SM Kay, Fundamentals of Statistical Signal Processing: Estimation Theory (Prentice-Hall, Inc., Upper Saddle River, NJ, USA, 1993).
N Patwari, JN Ash, S Kyperountas, AO Hero, RL Moses, NS Correal, Locating the nodes: cooperative localization in wireless sensor networks. IEEE Signal Proc. Mag. 22(4), 54–69 (2005). doi:10.1109/MSP.2005.1458287.
S Lopez, T Vladimirova, C Gonzalez, J Resano, D Mozos, A Plaza, The Promise of Reconfigurable Computing for Hyperspectral Imaging Onboard Systems: a Review and Trends. Proc. IEEE. 101(3), 698–722 (2013). doi:10.1109/JPROC.2012.2231391.
O Jean, AJ Weiss, Passive Localization and Synchronization Using Arbitrary Signals. IEEE Trans. Signal Process. 62(8), 2143–2150 (2014). doi:10.1109/TSP.2014.2307281.
CJ Hsu, R Cheng, WH Sheen, Joint least squares estimation of frequency, DC offset, I-Q imbalance, and channel in MIMO receivers. IEEE Trans. Veh. Technol. 58(5), 2201–2213 (2009). doi:10.1109/TVT.2008.2005989.
J He, MNS Swamy, MO Ahmad, Joint space-time parameter estimation for underwater communication channels with velocity vector sensor arrays. IEEE Trans. Wirel. Commun. 11(11), 3869–3877 (2012). doi:10.1109/TWC.2012.092112.110875.
MA Uusitalo, RJ Ilmoniemi, Signal-space projection method for separating MEG or EEG into components. Med. Biol. Eng. Comput. 35(2), 135–140 (1997).
E Kokiopoulou, Y Saad, Orthogonal neighborhood preserving projections: a projection-based dimensionality reduction technique. IEEE Trans. Pattern Anal. Mach. Intell. 29(12), 2143–2156 (2007). doi:10.1109/TPAMI.2007.1131.
CX Ren, DQ Dai, in Pattern Recognition, 2008. CCPR ’08. Chinese Conference On. 2d-onpp: Two dimensional extension of orthogonal neighborhood preserving projections for face recognition (IEEEBeijing, 2008), pp. 1–6. doi:10.1109/CCPR.2008.48.
S Bar, J Tabrikian, Bayesian estimation in the presence of deterministic nuisance parameters-part i: performance bounds. IEEE Trans. Signal Process. 63(24), 6632–6646 (2015). doi:10.1109/TSP.2015.2468684.
S Bar, J Tabrikian, Bayesian estimation in the presence of deterministic nuisance parameters-part ii: estimation methods. IEEE Trans. Signal Process. 63(24), 6647–6658 (2015). doi:10.1109/TSP.2015.2468680.
S Zhu, Z Ding, Joint synchronization and localization using TOAs: a linearization based WLS solution. IEEE J. Sel. Areas Commun. 28(7), 1017–1025 (2010). doi:10.1109/JSAC.2010.100906.
T-M Tu, C-H Chen, C-I Chang, A posteriori least squares orthogonal subspace projection approach to desired signature extraction and detection. IEEE Trans. Geosci. Remote Sens. 35(1), 127–139 (1997). doi:10.1109/36.551941.
YT Chan, KC Ho, A simple and efficient estimator for hyperbolic location. IEEE Trans. Signal Process. 42(8), 1905–1915 (1994). doi:10.1109/78.301830.
KC Ho, Bias Reduction for an Explicit Solution of Source Localization Using TDOA. IEEE Trans. Signal Process. 60(5), 2101–2114 (2012). doi:10.1109/TSP.2012.2187283.
Y Wang, G Leus, Reference-free time-based localization for an asynchronous target. EURASIP J. Adv. Signal Process. 2012(1), 19 (2012). doi:10.1186/1687-6180-2012-19.
KC Ho, X Lu, L Kovavisaruch, Source Localization Using TDOA and FDOA Measurements in the Presence of Receiver Location Errors: Analysis and Solution. IEEE Trans. Signal Process. 55(2), 684–696 (2007). doi:10.1109/TSP.2006.885744.
D Musicki, W Koch, in Information Fusion, 2008 11th International Conference On. Geolocation using TDOA and FDOA measurements (IEEECologne, 2008), pp. 1–8.
JC Harsanyi, C-I Chang, Hyperspectral image classification and dimensionality reduction: an orthogonal subspace projection approach. IEEE Trans. Geosci. Remote Sens. 32(4), 779–785 (1994). doi:10.1109/36.298007.
C-I Chang, Orthogonal subspace projection (OSP) revisited: a comprehensive study and analysis. IEEE Trans. Geosci. Remote Sens. 43(3), 502–518 (2005). doi:10.1109/TGRS.2004.839543.
M Song, CI Chang, A Theory of Recursive Orthogonal Subspace Projection for Hyperspectral Imaging. IEEE Trans. Geosci. Remote Sens. 53(6), 3055–3072 (2015). doi:10.1109/TGRS.2014.2367816.
Q Xu, Y Lei, J Cao, H Wei, in Image and Signal Processing (CISP), 2014 7th International Congress On. An improved algorithm based on reference selection for time difference of arrival location (IEEEDalian, 2014), pp. 953–957. doi:10.1109/CISP.2014.7003916.
Y Wang, F Zheng, M Wiemeler, W Xiong, T Kaiser, in Vehicular Technology Conference (VTC Fall), 2013 IEEE 78th. Reference Selection for Hybrid TOA/RSS Linear Least Squares Localization (IEEELas Vegas, 2013), pp. 1–5. doi:10.1109/VTCFall.2013.6692388.
I Guvenc, S Gezici, F Watanabe, H Inamura, in 2008 IEEE Wireless Communications and Networking Conference. Enhancements to Linear Least Squares Localization Through Reference Selection and ML Estimation (IEEELas Vegas, 2008), pp. 284–289. doi:10.1109/WCNC.2008.55.
HC So, YT Chan, FKW Chan, Closed-Form Formulae for Time-Difference-of-Arrival Estimation. IEEE Trans. Signal Process. 56(6), 2614–2620 (2008). doi:10.1109/TSP.2007.914342.
SCK Herath, PN Pathirana, Robust Localization With Minimum Number of TDoA Measurements. IEEE Signal. Proc. Let. 20(10), 949–951 (2013). doi:10.1109/LSP.2013.2274273.
Y Huang, J Benesty, GW Elko, RM Mersereati, Real-time passive source localization: a practical linear-correction least-squares approach. IEEE T. Speech. Audi. P. 9(8), 943–956 (2001). doi:10.1109/89.966097.
RO Schmidt, A New Approach to Geometry of Range Difference Location. IEEE Trans. Aerosp. Electron. Syst. AES-8(6), 821–835 (1972). doi:10.1109/TAES.1972.309614.
R Schmidt, Least squares range difference location. IEEE Trans. Aerosp. Electron. Syst. 32(1), 234–242 (1996). doi:10.1109/7.481265.
S Venkatesh, RM Buehrer, in Proceedings of the 5th International Conference on Information Processing in Sensor Networks. IPSN ’06. A Linear Programming Approach to NLOS Error Mitigation in Sensor Networks (ACMNew York, NY, USA, 2006), pp. 301–308. doi:10.1145/1127777.1127823.
A-J van der Veen, EF Deprettere, AL Swindlehurst, Subspace-based signal analysis using singular value decomposition. Proc. IEEE. 81(9), 1277–1308 (1993). doi:10.1109/5.237536.
LL Scharf, ML McCloud, Blind adaptation of zero forcing projections and oblique pseudo-inverses for subspace detection and estimation when interference dominates noise. IEEE Trans. Signal Process. 50(12), 2938–2946 (2002). doi:10.1109/TSP.2002.805245.
AH Sayed, A Tarighat, N Khajehnouri, Network-based wireless location: challenges faced in developing techniques for accurate wireless location information. IEEE Signal Proc. Mag. 22(4), 24–40 (2005). doi:10.1109/MSP.2005.1458275.
WH Foy, Position-Location Solutions by Taylor-Series Estimation. IEEE Trans. Aerosp. Electron. Syst. AES-12(2), 187–194 (1976). doi:10.1109/TAES.1976.308294.
CT Kelley, Iterative Methods for Optimization. Front. Appl. Math. Soc. Ind. Appl. Math (1999). https://books.google.nl/books?id=Bq6VcmzOe1IC.
A Beck, P Stoica, J Li, Exact and Approximate Solutions of Source Localization Problems. IEEE Trans. Signal Process. 56(5), 1770–1778 (2008). doi:10.1109/TSP.2007.909342.
DB Haddad, WA Martins, MdVM da Costa, LWP Biscainho, LO Nunes, B Lee, Robust Acoustic Self-Localization of Mobile Devices. in IEEE Transactions on Mobile Computing. 15(4), 982–995 (2016). doi:10.1109/TMC.2015.2439278.
KW Cheung, HC So, WK Ma, YT Chan, Least squares algorithms for time-of-arrival-based mobile location. IEEE Trans. Signal Process. 52(4), 1121–1130 (2004). doi:10.1109/TSP.2004.823465.
JC Chen, RE Hudson, K Yao, Maximum-likelihood source localization and unknown sensor location estimation for wideband signals in the near-field. IEEE Trans. Signal Process. 50(8), 1843–1854 (2002). doi:10.1109/TSP.2002.800420.
C-H Park, S Lee, J-H Chang, Robust closed-form time-of-arrival source localization based on alpha-trimmed mean and HodgesCLehmann estimator under NLOS environments. Signal Process. 111:, 113–123 (2015). doi:10.1016/j.sigpro.2014.12.020.
M Sun, KC Ho, Successive and Asymptotically Efficient Localization of Sensor Nodes in Closed-Form. IEEE Trans. Signal Process. 57(11), 4522–4537 (2009). doi:10.1109/TSP.2009.2025821.
ND Gaubitch, WB Kleijn, R Heusdens, in 2013 IEEE International Conference on Acoustics, Speech and Signal Processing. Auto-localization in ad-hoc microphone arrays (IEEEVancouver, 2013), pp. 106–110. doi:10.1109/ICASSP.2013.6637618.
L Wang, TK Hon, JD Reiss, A Cavallaro, Self-Localization of Ad-Hoc Arrays Using Time Difference of Arrivals. IEEE Trans. Signal Process. 64(4), 1018–1033 (2016). doi:10.1109/TSP.2015.2498130.
K Liu, X Liu, X Li, Guoguo: Enabling Fine-Grained Smartphone Localization via Acoustic Anchors. IEEE Trans. Mob. Comput. 15(5), 1144–1156 (2016). doi:10.1109/TMC.2015.2451628.
JJ Caffery, in Vehicular Technology Conference, 2000. IEEE-VTS Fall VTC 2000. 52nd, 4. A new approach to the geometry of TOA location (IEEEBoston, 2000), pp. 1943–19494. doi:10.1109/VETECF.2000.886153.
Y Wang, G Leus, X Ma, in 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). Time-based localization for asynchronous wireless sensor networks (IEEEPrague, 2011), pp. 3284–3287. doi:10.1109/ICASSP.2011.5946723.
P Stoica, J Li, Lecture Notes - Source Localization from Range-Difference Measurements. IEEE Signal Process. Mag. 23(6), 63–66 (2006). doi:10.1109/SP-M.2006.248717.
Y Liu, F Guo, L Yang, W Jiang, An Improved Algebraic Solution for TDOA Localization With Sensor Position Errors. IEEE Commun. Lett. 19(12), 2218–2221 (2015). doi:10.1109/LCOMM.2015.2486769.
J Liu, Z Wang, JH Cui, S Zhou, B Yang, A Joint Time Synchronization and Localization Design for Mobile Underwater Sensor Networks. IEEE Trans. Mob. Comput. 15(3), 530–543 (2016). doi:10.1109/TMC.2015.2410777.
B Huang, L Xie, Z Yang, TDOA-Based Source Localization with Distance-Dependent Noises. IEEE Trans. Wirel. Commun. 14(1), 468–480 (2015). doi:10.1109/TWC.2014.2351798.
H Yang, J Chun, D Chae, Hyperbolic Localization in MIMO Radar Systems. IEEE Antennas Wirel. Propag. Lett. 14:, 618–621 (2015). doi:10.1109/LAWP.2014.2374603.
J Smith, J Abel, The spherical interpolation method of source localization. IEEE J. Oceanic. Eng. 12(1), 246–252 (1987). doi:10.1109/JOE.1987.1145217.
B Friedlander, A passive localization algorithm and its accuracy analysis. IEEE J. Oceanic. Eng. 12(1), 234–245 (1987). doi:10.1109/JOE.1987.1145216.
J Smith, J Abel, Closed-form least-squares source location estimation from range-difference measurements. IEEE Trans. Acoust. Speech Signal Process. 35(12), 1661–1669 (1987). doi:10.1109/TASSP.1987.1165089.
X Li, RSS-Based Location Estimation with Unknown Pathloss Model. IEEE Trans. Wirel. Commun. 5(12), 3626–3633 (2006). doi:10.1109/TWC.2006.256985.
HC So, L Lin, Linear Least Squares Approach for Accurate Received Signal Strength Based Source Localization. IEEE Trans. Signal Process. 59(8), 4035–4040 (2011). doi:10.1109/TSP.2011.2152400.
RM Vaghefi, MR Gholami, EG Strom, in Acoustics, Speech and Signal Processing (ICASSP), 2011 IEEE International Conference On. RSS-based sensor localization with unknown transmit power (IEEEPrague, 2011), pp. 2480–2483. doi:10.1109/ICASSP.2011.5946987.
MR Gholami, RM Vaghefi, EG Strom, RSS-Based Sensor Localization in the Presence of Unknown Channel Parameters. IEEE Trans. Signal Process. 61(15), 3752–3759 (2013). doi:10.1109/TSP.2013.2260330.
T Rappaport, Wireless Communications: Principles and Practice, 2nd edn. (Prentice Hall PTR, Upper Saddle River, NJ, USA, 2001).
Y Wang, KC Ho, TDOA Source Localization in the Presence of Synchronization Clock Bias and Sensor Position Errors. IEEE Trans. Signal Process. 61(18), 4532–4544 (2013). doi:10.1109/TSP.2013.2271750.
S Kumar, R Kumar, K Rajawat, Cooperative localization of mobile networks via velocity-assisted multidimensional scaling. IEEE Trans. Signal Process. 64(7), 1744–1758 (2016). doi:10.1109/TSP.2015.2507548.
D Li, YH Hu, in Parallel Processing Workshops, 2004. ICPP 2004 Workshops. Proceedings. 2004 International Conference On. Least square solutions of energy based acoustic source localization problems (IEEEMontreal, 2004), pp. 443–446. doi:10.1109/ICPPW.2004.1328053.
HW Wei, R Peng, Q Wan, ZX Chen, SF Ye, Multidimensional Scaling Analysis for Passive Moving Target Localization With TDOA and FDOA Measurements. IEEE Trans. Signal Process. 58(3), 1677–1688 (2010). doi:10.1109/TSP.2009.2037666.
KC Ho, W Xu, An accurate algebraic solution for moving source location using TDOA and FDOA measurements. IEEE Trans. Signal Process. 52(9), 2453–2463 (2004). doi:10.1109/TSP.2004.831921.
BW Parkinson, JJ Spilker, Global Positioning System: Theory and Applications. Progress in astronautics and aeronautics. Am. Inst. Aeronaut. Astronaut. v. 1: (1996). https://books.google.nl/books?id=lvI1a5J_4ewC.
RO Nielsen, Relationship between dilution of precision for point positioning and for relative positioning with GPS. IEEE Trans. Aerosp. Electron. Syst. 33(1), 333–338 (1997). doi:10.1109/7.570809.
PJG Teunissen, A proof of Nielsen’s conjecture on the GPS dilution of precision. IEEE Trans. Aerosp. Electron. Syst. 34(2), 693–695 (1998). doi:10.1109/7.670364.
C Park, I Kim, Comments on “relationships between dilution of precision for point positioning and for relative positioning with GPS”. IEEE Trans. Aerosp. Electron. Syst. 36(1), 315–316 (2000). doi:10.1109/7.826336.
M Abramowitz, IA Stegun, et al, Handbook of mathematical functions. Appl. Math. Ser. 55:, 62 (1966).
M Abramowitz, [Handbook of Mathematical Functions, With Formulas, Graphs, and Mathematical Tables] (Dover Publications, Incorporated, Mineola, 1974).
Competing interests
The authors declare that they have no competing interests.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Hu, Y., Leus, G. On a unified framework for linear nuisance parameters. EURASIP J. Adv. Signal Process. 2017, 4 (2017). https://doi.org/10.1186/s13634-016-0438-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13634-016-0438-8