- Research
- Open access
- Published:
Localization of ambiguously identifiable wireless agents: complexity analysis and efficient algorithms
EURASIP Journal on Advances in Signal Processing volume 2018, Article number: 30 (2018)
Abstract
In the localization of wireless agents, ambiguous measurements have significant implications regarding the complexity and quality of the agents’ positioning. Ambiguous measurements occur, for example, in multiple source localization (MSL), in which the goal is to localize the sources of signals, although the signals themselves cannot be used to differentiate among their sources. The indifferentiability of the sources results in a combinatorial optimization problem that must be solved before a localization result can be obtained. Similar effects arise, for example, in the localization of highly resource-limited wireless agents that are subject to severe size and energy constraints, meaning that neither unique identification sequences (CDMA) nor unique frequency or time resources (FDMA, TMDA) can be used. This application scenario constitutes a more general and complex joint problem of localization and ambiguity resolution that also encompasses MSL. In this work, we focus on this more general problem and its corresponding application case while maintaining applicability to the MSL problem. More precisely, we prove the \(\mathcal {NP}\)-hardness of the joint localization and ambiguity resolution problem and derive a solution framework that facilitates a comprehensive and concise formulation thereof. Thereby, we derive a minimum mean square error (MMSE)-optimal algorithm based on mixed-integer nonlinear programming and propose a relaxation of the problem with the aim of reducing the computational complexity. Additionally, simplifications are derived for the case in which bidirectional measurements are available or enforced, e.g., by the applied communication or ranging protocol.
1 Introduction
The unique identification of users and agents in wireless networks is generally regarded as a design requirement. Particularly in networks in which the localization of the network participants is essential, non-unique identification is known not only to complicate the localization process but also to significantly impact its quality. However, in some application scenarios, unique identification is inherently impossible or is prevented by highly restrictive size and energy constraints imposed on the wireless autonomous agents. Two examples of such scenarios are detailed in the following. These examples emphasize the significance and importance of localization algorithms that are able to cope with non-unique measurements, for joint localization and ambiguity resolution in particular.
Application Case 1 (Multiple source localization (MSL) In MSL, the goal is to l on the signals they emit. These signals do not include any identification information that reveals information about their original sources. Hence, stations that receive these signals cannot differentiate among their sources, which prevents the use of classical localization algorithms. This scenario is illustrated in Fig. 1 and described in more detail in Section 2.1.1.

MSL scenario with two sources and four stations that forward the measured data to a fusion center that localizes the sources. The stations cannot distinguish between the two sources, as visualized by black, i.e., non-colored signals
Application scenarios of MSL include the following:
-
The localization of, e.g., pedestrians using privacy-preserving techniques such as ultrasound
-
Passive localization of flying objects
-
Gunshot detection, e.g., in public areas
Application Case 2 Emerging application scenarios for miniature wireless agents include the exploration of secluded and difficult-to-access environments such as subterranean cavities or pipelines. Examples include oil reservoirs, which have recently been shown to be of significant economical and academic interest [1, 2]. Related industrial applications include oil extraction using the cold heavy oil production with sand (CHOPS) technique, in which sand-free channels of varying diameters, ranging from one to several centimeters, and of several hundred meters in length are created [1, 3]. Because of the high salinity of the environment [4], the use of typical radio-frequency transmitters is unattractive [5]. Hence, the use of ultrasound is being considered for communication among the agents as they traverse these channels.
Wireless agents equipped with environmental sensorsFootnote 1 are currently the most promising candidates for gathering interesting data from such an environment to answer questions regarding, e.g., the system’s temperature, pressure, or fluid composition distribution. The corresponding exploration procedure is illustrated in Fig. 2. However, in such application scenarios, particularly severe constraints are imposed on the agents. Typical examples of such constraints are listed below:
-
Size constraint: An initial feasibility study reported in [1] revealed that millimeter-sized agents are needed to successfully pass through such an environment, as larger agents are destroyed during injection or cannot be recoveredFootnote 2.
Fig. 2 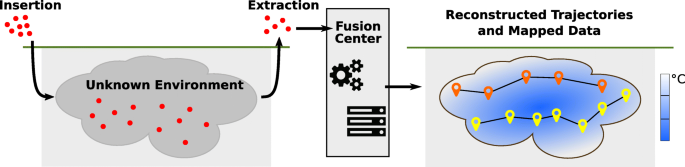
Illustration of the environmental exploration procedure: (1) Agents (visualized in red) are introduced into an unknown environment and record environmental and distance measurements for mapping and localization, respectively. The agents are carried by the fluid in the environment, e.g., water or oil. (2) The agents are extracted from the environment, and their data are sent to a fusion center to compute the agents’ trajectories (illustrated for two agents). Their environmental measurements are then used to compute, e.g., the temperature profile of the environment
-
Energy budget: Due to the size constraint, the energy available for, e.g., communication and sensing, is inherently limited. Moreover, an operation time of up to 48 h has been shown to be required [1], which demands further energy savings.
-
Swarm size constraint: Due to the spatial extent of the environment and the limitations of each individual agent with respect to its energy, communication range, and sensing capabilities, thousands of agents are required to compensate for these limitations such that sufficient data on all areas in the environment can be collected.
-
Localizability: To properly utilize the measurements made by the agents, localization of the agents is required. Because secluded and difficult-to-access environments generally do not permit positioning using GPS, pairwise distance measurements—e.g., by means of two-way ranging—are conducted. Because of the swarm size constraint and the generally strict energy limitations, significant limits must be imposed on the energy that can be spent for, e.g., communication to ensure that ranging can be performed with any arbitrary agent, which is required because of the decentralized nature of the network. Hence, all agents in the swarm must share the same time/frequency resources.

For successful exploration, a trade-off must be established between the agents’ capabilities and resource consumption. Inspired by the general feasibility of using measurements to localize wireless agents that are not uniquely identifiable–cf. Application Case 1 (the MSL case)–the use of shared communication resources is proposed. Specifically, the use of Direct-Sequence Code Division Multiple Access (DS-CDMA) for channel access is proposed, in which non-unique DS-CDMA codes are used to significantly reduce the energy consumption of the agents. In this way, the following benefits are achieved:
-
The energy consumption per ranging pulse is reduced. Instead of 2N bits, where N is the number of agents in the swarm, only 2K (K < N) bits are used in the DS-CDMA sequence, thereby reducing the energy consumed for transmission and reception.
-
Less memory is needed for storage, and less logic is needed for correlating the received DS-CDMA sequences.
-
Reductions are achieved in both the signal pulse length and multi-path effects. Multi-path effects are induced by, among other factors, the narrowness and reflectivity of the environment.
Note that the burden imposed by the main disadvantage of this approach, i.e., the increased localization complexity, is shifted to the fusion center, where offline positioning is performed after the agents have been extracted from the environment and where sufficient computational resources are available.
Conclusion Consequently, in both application cases, the following interrelated problems must be solved:
-
1.
The transmit ambiguities (TAs) in the distance measurements must be resolved, i.e., it is necessary to find a mapping between the distance measurements and the agents that recorded them.
-
2.
The agents must be localized, i.e., the positions of the agents must be estimated based on their distance measurements.
To address both problems simultaneously, algorithms are needed that can jointly resolve the ambiguities and localize the agents. Such algorithms are key enablers for the application cases described above. In the following, this joint problem is called the joint localization and transmit ambiguity resolution problem (JLTAP). This work presents a thorough analysis of this problem and the derivation of the governing constraints as well as the formulation of both optimal and sub-optimal solutions.
1.1 Related work
The MSL problem has been under study for several years, e.g., in [6–8]. However, neither a thorough graph-theoretical analysis nor a formulation of a minimum mean square error (MMSE)-optimal or maximum likelihood (ML)-optimal algorithm has yet been presented. For example, the authors of [6] considered time-of-arrival (TOA)-based measurements and proposed a heuristic solution consisting of the following three steps:
-
Coarse localization of the sound sources. In this step, important governing equations are ignored.
-
Sub-optimal TA resolution, i.e., estimation of the mapping between the TOA measurements and the sound sources. In this method, non-convex terms are replaced with local linearizations.
-
Refinement of the sound source localization result.
However, because the authors of [6] considered time instead of distance measurements, their algorithms and methods are not directly applicable to the scenarios considered in the present work.
The more general problem arising from non-unique communication identifiers, e.g., for miniature agents, was first studied by Duisterwinkel et al. in [9]. These authors considered the case in which several agents are assigned to the same OFDM sub-carrier, thus resulting in non-unique identification. To address the localization challenges posed by this scenario, a heuristic based on difference thresholding was applied, in which two distance measurements were considered to have been recorded by agent i with respect to agent j and vice versa if |mk→j − ml→i| ≤ ε.
After proposing an extended version of a similar method in [10], we presented a heuristic in [11] that enables the efficient localization of mobile agents using, e.g., a moving horizon approach. Moreover, in [12], we proposed an MMSE-optimal method under the assumption of the availability of bidirectional measurements. However, this approach targets only the resolution of the TAs and does not jointly address the localization problem.
More recently, Duisterwinkel et al. [13] presented a random sample consensus (RANSAC)-based algorithm using the difference thresholding technique introduced above. Consequently, the algorithm reported in [13] requires bidirectional measurements.
The classical ML-optimal agent localization problem, i.e., in the absence of any TAs, is known to be non-convex in general [14]. Moreover, the authors of [15] have shown that the localization problem for sparse networks and in the absence of TAs and measurement noise is \(\mathcal {NP}\)-hard. The first algorithms to focus on improving the computational feasibility of this problem via convex relaxations were based mainly on semi-definite programming (SDP), as in [16–20], and second-order cone programming (SOCP) [21]. Further SDP-based relaxations, e.g., the so-called edge-SDP relaxation, have also been derived to reduce the computational burden [22]. Furthermore, a computationally efficient multi-dimensional scaling (MDS) algorithm [23] and a matrix-completion-based approach [24] have been proposed. A global-continuation and least-squares formulation has been investigated, e.g., in [25]; such formulations are especially interesting for the localization of many agents because these algorithms are less resource-demanding than SDP and SOCP formulations.
1.2 Our contributions
Our contributions in this work are fourfold. First, we present a framework that facilitates the concise formulation of the problems corresponding to both considered application cases, and this framework is also used to illustrate that MSL is a special case of the more general JLTAP. Second, we show that the JLTAP is \(\mathcal {NP}\)-hard by means of a Karp reduction. Third, an MMSE-optimal algorithm is presented that is based on mixed-integer nonlinear programming (MINLP) and does not require bidirectional measurements. Finally, a sub-optimal algorithm is derived from the MINLP formulation to mitigate the exponential worst-case complexity of the optimal algorithm.
1.3 Organization
The remainder of this work is organized as follows: Section 2 introduces the general system model as well as the corresponding assumptions and the notation used. It also highlights the similarities between the two considered application cases. In Section 3, the governing equations for TA resolution and agent or source localization are derived and combined to formulate the optimal JLTAP algorithm. The results are used in Section 4 to derive and motivate a relaxed, sub-optimal algorithm. Numerical results and the simulation environment used to obtain them are presented in Section 5. In Section 6, conclusions are drawn and future work is outlined. The \(\mathcal {NP}\)-hardness of the JLTAP is proven in Appendix 1.
2 System model and problem formulation
Following the general methodology outlined in Section 1 and visualized in Fig. 2, the agents use their omnidirectional antennas to perform ranging with all nearby agents in their communication range, which is represented by a radius R.
It is assumed that each agent has a unique serial number (SN) and a transmission code (henceforth called a transmit ID, or simply an ID). Moreover, it is assumed that the SN is accessible only through physical access to the agent, whereas the ID is used by the agent for communication, e.g., a DS-CDMA sequence. Hence, when an agent transmits an ultrasonic pulse (ranging pulse), the receivers are aware only of the transmitter’s ID. The mapping from SNs to IDs is fixed and known only to the fusion center. Based on the transmitted ranging pulses, distance measurements can be performed, whose inaccuracy can be modeled as additive Gaussian noiseFootnote 3:
where \(n_{i,j} \sim \mathcal {N}\left (0,\sigma _{ij}^{2}\right)\) is an independently and identically distributed (iid) Gaussian noise variable with variance \(\sigma _{ij}^{2}\), di,j denotes the actual distance between agents i and j, and dj→i is the random variable (RV) that describes the distance measured by agent i based on a ranging pulse sent by agent j.
In the following, we use m∙→i to denote actual measurements, i.e., realizations of the corresponding RVs, where ∙ serves as a placeholder, and we use \(\mathcal {M}_{I}{_{\mathcal {J}\rightarrow i}}\) to denote the tuple of all measurements recorded by agent i with respect to agents using ID \(I_{\mathcal {J}}\). In the case that agents i and \(j\in S(I_{\mathcal {J}})\) are out of communication range, the corresponding non-existent measurement is represented by ∞ in the measurement tuple.
Because of the large number of agents, the continuous introduction thereof into the environment, and the long time required until the first agents reach the extraction pointFootnote 4, it is believed that the computationally intensive tracking of all agents can be replaced with a single localization computation whenever the swarm is distributed throughout the entire environment.
2.1 Notation and problem formulation
The definitions of the notation used in this paper are illustrated in Fig. 3, where \(m^{k}_{I_{\mathcal {J}\rightarrow i}}\)p denotes the kth measurement made by agent i with respect to agents using \(I_{\mathcal {J}}\), i.e., \(S(I_{\mathcal {J}})\). Note that because of the TAs, agents obtain multiple measurements with respect to a particular ID; the superscript k is introduced here for notational and illustrative purposes only. Consequently, the origins of the ranging pulses corresponding to the various measurements are not known. Therefore, resolving the TAs means solving the mapping problem between the set of measurements \(\mathcal {M}_{I_{\mathcal {J}\rightarrow i}}\) and the set of RVs \(\mathcal {D}_{I_{\mathcal {J}\rightarrow i}}=\left \{d^{k}_{j\rightarrow i}|j \in S(I\mathcal {J}), k \in \mathbb {N}\right \}\). More precisely, each measurement needs to be mapped to an RV subject to certain constraints, which will be derived in Section 3.

Illustration of the notation used in this paper and the effects of TAs. Consider an agent i, which is assumed to use ID \(I_{\mathcal {R}}\) (red) and two nearby agents (which use ID \(I_{\mathcal {B}}\) (blue)), one of which is within the communication range (denoted by R) of i. The actual distances between the pairs of agents and the RVs that describe the possible measurements of these distances are illustrated. For the two cases, the table on the right-hand side clarifies both the notation and the fact that no distance measurement is made between i and k. Here, \(m {\dot {\sim }} d\) is used to denote that the measurement m is a single realization, i.e., sample, of the distribution d
An example network in which TAs arise is depicted in Fig. 4a, where two agents (“5” and “6”) both use ID \(I_{\mathcal {R}}\) (red) and a third node (“7”) uses \(I_{\mathcal {B}}\) (blue). Node “7” receives two ranging pulses from the other two nodes. Based on these pulses, it measures the ranges \(\left (m^{1}_{I_{\mathcal {R}\rightarrow 7}}~\text {and}~ m^{2}_{I_{\mathcal {R}\rightarrow 7}}\right)\). Because of the TA, it cannot uniquely relate the measured ranges to the physical agents \(\mathcal {S}(I_{\mathcal {R}})\), and hence, localization using classical methods such as those discussed in Section 1.1 is not possible. Henceforth, the following formal definition will be adopted for the problem at hand.

a Illustration of a network in which two agents (“5” and “6”) are using the same ID. The edges are annotated with the corresponding measurements of the ranging pulses. This graph is also called the true graph. b Graph showing the effective ambiguities due to the TAs. Here, additional edges are introduced to account for all potential origins. The edges are annotated with their weights. c Graph showing the labels or names of the edges that match the variable notation \(x_{ij}^{k}\) introduced in Section 3.1.2. Note that the order of the superscript numbering is arbitrary. Example, \(\mathcal {W}_{A}\left (e_{5,7}^{2}\right)~=~m_{A\rightarrow {{id}{R}}{7}}^{2}\). The graphs in b and c are also called ambiguity graphs
Definition 1
(Joint localization and transmit ambiguity resolution problem (JLTAP)) In the JLTAP, the objective is to jointly estimate the Cartesian position of each agent based on the obtained range measurements. Inherently, it is necessary to resolve the TAs, i.e., to find a mapping between each measurement \(m_{I_{{\mathcal {J}\rightarrow i}}}^{k}\) and the corresponding agent \(l\in S({I_{\mathcal {J}}})\) such that \(m^{k}_{I_{\mathcal {J}\rightarrow i}}\) is a realization of the RV dl→i.
A corresponding mathematical description, including the formulation of an optimization problem, is derived in Section 3.1.
2.1.1 Relationship with MSL
In MSL, the objective is to localize sources based only on the signals they emit. An example scenario is illustrated in Fig. 1, where two sources emit sound signals that are received by nearby stations. Because the stations cannot differentiate between the two different sources of the signals they receive, the fusion center, which has access to the measurements from all stations, must resolve the ambiguities in the measurements and perform the localization. Consequently, the MSL problem is closely related to the problem considered in this work. However, the following assumptions are usually adopted in the case of MSL (see, e.g., [6]):
-
i)
The sensitivities of the stations and their positions are such that every station can receive signals from all sources. Consequently—unlike in the case of wireless agent localization—the measurements consist only of direct distance measurements between the stations and the sources. This generally reduces error propagation during localization and simplifies the problem formulation, as out-of-range agents do not need to be considered.
-
ii)
The number of stations and their positions are such that the conditions for good localization (see, e.g., [26, 27]) are fulfilled once the ambiguities have been resolved.
-
iii)
There are significantly fewer sound sources in the case of MSL than there are wireless agents in the application case considered in the present work. Therefore, the complexity of the ambiguity resolution problem is significantly lower in the MSL case.
-
iv)
Only one kind of source is considered. This is equivalent to the assumption that all sources use the same transmit ID.
Items i) and iv) in particular render MSL algorithms inapplicable for the more general problem considered in this work (cf. Application Case 2).
A high-level comparison between the two problems corresponding to the two considered application cases is presented in Table 1.
3 MMSE-optimal JLTAP formulation
This section is divided into two main parts. The first, Section 3.1, covers the derivation of the mathematical formulation of the TA resolution problem. The second, Section 3.2, covers the incorporation of the localization problem to obtain the joint optimization formulation of the JLTAP.
3.1 Part I: derivation and properties of the TA resolution formulation
Based on the assumptions stated in Section 1, the following graph-theoretical representation is used:
-
1)
Every agent is modeled as a vertex of a graph, i.e., agent i corresponds to vertex \(v_{i} \in \mathcal {V}_{T}\).
-
2)
Every measurement is represented by a directed edge from v j to v i , \(e_{ji}~=~(v_{j},v_{i})\in \mathcal {E}_{T}\), where v i is the agent that recorded the measurement mj→i associated with this edge.
-
3)
Every edge in the graph has a corresponding weight \(\mathcal {W}(e_{ji}) ~=~m_{j\rightarrow i } \), which is equal to the value of the associated distance measurement.
Henceforth, this graph is called the true graph (TG), \(G_{T}~=~ (\mathcal {V}_{T}, \mathcal {E}_{T}, \mathcal {W}_{T})\), because its representation inherently assumes that either no TAs have arisen or all TAs have been resolved. An example is given in Fig. 4a. For simplicity of description, a graph-theoretical view is adopted, in the sense that the origin of a measurement mj→i (and edge e j i ) is considered to be agent or vertex j, whereas the term target is used to refer to agent or vertex i, which actually measured the distance.
3.1.1 Problem analysis
To derive the solution to the TA resolution problem, the following observations are considered:
-
4)
For every measurement \(m_{I_{\mathcal {J}}\rightarrow i}^{k}\), every agent in \(\ifthenelse {\equal {I_{\mathcal {J}}}{}}{S}{S(I_{\mathcal {J}})}\) is a potential origin candidate.
-
5)
The solution to the TA resolution problem should consist of exactly one unique mapping, i.e., exactly one origin for each measurement.
-
6)
Between each pair of vertices, there can be at most one edge in each direction, i.e., at most one edge e = (v i ,v j ) and at most one edge e′ = (v j ,v i ).
An example of the TA-aware graph representation is shown in Fig. 4b, and this representation is subsequently referred to as the ambiguity graph (AG). Note that this graph is generally a directed multi-graph. The AG is denoted by \(\mathcal {G}_{A}~=~(\mathcal {V}_{A},\mathcal {E}_{A},\mathcal {W}_{A})\) and is defined as follows:
-
7)
The vertices correspond to agents in the network.
-
8)
For each measurement \(m_{I_{\mathcal {J}}\rightarrow i}^{k}\), a directed edge with a weight of \(m_{I_{\mathcal {J}}\rightarrow i}^{k}\) is drawn between v i and each \(v_{j}~ (j\in S({I_{\mathcal {J}})})\). Edges of this kind are henceforth referred to as copies of both each other and the corresponding measurement. Consequently, there are \(\vert S({I_{\mathcal {J}}}) \vert \) directed edges with a weight of \(m^{k}_{I{_{\mathcal {J}\rightarrow i}}}\) pointing to vertex v i .
3.1.2 Mathematical formulation
From the descriptions provided above, it can be understood that the problem of resolving the TAs is a special kind of decision or selection problem. Consequently, the mathematical formulation will include binary decision variables with the following constraints:
-
9)
For each edge in the AG, a binary decision variable denoted by \(x_{ji}^{k} \in \{0,1\}\) is introduced. This variable will be equal to one iff the corresponding edge, i.e., the measurement \(m^{k}_{I{_{\mathcal {J}\rightarrow i}}}\), is selected to represent the mapping of a measurement made by agent i to a ranging pulse from agent j.
-
10)
Once an edge \(m_{I_{\mathcal {J}}\rightarrow i}^{k}\) has been selected, all copies of that edge, i.e., those that were created due to Item 8, can no longer be selected. Consequently, the sum of the corresponding decision variables is constrained to be exactly one.
-
11)
Because the static case is considered, at most one measurement may be selected from among all parallelFootnote 5 edges between two vertices. This is necessary because copy edges, cf. Item 8, are drawn between all possible vertices and full connectivity is not necessarily guaranteed. Consequently, the sum of all corresponding decision variables is constrained to be at most one.
Thus, the following feasibility problem, which considers only the resolution of the TAs, can be formulated. In the following subsection, this problem will be extended to the complete JLTAP by incorporating the joint consideration of the localization problem.
Here, \(\mathcal {C}\left (e_{ij}^{k} \right)\) denotes the set of all copies of \(e_{ij}^{k}\) (cf. Item 8), \(\mathcal {P}_{i,j}\) is the set of all parallel edges directed from vertex i to vertex j, and \(x_{ij}^{k}\) is the decision variable corresponding to edge \(e_{ij}^{k}\). Note that constraints (2c) and (2d) arise directly from the description of the AG (cf. Items 8, and 10). Item 11 is accounted for by constraints (2e) and (2f), which both account for parallel edges.
Remark
Although constraints (2e) and (2f) are redundant, they are explicitly mentioned in Eq. (2) because simulations have shown that their explicit formulation enables significant reductions in computational complexity.
For the example depicted in Fig. 4, the copy sets and parallel sets are given in Table 2.
3.2 Part II: TA-free wireless agent localization and JLTAP formulation
The objective of agent localization is to obtain the Cartesian positions \(\boldsymbol {p}_{i}~=~(p_{x,i}, p_{y,i})^{\intercal }\) or \(\boldsymbol {p}_{i}~=~(p_{x,i}, p_{y,i},p_{z,i})^{\intercal }\) of all agents \(i\in \mathcal {V}\) from noisy distance measurements (cf. Eq. (1)). The matrix of all agent positions is denoted by \(\boldsymbol {P}~ =~ \left (\boldsymbol {p}_{1}, \ldots, \boldsymbol {p}_{\vert \mathcal {V} \vert } \right)\). Because of the assumption of iid additive Gaussian noise, the corresponding ML objective function for the localization problem can be easily derived [28]:
Note that this problem is known to be non-convex in general [14]. For simplicity, it is assumed that all noise variances are equal, i.e., \(\sigma _{ij}~=~\sigma \;\forall (v_{i},v_{j})\in \mathcal {E}\).
3.2.1 Integration into the JLTAP
To obtain a joint problem formulation that includes both localization and TA resolution, which requires combining the objective function given in (3) with the feasibility problem expressed in (2), the following issues must be resolved:
-
12)
Due to the TAs and the joint approach, the particular measurements mj→i to be used in (3) are not known because the decision problem regarding their mapping has not yet been solved.
-
13)
In the AG that serves as the basis for solving the JLTAP, edges exist for all possible candidates. However, in (3), only those pairs of vertices (v i ,v j ) to which a measurement is currently assigned should be considered.
To accommodate these constraints, the objective function given in (3) is modified as follows:
where \( \mathcal {W}_{A}(e_{ij}^{k})\) denotes the weight (measurement value) of edge \(e_{ij}^{k}\) in the AG (cf. Fig. 4) and all \(x_{ij}^{k}\) are the same binary decision variables as in (2).
In this expression, the sum in the inner brackets will select the measurements to be used and– in conjunction with further constraints– ensure that at most one measurement per link is chosen (cf. Item 12. The second sum, which is newly introduced here, ensures that the case in which no measurement is selected is also handled correctly (cf. Item 13.
3.3 Synthesis and NP-hardness
This section combines the results from the previous Sections 3.1 and 3.2 to obtain the MMSE-optimal formulation of the JLTAP. Moreover, an extension of the joint formulation expressed in (5) is presented that facilitates faster and more accurate solutions in the case that bidirectional measurements are available or corresponding solutions should be enforced.
Based on the results obtained in Sections 3.1 and 3.2, the MMSE-optimal JLTAP formulation can be expressed as follows:
where the objective function represents the residual localization error and the constraints arise from the TA resolution conditions.
Note that this problem is a MINLP problem. In Appendix 1, we prove that solving Problem (5) requires solving a problem that is \(\mathcal {NP}\)-hard in general. For this reason, a relaxation of this problem is introduced in the following section.
3.3.1 Applicability to MSL
As outlined in Section 2.1.1, MSL can be regarded as a special case of the JLTAP, and thus, Problem (5) can also be used to describe MSL problem instances. To this end, it should be noted that in MSL, all sources have the same ID. Consequently, copy edges are introduced among all sources, and the set of parallel edges is easily deducible. However, a formal simplification of Problem (5) for the case of MSL is generally not possible.
3.3.2 Enhancements for bidirectional measurements
In the case that bidirectional measurements are guaranteed or corresponding solutions should be enforced, additional constraints can be introduced. These constraints reduce the search space and have thus been shown to significantly reduce the run-time and memory demands placed on solvers.
The constraints are given as follows:
where \(\mathcal {B}\) is the set of those pairs of vertices (v i ,v j ) for which \(\vert \mathcal {P}_{i,j} \vert ~>~0\) and \(\vert \mathcal {P}_{j,i} \vert ~>~0\), i.e., those pairs for which solution candidates exist that can fulfill the bidirectionality criterion. Similarly, \(\overline {\mathcal {B}}\) denotes the set of vertex pairs for which this is not the case.
4 JLTAP relaxations
To mitigate the difficulties caused by the non-convexity, \(\mathcal {NP}\)-hardness, and general computational complexity of the optimal JLTAP algorithm presented in Section 3.3, this section introduces a relaxation of the JLTAP problem. The purpose is to make the original problem more numerically tractable while requiring only minor modifications to the objective function and the constraints.
The following approximations and simplifications are adopted:
-
The weights and distance estimates in the objective function are replaced with their squared counterparts to reduce the computational complexity. This is mainly motivated by the resulting simplifications of the gradients and Hessians (cf. also Appendix 3 for an analysis of both objective functions with respect to their extrema).
-
The binary constraint (5b) is replaced with a continuous interval constraint, i.e., \(x_{ij}^{k} \in [0,1]\) is substituted for \(x_{ij}^{k} \in \{0,1\}\). In this way, all discrete optimization variables are replaced with continuous variables, which eliminates the need for discrete solvers.
-
The constraint corresponding to Item 13 is loosened, i.e., the equality constraint \(q_{ij} ~=~ \sum _{k} x_{ij}^{k}\) is replaced with the inequality constraint \( q_{ij} ~\geq ~ \sum _{k} x_{ij}^{k}\). In simulations not reported in this work, this relaxation has been shown to yield improved convergence and accuracy. Details regarding the non-convexity of the relaxed JLTAP without this relaxation can be found in Appendix 2.
Thus, the following optimization formulation of the relaxed, sub-optimal JLTAP is obtained:
Note that the objective function–and hence Problem (7)–is still non-convex, although a dedicated integer programming solver is no longer required. Consequently, classical interior-point solvers can ensure only locally optimal solutions. Due to the joint approach, the positions of the agents are also directly estimated, meaning that a reversal of the relaxation– i.e., a mapping from the continuous \(x_{ij}^{k} \in [0,1]\) to the binary variables \(x_{ij}^{k} \in \{0,1\}\)– is not required.
5 Numerical results and discussion
In this section, numerical results obtained using the developed algorithms are presented and discussed.
5.1 Method
The Monte Carlo simulation results presented in the following subsections were obtained as follows:
-
The data collected by the agents distributed in the environment were simulated (cf. Section 5.2).
-
The data processing performed by the fusion center (cf. Fig. 2) was simulated to evaluate the proposed algorithms using the simulated agent measurements.
-
A performance comparison of the algorithms was performed using the metric defined in Section 5.3.
All simulations were performed using MATLAB and the BARON solver [29].
5.2 Simulation environment
Simulations were performed by randomly placing N agents in the two-dimensional unit box [−0.5,0.5]2 following a uniform distribution. To ensure that the IDs were assigned to the agents as equally as possible, the following procedure was used: First, \(\lfloor \frac {N}{I} \rfloor \) instances of each ID were placed in the ID pool, where I is the number of IDs. Then, one additional ID instance from among the first \(N~-~I\lfloor \frac {N}{I} \rfloor \) IDs was placed in the pool. Finally, the IDs in the pool were randomly assigned to the agents. All agents were given the same communication range, i.e., the sensing radius R.
The applied solvers were initialized with normally distributed random solutions pinit,i = p i + ninit, \(\boldsymbol {n}_{\text {init}}\sim \mathcal {N}\left (0,\sigma _{p_{i}}^{2}\boldsymbol {I}_{2}\right)\), where \(\phantom {\dot {i}\!}\forall i, \sigma _{p}~=~\sigma _{p_{i}}~=~0.15\) was chosen. Moreover, four anchor nodes were placed at positions of (−0.25,0.25), (−0.25,−0.25), (0.25,0.25), and (0.25,−0.25). All figures show results averaged over 100 simulations. Because the numerical evaluation of the optimal JLTAP algorithm is computationally demanding in terms of both run time and memory, a run-time limit of 5 days was imposed. When the run-time limit was reached, the best known solution was chosen as the result.
5.3 Evaluation metric
For both the optimal and relaxed algorithms, the performance was evaluated using the root mean square error (RMSE) of the position estimates \({\hat {\boldsymbol {p}}}_{i}\) with respect to the actual positions p i :
5.4 Simulation results and discussion
The simulation results are split into two sets. The first set consists of localization performance comparisons between the optimal JLTAP formulation (Problem (5)) and the relaxed JLTAP formulation (Problem (7)). The corresponding results are presented in Fig. 5 for various configurations of agents and IDs and for agents with varying communication ranges. The plots show that the communication range is the most important complexity-determining parameter, apart from the numbers of agents and IDs (see also Table 3). The second set of comparisons is presented in Fig. 8 and consists of run-time comparisons for the optimal and relaxed formulations.

a RMSE-based performance comparison between the optimal and relaxed JLTAP formulations for N = 40 agents and different numbers of unique IDs. b RMSE-based performance comparison between the optimal and relaxed JLTAP formulations for N = 20 agents and different numbers of unique IDs. Note that an upper limit of 5 days (approx. 4.3 × 105 s) was imposed on the run time (cf. Section 5.2)
5.4.1 Localization performance
Figure 5a shows the RMSE performances for N = 40 agents with 8 and 12 IDs. In addition to a marked performance advantage of the relaxed formulation for 12 IDs and somewhat superior performance of the relaxed formulation for 8 IDs, a significant change in performance is observed when the sensing radius R is 1.1 or greater. The visible change in the performance trend for the optimal JLTAP formulation can be explained by the higher complexity of the TA resolution problem due to the increased connectivity in conjunction with the run-time limit.
Another set of comparisons for N = 20 agents is presented in Fig. 5b, where scenarios with 6 and 8 IDs are represented. Compared with the results shown in Fig. 5a, increased variance is observed in the results, which leads to less steady average localization performance. Nevertheless, it can be observed that the relaxed JLTAP algorithm still outperforms the optimal JLTAP algorithm, mainly because of the imposed run-time constraint of 5 days and the numerical challenges associated with the optimal JLTAP formulation. Exemplary localization results for two of the four tested configurations are presented in Fig. 6, where the actual agent positions are shown as green circles, the average position estimates are shown as red crosses, the anchor node positions are indicated by black diamonds, and the 1-standard-deviation regions are visualized as blue ellipses. The configurations shown in Fig. 6a,b each contains 20 agents using 6 IDs. The average localization accuracies in terms of the RMSE are 2.0312 × 10−3 and 1.1022 × 10−2, respectively. Meanwhile, the configurations shown in Fig. 6c, d each contains 40 agents using 8 IDs. The average localization accuracies in terms of the RMSE are 1.9561 × 10−2 and 4.4269×10−2, respectively. Results with somewhat high standard deviations (blue ellipses) occur mainly at the border of the environment, where the average connectivity is lower and localization is consequently more difficult.

All plots visualize average localization results (red crosses) and their 1-standard-deviation ellipses (blue ellipses) calculated over 100 simulations, in which the positions were held fixed and only the measurement noise was varied among the different simulations. The actual positions of the agents are shown by green circles, and the positions of the anchor nodes are indicated by black diamonds. a and b visualize the statistics for two different random agent placements, each with N = 20 agents and 6 IDs. Likewise, c and d visualize the statistics for two different random agent placements, each with N = 40 agents and 8 IDs
It should be noted that the results discussed above are subject to two important effects with opposing complexity trends:
-
With increasing connectivity, the number of measurements rises and the TAs consequently increase, resulting in a more complex optimization problem in the sense of greater numbers of constraints and variables.
-
With increasing connectivity, measurements exists for more and more pairs of agents. Consequently, for R→∞, the effect of erroneously summed squared residual terms for pairs of agents without currently hypothesized measurements is vanishing (cf. Item 13). This also limits the search space for q i j as \(q_{ij}\xrightarrow {R\rightarrow \infty }1\).
5.4.2 Influence of measurement noise
Additional simulations were performed to analyze the robustness of the proposed relaxed JLTAP method with respect to measurement noise, and the results are presented in Fig. 7 for different sensing radii R. The figure shows that the localization error (RMSE) increases linearly with the standard deviation of the measurement noise. Consequently, the relaxed JLTAP algorithm exhibits reasonable robustness with respect to measurement noise.

Localization performance of the relaxed JLTAP algorithm with varying levels of measurement noise for a N = 40 agents with 12 IDs and b N = 20 agents with 6 IDs
5.4.3 Run-time performance
Run-time comparisons for both algorithms with the previously described agent configurations are presented in Fig. 8. In both panels of the figure, the optimal JLTAP algorithm already reaches its maximal run-time constraint of 5 days for the moderate connectivity that results from a sensing radius of R = 0.5. By contrast, the run time of the relaxed JLTAP algorithm varies, particularly in Fig. 8a, which presents results from simulations with N = 40 agents. The drastic increase in run time for both algorithms is mainly due to the increased connectivity and the corresponding increase in combinatorial complexity (see also Section 5.4.1 first bullet).

Run times for the configurations evaluated in Fig. 5, with a N = 40 agents and b N = 20 agents, each with different numbers of IDs and with σ = 0.01. Note that an upper limit of 5 days (approx. 4.3×105 s) was imposed on the run time
6 Conclusions
In this work, the problem of ambiguous ranging measurements and their impact on localization has been discussed, and two exemplary application cases have been highlighted: multiple source localization (MSL) and the localization of highly resource-constrained wireless sensing agents. These application cases are relevant to novel and existing challenges arising, e.g., in the passive localization of traffic participants, flying objects, or shooters and the surveying of resource-rich subterranean cavities (cf. Section 1).
We have shown that the problem corresponding to the former application case is a special case of that corresponding to the latter. In the context of this problem, i.e., the problem of the joint localization of wireless agents and resolution of ambiguities in ranging measurements (the JLTAP), a detailed and thorough derivation and analysis of the underlying graph-theoretical problem has been presented to serve as the basis for solving the problems arising in both application cases. Utilizing this description and the corresponding optimization problem formulation, we have derived and presented an MMSE-optimal JLTAP algorithm, and we have proven its \(\mathcal {NP}\)-hardness. Moreover, to mitigate the exponential worst-case complexity of the optimal algorithm, we have derived a sub-optimal JLTAP algorithm through relaxations and approximations. In contrast to the existing literature on MSL in particular, both formulations are capable of reflecting the likely scenario in which sources or agents are not always in range of stations or beacons. Consequently, the presented algorithms not only are suitable for a broader variety of applications—such as those mentioned above—but also yield efficient solutions for a less restrictive set of scenarios corresponding to the existing application cases.
In the presented numerical evaluations, we have shown that the proposed sub-optimal algorithm offers significant gains in localization performance of up to 260% and reductions in run time by a factor of up to 9902. Consequently, efficient localization can be achieved, which is particularly important when many agents need to be localized.
6.1 Outlook
Because this work has focused on the more general problem corresponding to Application Case 2 (cf. Section 2), in our future work, we intend to analyze the proposed algorithms in direct comparison with existing MSL algorithms. We will also adapt the system model for different types of measurements, such as time-of-arrival (TOA) measurementsFootnote 6 and passive TOA measurementsFootnote 7.
Nomenclature
-
\(\mathcal {S}\) Set of all serial numbers (SNs) used by the agents
-
\(\mathcal {S}_{a}\) Set of all serial numbers (SNs) used by the anchor nodes
-
\(\mathcal {I}\) Set of all transmit IDs used by the agents
-
\(S(I_{\mathcal {J}})\) Set of agents that use ID \(I_{\mathcal {J}}\)
-
agent i Agent with the unique SN i
-
di,j Actual distance between agents i and j
-
dj→i Random variable (RV) denoting the distance measured by agent i based on a signal from agent j
-
\(\mathcal {M}_{I_{\mathcal {J}\rightarrow i}}\) Tuple of measurements recorded by agent i, e.g., \(\mathcal {M}_{I{_{\mathcal {J}\rightarrow i}}}=\left (\ldots,m_{I_{\mathcal {J}}\rightarrow i}^{k}, \ldots \right)\), where k denotes the kth agent using ID \(I_{\mathcal {J}}\)
-
\(m^{k}_{I_{\mathcal {J}\rightarrow i}}\) Measurement (realization of the corresponding RV) at agent i w.r.t. the kth agent using \(I_{\mathcal {J}}\)
-
\(\mathcal {C}\left (e_{ij}^{k}\right)\) Set of edges that are copies of edge \(e_{ij}^{k}\)
-
\(\mathcal {P}_{ij}\) Set of edges parallel to edge (i,j)
-
∋ Shorthand version of such that for sets; e.g., \(\forall \boldsymbol {x}\in \mathbb {R}^{n} \ni \Vert \boldsymbol {x}\Vert \leq 1\) defines the n-dimensional unit ball around 0
-
\(\mathcal {W}_{A}(e)\) Weight of edge e in the corresponding ambiguity graph
-
σ i j Standard deviation of the noise in measurements between agents i and j
-
\(\sigma _{p_{i}}\) Standard deviation of the noise in the initial positions of the agents as used in the solver initialization
-
\(\boldsymbol {p}_{i}, \hat {\boldsymbol {p}}_{i}\) Actual and estimated Cartesian positions of agent i
-
P Matrix of all agents’ Cartesian positions
-
ρ Vectorized form of P
-
R Sensing, i.e., communication radius of the agents
-
[z] i ith component for vector z
-
[p i ] x ,[p i ] y X and Y coordinates of position vector p i
7 Appendix 1: NP-hardness proof
The \(\mathcal {NP}\)-hardness proof presented here makes use of a reduction from the perfect matching with conflict pair constraints (PMPC) problem, which is known to be strongly \(\mathcal {NP}\)-hard [31, 32]. The corresponding decision problem is briefly described in the following.
Definition 2
(Perfect matching with conflict pair constraints (PMPC) problem [31, 32])
-
The input: An undirected graph \(\mathcal {G}~=~(\mathcal {V},\mathcal {E})\) and an undirected graph \(\bar {\mathcal {G}}~=~(\mathcal {E},\bar {\mathcal {E}})\), where each of the \(\vert \mathcal {E} \vert \) vertices of \(\bar {\mathcal {G}}\) belongs uniquely to one edge \(e\in \mathcal {E}\) in \(\mathcal {G}\).
-
The existence of an edge \(\bar {e} \in \bar {\mathcal {E}}\) implies that the two adjacent vertices (edges of \(\mathcal {G}\)) cannot both appear simultaneously in the perfect matching (PM) of \(\mathcal {G}\).
-
The question: Does a PM in \(\mathcal {G}\) exist such that adjacent vertices in \(\bar {\mathcal {G}}\) do not both belong to the PM?
To provide a concise proof, the following brief graph-theoretical summary of the problem defined in Definition 1 is used.
Definition 3
(Graph-theoretical decision problem formulation of the JLTAP)
-
The input: A(n) (un)directed graph \(\mathcal {G}~=~(\mathcal {V},\mathcal {E})\) and several edge sets that belong uniquely to the following two categories (cf. Section 3.1):
-
1.
\(\mathcal {E}_{{=}1} = \bigcup \nolimits _{i} \mathcal {E}_{{=}1}^{i} \),
-
2.
\(\mathcal {E}_{{\leq }1} = \bigcup \nolimits _{i} \mathcal {E}_{{\leq }1}^{i} \),
which represent sets of edges of which exactly one (Item 1) and of which at most one (Item 1) needs to be selected. Moreover, each edge in these sets corresponds uniquely to one edge in \(\mathcal {E}\) of \(\mathcal {G}\).
-
1.
-
The question: Does a subset \(\mathcal {E}^{*} \subseteq \mathcal {E}\) exist such that exactly one edge from each non-empty set \( \mathcal {E}_{{=}1}^{i}\) appears in \(\mathcal {E}^{*}\) and at most one edge from each \(\mathcal {E}_{{\leq }1}^{i}\) appears in \(\mathcal {E}^{*}\)?
The \(\mathcal {NP}\)-hardness proof is based on a Karp reduction, the principle of which (proof by contradiction) is depicted in Fig. 9. To complete the proof, we will define a polynomial-time reduction algorithm and a polynomial-time decider. Subsequently, the correctness proof for the decider will be briefly outlined.

Principle of Karp reductions. Problem X is reduced to problem Y: X≤ p Y
Definition 4
(Polynomial-time reduction (PTR) algorithm) The PTR algorithm transforms an instance x of the PMPC problem into an instance y of the JLTAP decision problem by means of the following steps:
-
The input: An instance x, i.e., two undirected graphs \(\mathcal {G}_{x}~=~(\mathcal {V}_{x},\mathcal {E}_{x})\) and \(\bar {\mathcal {G}}_{x}~=~(\mathcal {E}_{x}, \bar {\mathcal {E}}_{x})\).
-
The output: An instance y, i.e., an undirected graph \(\mathcal {G}~=~(\mathcal {V},\mathcal {E})\) and several sets \(\mathcal {E}_{{=}1}^{i}, i=1,\ldots,n\), and \(\mathcal {E}_{{\leq }1}^{j}, j=1,\ldots,m\).
-
The transformation:
-
1.
Set \(\mathcal {E}:= \emptyset \) and \(\mathcal {V} := \mathcal {V}_{x}\).
-
2.
For each vertex \(v_{i} \in \mathcal {V}_{x}\), create a new set \(\mathcal {E}_{{=}1}^{i}\) with all edges incident on v i .
-
3.
For all edges \(\bar {e}_{ij}=(e_{i},e_{j})\in \mathcal {E}_{x} \times \mathcal {E}_{x}\), create a set \(\mathcal {E}_{{\leq }1}^{ij}=\{ e_{i}, e_{j} \}\).
-
1.
Definition 5
(Polynomial-time decider (PTD)) The PTD takes the output of the imaginary polynomial-time solver for the JLTAP decision problem and decides whether the answer to the problem instance x is yes or no.
-
The input: The solution \(\mathcal {E}^{*}\) and the problem instance y corresponding to \(\mathcal {G}=(\mathcal {V},\mathcal {E})\) and the sets \(\{\mathcal {E}_{{=}1}^{i}\}_{i}\) and \(\{\mathcal {E}_{{\leq }1}^{j}\}_{j}\).
-
Return yes iff exactly one edge from each set \(\mathcal {E}_{{=}1}^{i}\) and at most one edge from each set \(\mathcal {E}_{{\leq }1}^{j}\) are in \(\mathcal {E}^{*}\).
Proof Sketch 1(Sketch of the Decider Correctness Proof) To prove the correctness of the decision algorithm, the equivalence of the following two statements must be shown: A PM exists in the PMPC instance given by \(\mathcal {G}\) and \(\bar {\mathcal {G}}\). ⇔ The solution set \(\mathcal {E}^{*}\) is such that exactly one edge from each set \(\mathcal {E}_{{=}1}^{i}\) and at most one edge from each set \(\mathcal {E}_{{\leq }1}^{i}\) appear in \(\mathcal {E}^{*}\).
To see that this is the case, note that the existence of a PM in the PMPC instance means that there exists a set \(\mathcal {M} \subseteq \mathcal {E}\) such that every vertex in \(\mathcal {G}\) is incident on exactly one edge in the matching \(\mathcal {M}\) [33] and that for each conflict pair in \(\bar {\mathcal {G}}\), both edges do not appear simultaneously in the matching \(\mathcal {M}\). Mathematically, we can write this statement as
where \(\mathcal {I}(v)\) denotes the set of edges incident on vertex v and \(\mathcal {A}(e)\) denotes the set of vertices in the conflict graph that are adjacent to vertex e. Recall that by the definition of the conflict graph (cf. Definition 2), the vertices of the conflict graph are edges of \(\mathcal {G}\).
The outline of the correctness proof given below shows that the two constraints (⋆) and (⋆⋆) are inherently fulfilled by the definition of the reduction algorithm (cf. Definition 4).
-
(⋆) By definition, the set of edges incident on vertex v i is given by \(\mathcal {E}_{{=}1}^{i}\), i.e., \(\mathcal {I}(v_{i})=\mathcal {E}_{{=}1}^{i}\). In addition, the constraint \(\vert \mathcal {I}(v_{i}) \cap \mathcal {M} \vert =1\) means that exactly one of these incident edges must be in \(\mathcal {M}\).
-
(⋆⋆) Note that \(\mathcal {A}(e)\) denotes the set of edges that are in conflict with edge e and that these conflicts—with respect to e—are represented by \(\vert \mathcal {A}(e) \vert \) sets of the form \(\mathcal {E}_{{\leq }1}^{i}=\{e, e_{k}\}\), where \(e_{k} \in \mathcal {A}(e)\). The set comprising these \(\vert \mathcal {A}(e) \vert \) sets is henceforth denoted by \(\mathcal {E}_{{\leq }1}(e)\). Consequently, \(\mathcal {A}(e)\) can be written as follows:
$$\begin{array}{*{20}l} \mathcal{A}(e) = \bigcup_{\mathcal{E}' \in \mathcal{E}_{{\leq}1}(e)} \mathcal{E}'\backslash e. \end{array} $$(10)Likewise, for constraint (⋆⋆), we have the following:
$$ (\star\star) \Leftrightarrow \mathcal{M} \cap ~ \bigcup\limits_{{\mathcal{E}' \in \mathcal{E}_{{\leq}1}(e)}}~ \mathcal{E}' =\left\{ \begin{array}{ll} \emptyset, & \text{if}~ e \notin \mathcal{M}\\ e, & \text{otherwise} \end{array} \right., \forall e \in \mathcal{E}. $$(11)Thus, its clear that (⋆⋆) is equivalent to the requirement that at most one edge from each set \(\mathcal {E}_{{\leq }1}^{i}\) must be in \(\mathcal {E}^{*}\).
8 Appendix 2: Non-convexity of the relaxed JLTAP with q i j equality constraint
In this section, the general non-convexity of the relaxed JLTAP objective function and, thus, of the relaxed JLTAP optimization problem is shown. Without loss of generality, the following summand of the objective function is considered for simplicity:
where \(\hat {\boldsymbol {w}}^{\intercal } = \left (\mathcal {W}_{A}^{2}\left (e_{ij}^{1} \right), \ldots, \mathcal {W}_{A}^{2}\left (e_{ij}^{K}\right)\right) \) and q=q i j . The Hessian of (12) is partitioned into decision variables x and positions \(\boldsymbol {\rho } =\left [\boldsymbol {p}_{i}^{\intercal } \quad \boldsymbol {p}_{j}^{\intercal }\right ]^{\intercal }\):
Let d be the shorthand notation for \(d(\boldsymbol {\rho }) = \Vert \boldsymbol {p}_{i} - \boldsymbol {p}_{j} \Vert _{2} = \sqrt {(\Delta _{x})^{2} + (\Delta _{y})^{2} }\), with Δ x = [p i ] x − [p j ] x ,Δ y = [p i ] y − [p j ] y . Then, the partial derivatives can be written as follows:
By considering the Schur complement [34], it can be found that the Hessian of f(·) is positive semi-definite, i.e., \(\mathcal {H}(f) \succeq 0\), if and only if the following three conditions are met:
where Ag denotes the generalized inverse of A.
Therewith, we form the following theorem regarding the non-convexity of (12):
Theorem 1
The relaxed JLTAP objective as described in Section 4 but with binding \(q := q_{ij} = \sum _{k} x_{ij}^{k}\) as given in (12) is non-convex for the relevant case of q>0.
Proof
Using Propositions 1 and 2, it holds regarding Eqs. (15a) and (15b)
However, using Proposition 4, it holds regarding (15c)
thus violating (15c) if (15a) is satisfied. □
Remark
Moreover, the constraint \(h={\tilde {\boldsymbol {w}}}^{\intercal }~ x - d^{2} \leq 0\) is non-convex.
Proposition 1
\(\nabla _{\boldsymbol {\rho \rho }}^{2} f\) is positive semi-definitive, i.e., \(\nabla _{\boldsymbol {\rho \rho }}^{2} f \succeq 0\) iff \(h \leq 0 \Leftrightarrow d^{2} \geq \tilde {\boldsymbol {w}}^{\intercal } x\).
Proof
From straightforward calculations, we find that \(\nabla _{\boldsymbol {\rho \rho }}^{2} f \) has non-zero eigenvalues:
and, thus, \(\lambda _{1}(\nabla _{\boldsymbol {\rho \rho }}^{2} f) \geq 0 \Leftrightarrow h \leq 0\) which also yields \(\lambda _{2}(\nabla _{\boldsymbol {\rho \rho }}^{2} f) \geq 0\). □
Proposition 2
It holds Φ=0 for h≤0.
Proof
As the generalized inverse of \(\nabla _{\boldsymbol {\rho \rho }}^{2} f\) is given by
if the eigenvalues (19) are non-negative, i.e., if h≤0, it holds
where we used †: \(\left (\nabla _{\boldsymbol {\rho \rho }}^{2} f\right)\left (\nabla _{\boldsymbol {\rho \rho }}^{2} f\right)^{g} = \frac {1}{2}\boldsymbol {\Psi }\) and ‡: \( \frac {1}{2} \boldsymbol {\Psi }\left (\nabla _{\boldsymbol {\rho }} d^{2}\right) = \left (\nabla _{\boldsymbol {\rho }} d^{2}\right)\). □
Proposition 3
Schur matrix S is given by:
Proof
Using the facts
it holds
and expanding \(\nabla _{x\thinspace x}^{2} f\) yields
which concludes the proof. □
Proposition 4
Schur matrix S is negative semi-definite for h≤0.
Proof
Using the fact that a matrix M is negative semi-definite iff \(\boldsymbol {z}^{\intercal } \boldsymbol {M \thinspace z}\leq 0\) for all \(\boldsymbol {z}\in \mathbb {R}^{n}, \boldsymbol {z}\neq \mathbf {0}\), we obtain with Proposition 3 for the corresponding term of the Schur matrix:
After several algebraic steps, we find that the inner bracket is non-positive whenever q>0 and h≤0. Consequently, we have for the relevant case q>0: \(\boldsymbol {z}^{\intercal } \boldsymbol {S \thinspace z} \leq 0\) if h≤0. □
9 Appendix 3: Similarities between the gradients of (5a) and (7a)
In this section, we analyze the similarities between the gradients of (5a), which is rewritten as
and (7a), which is rewritten as
where (x)∘2 denotes the Hadamard exponential, i.e., the element-wise exponential of the vector x; \(\boldsymbol {w} = \left (\mathcal {W}_{A}\left (e_{ij}^{1}\right), \ldots, \mathcal {W}_{A}\left (e_{ij}^{K}\right) \right)\); and ε denotes the error due to measurement noise.
The partial derivatives of (31) are given by
where w∈=w+ε and d=d(ρ).
Similarly, the following expressions hold for (32):
Consequently, the gradients of h(·) and g(·) are simultaneously vanishing with respect to x (cf. Item 1) and ρ (cf. Item 2) if and only if
-
1.
\(\boldsymbol {w}^{\intercal }_\in \boldsymbol {x} = d \quad \Leftrightarrow \quad \left (\boldsymbol {w}^{\circ 2}_\in \right)^{\intercal }\boldsymbol {x} = d^{2}\label {ep1}\) and
-
2.
\( \boldsymbol {w}^{\intercal }_\in \boldsymbol {x} = d\;\vee \nabla _{\boldsymbol {p}} d = \mathbf {0} \) \( \quad \quad \Leftrightarrow \left (\boldsymbol {w}^{\circ 2}_\in \right)^{\intercal }\boldsymbol {x} = d^{2}\;\vee \;\nabla _{\boldsymbol {p}} d=\mathbf {0}\;\vee \;d=0. \)
Because w≥0, w∈≥0, d>0, and w≠0 and if x∈{0,1}n and \(\mathbf {1}_{n}^{\intercal } \boldsymbol {x} =1\), the gradients of h(·) and g(·) are simultaneously vanishing if and only if \(\boldsymbol {w}^{\intercal }_{\in } \boldsymbol {x} = d\).
Consequently, only the relaxation on the domain of x (cf. (7b)) leads to different extrema of the two associated optimization problems.
Notes
Henceforth, the wireless sensor motes are also denoted as agents.
In addition, a shell that is sufficiently robust to withstand pressure levels of up to 6MPa is required [30].
The general principles and methods introduced in this work can also be easily extended to other measurement models, such as those assuming multiplicative noise.
The authors of [1] showed that it can take up to 48h for an agent to pass through the environment.
Here, we consider only strictly parallel edges; i.e., anti-parallel edges are disregarded.
E.g., for the case in which the sources or agents are actively sending their signals, whereas the stations or beacons are passive (listening only).
In this case, the stations or beacons are sending signals, whereas the sources or agents are passive, in the sense that they simply reflect these signals. The time of flight between the transmission of a pulse and the reception of a reflection is then measured.
Abbreviations
- ID:
-
Identification sequence
- JLTAP:
-
Joint localization and transmit ambiguity resolution problem
- MSL:
-
Multiple source localization
- MINLP:
-
Mixed-integer nonlinear programming
- MMSE:
-
Minimum mean square error
- ML:
-
Maximum likelihood
- RMSE:
-
Root mean square error SN: Serial number
- TA:
-
Transmit ambiguity
- TOA:
-
Time-of-arrival
References
E Talnishnikh, J van Pol, HJ Wörtche, in Intelligent Environmental Sensing. Smart Sensors, Measurement and Instrumentation, vol.13, ed. by H Leung, S Chandra Mukhopadhyay. Micro motes: a highly penetrating probe for inaccessible environments (SpringerCham, 2015), pp. 33–49.
Phoenix Project: EU Horizon 2020 FET-Open Project. http://www.phoenix-project.e. and http://cordis.europa.eu/project/rcn/196968_en.html. Accessed 31 Oct 2017.
CM Istchenko, ID Gates, Well/wormhole model of cold heavy-oil production with sand. Soc. Petroleum Eng. J.260–269 (2014). https://doi.org/10.2118/150633-PA.
S Bhattacharjee, Oil sands: a bridge between conventional petroleum and a sustainable energy future. http://www.oilsands.ualberta.ca/wqm/wp-content/uploads/2010/09/Basu_BookChapter_Subir_Bhattacharjee_June2010.pdf. Accessed 15 May 2017.
A Hales, G Quarini, G Hilton, L Jones, E Lucas, D McBryde, X Yun, The effect of salinity and temperature on electromagnetic wave attenuation in brine. Int. J. Refrig.51:, 161–168 (2015). https://doi.org/10.1016/j.ijrefrig.2014.11.013.
H Shen, Z Ding, S Dasgupta, C Zhao, Multiple source localization in wireless sensor networks based on time of arrival measurement. IEEE Trans. Signal Process.62(8), 1938–1949 (2014). https://doi.org/10.1109/TSP.2014.2304433.
S Venkateswaran, U Madhow, Localizing multiple events using times of arrival: a parallelized, hierarchical approach to the association problem. IEEE Trans. Signal Process.60(10), 5464–5477 (2012). https://doi.org/10.1109/TSP.2012.2205919.
Y Lee, TS Wada, BH Juang, in 2010 IEEE International Conference on Acoustics, Speech and Signal Processing. Multiple acoustic source localization based on multiple hypotheses testing using particle approach, (2010), pp. 2722–2725. https://doi.org/10.1109/ICASSP.2010.5496229.
E Duisterwinkel, L Demi, G Dubbelman, E Talnishnikh, HJ Wörtche, JW Bergmans, in Proc. Meetings Acoust., 20. Environment mapping and localization with an uncontrolled swarm of ultrasound sensor motes (Acoustical Society of AmericaSan Francisco, 2014).
S Schlupkothen, G Ascheid, in 2015 14th Annual Mediterranean Ad Hoc Networking Workshop (MED-HOC-NET) (Med-Hoc-Net’15). Localization of wireless sensor networks with concurrently used identification sequences (Vilamoura, 2015), pp. 1–7. https://doi.org/10.1109/MedHocNet.2015.7173166.
S Schlupkothen, G Ascheid, in 2016 IEEE International Conference on Wireless for Space and Extreme Environments (WiSEE) (WiSEE’16). Joint localization and transmit-ambiguity resolution for ultra-low energy wireless sensors (IEEEAachen, 2016).
S Schlupkothen, B Prasse, G Ascheid, in 2016 Mediterranean Ad Hoc Networking Workshop (Med-Hoc-Net). A dynamic programming algorithm for resolving transmit-ambiguities in the localization of wsn (IEEEVilanova i la Geltru, 2016), pp. 1–8. https://doi.org/10.1109/MedHocNet.2016.7528420.
EHA Duisterwinkel, G Dubbelman, L Demi, E Talnishnikh, JWM Bergmans, HJ Wörtche, in 2016 IEEE Symposium Series on Computational Intelligence (SSCI). Mapping swarms of resource-limited sensor motes: solely using distance measurements and non-unique identifiers (IEEEAthens, 2016), pp. 1–8. https://doi.org/10.1109/SSCI.2016.7849992.
CA Floudas, PM Pardalos, Encyclopedia of optimization. Encyclopedia of optimization (Springer, Secaucus, 2008).
J Aspnes, D Goldenberg, YR Yang, in Algorithmic Aspects of Wireless Sensor Networks, ed. by SE Nikoletseas, JDP Rolim. On the computational complexity of sensor network localization (SpringerBerlin, 2004), pp. 32–44.
P Biswas, Y Ye, in Information Processing in Sensor Networks, 2004. IPSN 2004. Third International Symposium On. Semidefinite programming for ad hoc wireless sensor network localization (ACMNew York, 2004), pp. 46–54. https://doi.org/10.1109/IPSN.2004.1307322.
AM-C So, Y Ye, in Proceedings of the Sixteenth Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), 2005. Theory of semidefinite programming for sensor network localization (Society for Industrial and Applied MathematicsPhiladelphia, 2005), pp. 405–414.
Z Wang, S Zheng, S Boyd, Y Ye, Further relaxations of the sdp approach to sensor network localization. Technical report (2006).
P Biswas, T-C Lian, T-C Wang, Y Ye, Semidefinite programming based algorithms for sensor network localization. ACM Trans. Sen. Netw.2(2), 188–220 (2006). https://doi.org/10.1145/1149283.1149286.
P Biswas, T-C Liang, K-C Toh, Y Ye, T-C Wang, Semidefinite programming approaches for sensor network localization with noisy distance measurements. IEEE Transactions on Automation Science and Engineering. 3(4), 360–371 (2006). https://doi.org/10.1109/TASE.2006.877401.
P Tseng, Second-order cone programming relaxation of sensor network localization. SIAM J. Optimization. 18(1), 156–185 (2007). https://doi.org/10.1137/050640308.
KWK Lui, WK Ma, HC So, FKW Chan, Semi-definite programming algorithms for sensor network node localization with uncertainties in anchor positions and/or propagation speed. IEEE Trans. Signal Process.57(2), 752–763 (2009). https://doi.org/10.1109/TSP.2008.2007916.
FKW Chan, HC So, Efficient weighted multidimensional scaling for wireless sensor network localization. IEEE Trans. Signal Process.57(11), 4548–4553 (2009). https://doi.org/10.1109/TSP.2009.2024869.
L Nguyen, S Kim, B Shim, in 2016 Information Theory and Applications Workshop (ITA). Localization in internet of things network: matrix completion approach (IEEELa Jolla, 2016), pp. 1–4. https://doi.org/10.1109/ITA.2016.7888154.
GC Calafiore, L Carlone, M Wei, in 18th Mediterranean Conference on Control Automation (MED), 2010. Position estimation from relative distance measurements in multi-agents formations (IEEEMarrakech, 2010), pp. 148–153. https://doi.org/10.1109/MED.2010.5547601.
BD Anderson, PN Belhumeur, T Eren, DK Goldenberg, AS Morse, W Whiteley, YR Yang, Graphical properties of easily localizable sensor networks. Wirel. Netw.15(2), 177–191 (2009). https://doi.org/10.1007/s11276-007-0034-9.
J Aspnes, T Eren, DK Goldenberg, AS Morse, W Whiteley, YR Yang, BDO Anderson, PN Belhumeur, A theory of network localization. IEEE Transactions on Mobile Computing. 5(12), 1663–1678 (2006). https://doi.org/10.1109/TMC.2006.174.
S Schlupkothen, G Dartmann, G Ascheid, A novel low-complexity numerical localization method for dynamic wireless sensor networks. Signal Process. IEEE Trans.PP(99), 1–1 (2015). https://doi.org/10.1109/TSP.2015.2422685.
M Tawarmalani, NV Sahinidis, A polyhedral branch-and-cut approach to global optimization. Math. Program.103:, 225–249 (2005).
MB Dusseault, CHOPS—Cold Heavy Oil Production with Sand in the Canadian heavy oil industry (2004). https://open.alberta.ca/dataset/2815953. Accessed 31 Oct 2017.
T Öncan, R Zhang, AP Punnen, The minimum cost perfect matching problem with conflict pair constraints. Comput. Oper. Res.40(4), 920–930 (2013).
A Darmann, U Pferschy, J Schauer, GJ Woeginger, Paths, trees and matchings under disjunctive constraints. Discrete Appl. Math.159(16), 1726–1735 (2011). 8th Cologne/Twente Workshop on Graphs and Combinatorial Optimization (CTW 2009).
EW Weisstein, Perfect matching. From MathWorld—A Wolfram Web Resource (2016). http://mathworld.wolfram.com/PerfectMatching.html. Last visited on 08/30/2016.
F Zhang, The Schur complement and its applications. Numerical Methods and Algorithms (Springer, Boston, 2005).
Acknowledgements
We gratefully acknowledge the computational resources provided by the RWTH Compute Cluster from RWTH Aachen University under project RWTH0118.
Funding
This project has received funding from the European Union’s Horizon 2020 research and innovation program under grant agreement No. 665347.
Author information
Authors and Affiliations
Contributions
SS performed the simulations and wrote the majority of the manuscript. GA initiated the research and also commented on the manuscript. Both authors read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no competing interests.
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Schlupkothen, S., Ascheid, G. Localization of ambiguously identifiable wireless agents: complexity analysis and efficient algorithms. EURASIP J. Adv. Signal Process. 2018, 30 (2018). https://doi.org/10.1186/s13634-018-0548-6
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/s13634-018-0548-6